NEBULA: Do We Evaluate Vision-Language-Action Agents Correctly?
作者: Jierui Peng, Yanyan Zhang, Yicheng Duan, Tuo Liang, Vipin Chaudhary, Yu Yin
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-10-17 (更新: 2025-10-21)
备注: Homepage: https://vulab-ai.github.io/NEBULA-Alpha/
💡 一句话要点
NEBULA:用于诊断和可复现评估的视觉-语言-动作智能体统一生态系统
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作智能体 具身智能 机器人操作 评估平台 鲁棒性测试
📋 核心要点
- 现有VLA智能体的评估方法依赖于粗粒度的成功指标,缺乏对智能体技能的精细诊断和鲁棒性评估。
- NEBULA通过统一的生态系统和双轴评估协议,实现了对VLA智能体的诊断性和可复现性评估。
- 实验表明,使用NEBULA可以发现现有VLA智能体在空间推理和动态适应等关键能力上的不足。
📝 摘要(中文)
视觉-语言-动作(VLA)智能体的评估受到粗糙的、仅关注最终任务成功的指标的阻碍,这些指标无法提供精确的技能诊断或衡量对真实世界扰动的鲁棒性。数据分散的现状加剧了这一挑战,阻碍了可复现的研究和通用模型的开发。为了解决这些限制,我们引入了NEBULA,一个用于单臂操作的统一生态系统,能够进行诊断性和可复现的评估。NEBULA采用了一种新颖的双轴评估协议,该协议结合了用于精确技能诊断的细粒度能力测试和用于衡量鲁棒性的系统性压力测试。提供了一个标准化的API和一个大规模的聚合数据集,以减少碎片化并支持跨数据集训练和公平比较。使用NEBULA,我们证明了表现最佳的VLA在空间推理和动态适应等关键能力方面存在不足,而这些不足通常被传统的最终任务成功指标所掩盖。通过衡量智能体能做什么以及何时可靠地做到,NEBULA为鲁棒的、通用的具身智能体提供了一个实际的基础。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)智能体的评估方法主要依赖于最终任务的成功率,这种粗粒度的评估方式无法准确诊断智能体的技能缺陷,也难以衡量其在真实世界扰动下的鲁棒性。此外,VLA领域的数据集分散,缺乏统一的标准和API,阻碍了跨数据集的训练和公平比较,不利于通用VLA智能体的研究和发展。
核心思路:NEBULA的核心思路是构建一个统一的、可控的评估环境,并设计一种双轴评估协议,从能力和鲁棒性两个维度对VLA智能体进行全面评估。通过细粒度的能力测试诊断智能体的具体技能,通过系统性的压力测试评估智能体在各种扰动下的表现。同时,提供标准化的API和大规模聚合数据集,方便研究人员进行实验和比较。
技术框架:NEBULA生态系统主要包含以下几个部分:1) 标准化的API,用于与不同的VLA智能体进行交互;2) 大规模聚合数据集,包含多个单臂操作任务的数据;3) 双轴评估协议,包括细粒度能力测试和系统性压力测试;4) 评估指标,用于量化智能体的性能。整个评估流程如下:首先,VLA智能体通过API与NEBULA环境交互;然后,NEBULA根据双轴评估协议,对智能体进行能力测试和压力测试;最后,根据评估指标,生成智能体的性能报告。
关键创新:NEBULA的关键创新在于其双轴评估协议,该协议能够同时评估VLA智能体的能力和鲁棒性。传统的评估方法通常只关注最终任务的成功率,而忽略了智能体在执行任务过程中可能存在的缺陷。NEBULA的双轴评估协议能够更全面、更准确地评估VLA智能体的性能,为智能体的改进提供更有效的指导。
