Do What You Say: Steering Vision-Language-Action Models via Runtime Reasoning-Action Alignment Verification
作者: Yilin Wu, Anqi Li, Tucker Hermans, Fabio Ramos, Andrea Bajcsy, Claudia Pérez-D'Arpino
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-18 (更新: 2026-01-14)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出运行时推理-行动对齐验证方法,提升VLA模型在机器人任务中的泛化性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人指令跟随 运行时策略指导 推理-行动对齐 分布外泛化
📋 核心要点
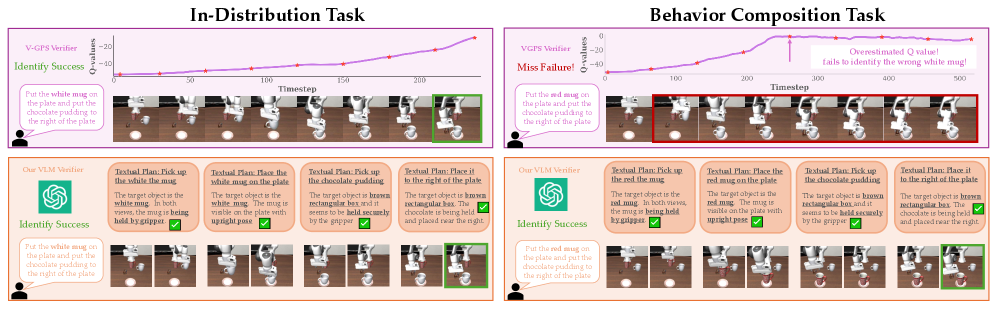
- 现有VLA模型在分布外场景中,即使文本计划正确,执行的动作也可能与计划不符,缺乏具身化的CoT忠实性。
- 提出一种无需训练的运行时策略指导方法,通过验证动作序列与文本计划的对齐程度来选择最佳动作。
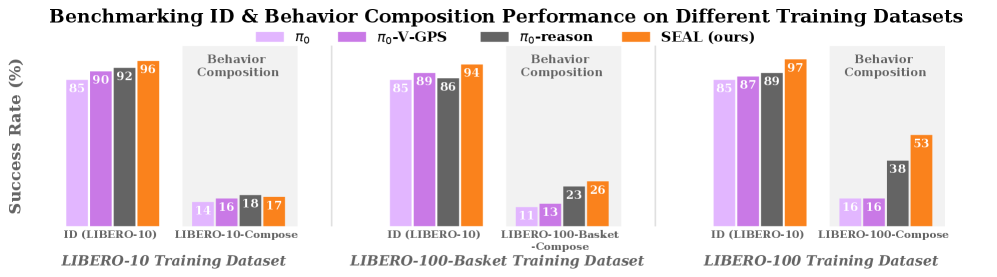
- 实验表明,该方法显著提升了VLA模型在分布外场景中的鲁棒性,并在行为组合任务上取得了高达15%的性能提升。
📝 摘要(中文)
本文针对推理视觉-语言-动作(VLA)模型在机器人指令跟随任务中,即使生成了正确的文本计划,实际执行的动作也可能与计划不符的问题,提出了运行时策略指导方法,以实现推理-行动对齐。该方法通过对同一模型采样多个候选动作序列,利用模拟预测其结果,并使用预训练的视觉-语言模型(VLM)选择与VLA文本计划最匹配的序列。这种方法将VLA模型固有的动作多样性从错误来源转化为优势,提高了模型对语义和视觉分布外扰动的鲁棒性,并实现了新的行为组合,无需重新训练。此外,本文还贡献了一个推理标注的LIBERO-100扩展,以及为分布外评估定制的环境变体。实验表明,该方法在行为组合任务上比现有方法提高了高达15%的性能,并能随着计算和数据多样性的增加而扩展。
🔬 方法详解
问题定义:论文旨在解决推理视觉-语言-动作(VLA)模型在机器人指令跟随任务中,生成的动作与文本计划不一致的问题,尤其是在分布外(OOD)场景下。现有方法虽然通过生成逐步的文本计划来模仿语言模型的思维链(CoT)推理,但仍然无法保证动作的执行能够忠实地反映文本计划的意图。这种不一致性导致模型在面对新的、未知的环境或指令时表现不佳。
核心思路:论文的核心思路是引入一个运行时验证机制,用于评估候选动作序列与VLA模型生成的文本计划的对齐程度。通过对同一VLA模型采样多个可能的动作序列,并预测每个序列的执行结果,然后利用预训练的视觉-语言模型(VLM)来判断哪个结果与文本计划最为一致。选择与文本计划最匹配的动作序列进行执行,从而提高动作的可靠性和准确性。
技术框架:该框架主要包含以下几个模块:1) VLA模型:作为基础模型,负责接收视觉输入和语言指令,并生成逐步的文本计划和候选动作序列。2) 动作采样器:从VLA模型中采样多个候选动作序列,以探索不同的执行路径。3) 模拟器:用于模拟每个候选动作序列的执行结果,生成相应的视觉状态。4) VLM评估器:使用预训练的VLM模型,评估模拟结果与VLA模型生成的文本计划的对齐程度,输出对齐分数。5) 策略选择器:根据VLM评估器的输出,选择对齐分数最高的动作序列进行执行。
关键创新:该方法最重要的创新点在于提出了一个无需重新训练的运行时策略指导框架,通过利用预训练的VLM模型来验证动作序列与文本计划的对齐程度,从而提高了VLA模型在分布外场景下的鲁棒性。与现有方法相比,该方法不需要额外的训练数据或模型微调,可以直接应用于现有的VLA模型,并且能够有效地利用VLA模型固有的动作多样性。
关键设计:关键设计包括:1) 动作采样策略:如何有效地从VLA模型中采样多样化的候选动作序列。2) 模拟器的选择:选择合适的模拟器来准确地预测动作序列的执行结果。3) VLM评估指标:设计合适的VLM评估指标来衡量模拟结果与文本计划的对齐程度,例如使用文本蕴含(textual entailment)或视觉问答(visual question answering)等技术。4) 对齐分数的融合:如何将VLM评估器输出的对齐分数与VLA模型的置信度进行融合,以获得更准确的动作选择。
🖼️ 关键图片
📊 实验亮点
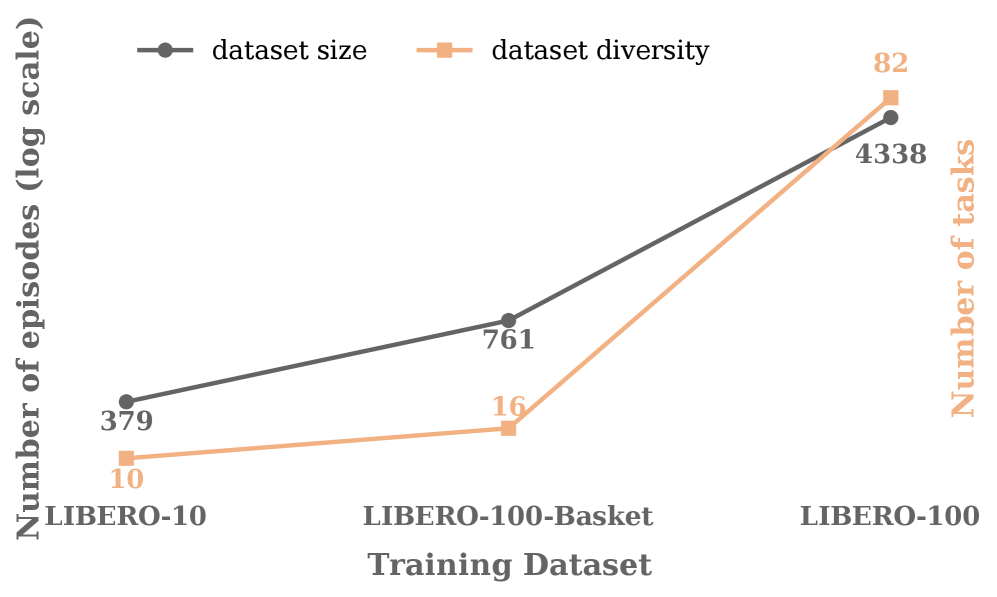
实验结果表明,该方法在行为组合任务上比现有方法提高了高达15%的性能。此外,该方法能够有效地提高VLA模型在分布外场景下的鲁棒性,使其能够更好地应对语义和视觉上的扰动。实验还证明,该方法的性能可以随着计算资源和数据多样性的增加而扩展,具有良好的可扩展性。
🎯 应用场景
该研究成果可广泛应用于机器人指令跟随、自动化任务执行、智能家居等领域。通过提高机器人对指令的理解和执行能力,可以实现更智能、更可靠的自动化服务。例如,在复杂环境中执行清洁、搬运等任务,或在智能家居中根据用户的语音指令控制家电设备。该方法还可应用于自动驾驶领域,提高车辆对复杂交通场景的理解和应对能力。
📄 摘要(原文)
Reasoning Vision Language Action (VLA) models improve robotic instruction-following by generating step-by-step textual plans before low-level actions, an approach inspired by Chain-of-Thought (CoT) reasoning in language models. Yet even with a correct textual plan, the generated actions can still miss the intended outcomes in the plan, especially in out-of-distribution (OOD) scenarios. We formalize this phenomenon as a lack of embodied CoT faithfulness, and introduce a training-free, runtime policy steering method for reasoning-action alignment. Given a reasoning VLA's intermediate textual plan, our framework samples multiple candidate action sequences from the same model, predicts their outcomes via simulation, and uses a pre-trained Vision-Language Model (VLM) to select the sequence whose outcome best aligns with the VLA's own textual plan. Only executing action sequences that align with the textual reasoning turns our base VLA's natural action diversity from a source of error into a strength, boosting robustness to semantic and visual OOD perturbations and enabling novel behavior composition without costly re-training. We also contribute a reasoning-annotated extension of LIBERO-100, environment variations tailored for OOD evaluation, and demonstrate up to 15% performance gain over prior work on behavior composition tasks and scales with compute and data diversity. Project Website at: https://yilin-wu98.github.io/steering-reasoning-vla/