关键设计:NEBULA的双轴评估协议包含以下关键设计:1) 细粒度能力测试:针对VLA智能体的不同技能(如空间推理、动态适应等)设计专门的测试用例,并定义相应的评估指标;2) 系统性压力测试:模拟真实世界中可能出现的各种扰动(如光照变化、物体遮挡、噪声干扰等),并评估智能体在这些扰动下的表现;3) 标准化的API:提供统一的接口,方便与不同的VLA智能体进行交互,并支持跨数据集的训练和评估。
🖼️ 关键图片


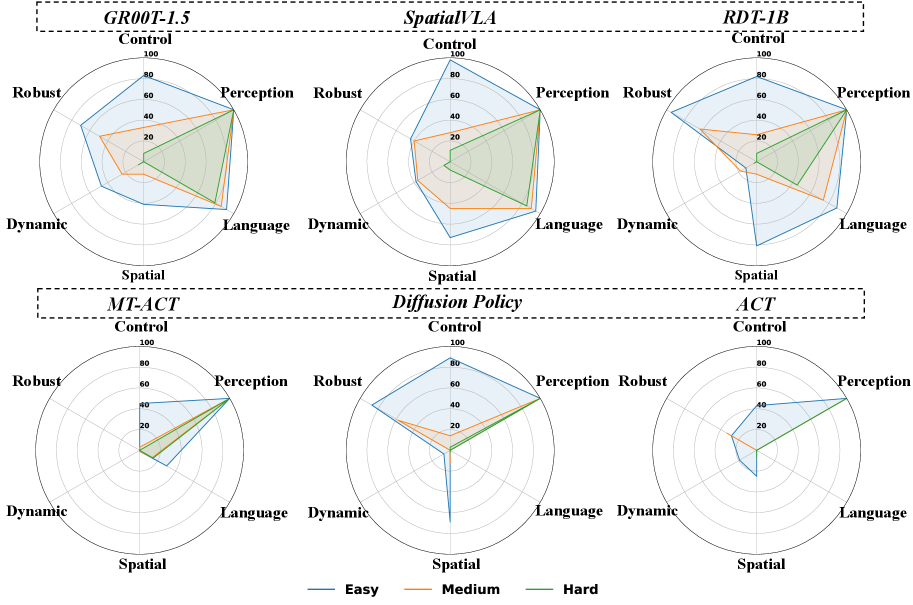
📊 实验亮点
使用NEBULA对现有VLA智能体进行评估,发现它们在空间推理和动态适应等关键能力上存在显著不足,这些不足在传统的最终任务成功率评估中往往被忽略。例如,在空间推理测试中,一些表现最佳的VLA智能体的成功率仅为50%左右,远低于人类水平。这表明,现有VLA智能体在理解和利用空间信息方面仍有很大的提升空间。
🎯 应用场景
NEBULA的研究成果可以应用于机器人操作、智能制造、家庭服务等领域。通过更精确地评估和诊断VLA智能体的能力,可以促进更鲁棒、更可靠的智能体设计,从而提高机器人在复杂环境中的适应性和实用性。此外,NEBULA提供的统一评估平台和数据集,也将加速VLA领域的研究进展。
📄 摘要(原文)
The evaluation of Vision-Language-Action (VLA) agents is hindered by the coarse, end-task success metric that fails to provide precise skill diagnosis or measure robustness to real-world perturbations. This challenge is exacerbated by a fragmented data landscape that impedes reproducible research and the development of generalist models. To address these limitations, we introduce NEBULA, a unified ecosystem for single-arm manipulation that enables diagnostic and reproducible evaluation. NEBULA features a novel dual-axis evaluation protocol that combines fine-grained capability tests for precise skill diagnosis with systematic stress tests that measure robustness. A standardized API and a large-scale, aggregated dataset are provided to reduce fragmentation and support cross-dataset training and fair comparison. Using NEBULA, we demonstrate that top-performing VLAs struggle with key capabilities such as spatial reasoning and dynamic adaptation, which are consistently obscured by conventional end-task success metrics. By measuring both what an agent can do and when it does so reliably, NEBULA provides a practical foundation for robust, general-purpose embodied agents.