HEADER: Hierarchical Robot Exploration via Attention-Based Deep Reinforcement Learning with Expert-Guided Reward
作者: Yuhong Cao, Yizhuo Wang, Jingsong Liang, Shuhao Liao, Yifeng Zhang, Peizhuo Li, Guillaume Sartoretti
分类: cs.RO
发布日期: 2025-10-17
💡 一句话要点
HEADER:基于注意力深度强化学习和专家引导奖励的分层机器人探索方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人探索 自主导航 深度强化学习 注意力机制 分层图 环境建模
📋 核心要点
- 现有自主探索方法在大规模环境中效率较低,难以兼顾局部细节和全局信息。
- HEADER利用分层图表示环境,结合注意力机制,使机器人能够同时考虑局部和全局信息进行探索。
- 通过引入无参数的特权奖励,避免了手工设计奖励带来的偏差,显著提升了探索效率,最高达20%。
📝 摘要(中文)
本文在环境规模和探索效率方面,突破了基于学习的自主机器人探索方法的界限。我们提出了HEADER,一种基于注意力的强化学习方法,它利用分层图实现在大规模环境中进行高效探索。HEADER遵循现有的传统方法,为机器人置信度/地图构建分层表示,并进一步设计了一种新颖的基于社区的算法来构建和更新全局图,该算法保持完全增量式、形状自适应,并以线性复杂度运行。我们的规划器基于注意力网络,能够精细地推理局部范围内的附近置信度,同时粗略地利用全局范围内的远距离信息,从而做出考虑多尺度空间依赖性的最佳视点决策。除了新颖的地图表示之外,我们还引入了一种无参数的特权奖励,通过避免手工设计的奖励塑造所造成的训练目标偏差,显著提高了模型性能并产生了接近最优的探索行为。在具有挑战性的大规模探索模拟场景中,HEADER展示了比大多数现有学习和非学习方法更好的可扩展性,同时在探索效率方面比最先进的基线提高了高达20%。我们还在硬件上部署了HEADER,并在复杂的、大规模的真实场景中对其进行了验证,包括一个300m*230m的校园环境。
🔬 方法详解
问题定义:自主机器人探索旨在让机器人在未知环境中高效地构建地图。现有方法在大规模环境中面临挑战,难以平衡探索效率和计算复杂度。传统方法依赖于启发式策略,缺乏适应性;基于学习的方法难以处理大规模环境,且奖励函数的设计往往存在偏差,影响探索效果。
核心思路:HEADER的核心思路是利用分层图结构表示环境,并结合注意力机制,使机器人能够同时考虑局部细节和全局信息。通过分层结构,降低了计算复杂度,提高了可扩展性。注意力机制则帮助机器人关注重要的区域,提高探索效率。此外,引入无参数的特权奖励,避免了手工设计奖励带来的偏差。
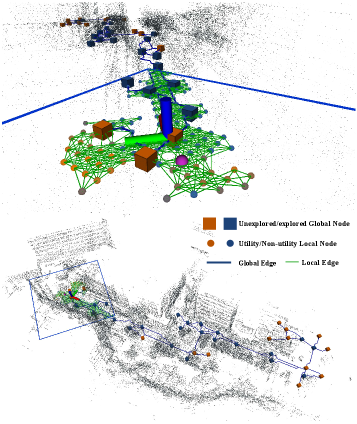
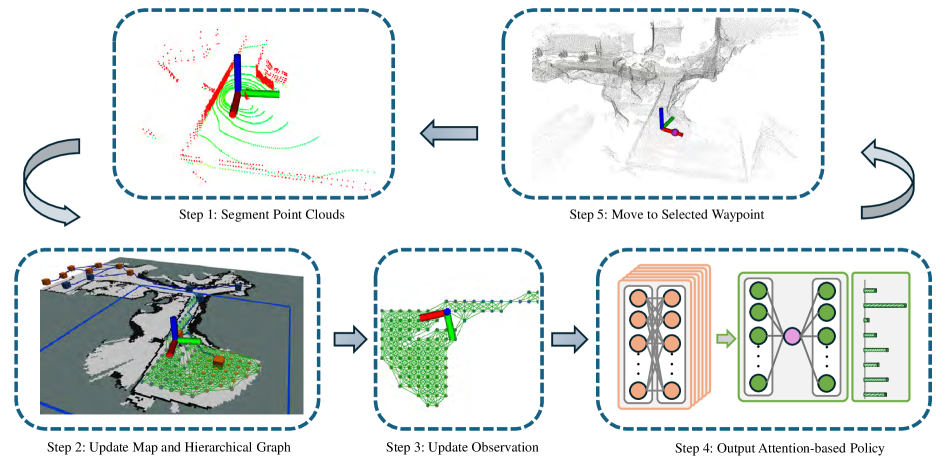
技术框架:HEADER的整体框架包括以下几个主要模块:1) 分层图构建模块:利用社区检测算法构建全局图,并保持增量更新和形状自适应。2) 注意力网络规划器:基于注意力机制,融合局部和全局信息,预测下一个最佳视点。3) 奖励函数设计:采用无参数的特权奖励,直接利用环境信息,避免奖励塑造带来的偏差。
关键创新:HEADER的关键创新在于以下几点:1) 新颖的全局图构建算法:该算法能够以线性复杂度构建和更新全局图,保证了算法的可扩展性。2) 基于注意力的规划器:该规划器能够同时考虑局部和全局信息,提高了探索效率。3) 无参数的特权奖励:该奖励函数避免了手工设计奖励带来的偏差,提高了模型性能。与现有方法相比,HEADER能够更好地处理大规模环境,并取得更高的探索效率。
关键设计:全局图的构建采用基于社区的算法,保证了增量更新和形状自适应。注意力网络采用Transformer结构,能够有效地融合局部和全局信息。奖励函数直接利用环境信息,例如未探索区域的面积,避免了手工设计奖励带来的偏差。具体参数设置在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
在模拟实验中,HEADER在探索效率方面比最先进的基线提高了高达20%,并展示了更好的可扩展性。在真实的校园环境中,HEADER也成功地完成了自主探索任务,验证了其在实际应用中的可行性。这些实验结果表明,HEADER是一种高效且可靠的自主探索方法。
🎯 应用场景
HEADER具有广泛的应用前景,可用于自主导航、环境监测、灾后救援、考古勘探等领域。通过高效的自主探索,机器人可以在未知环境中快速构建地图,为后续任务提供支持。该研究成果有助于提升机器人的自主性和适应性,使其在复杂环境中发挥更大的作用。
📄 摘要(原文)
This work pushes the boundaries of learning-based methods in autonomous robot exploration in terms of environmental scale and exploration efficiency. We present HEADER, an attention-based reinforcement learning approach with hierarchical graphs for efficient exploration in large-scale environments. HEADER follows existing conventional methods to construct hierarchical representations for the robot belief/map, but further designs a novel community-based algorithm to construct and update a global graph, which remains fully incremental, shape-adaptive, and operates with linear complexity. Building upon attention-based networks, our planner finely reasons about the nearby belief within the local range while coarsely leveraging distant information at the global scale, enabling next-best-viewpoint decisions that consider multi-scale spatial dependencies. Beyond novel map representation, we introduce a parameter-free privileged reward that significantly improves model performance and produces near-optimal exploration behaviors, by avoiding training objective bias caused by handcrafted reward shaping. In simulated challenging, large-scale exploration scenarios, HEADER demonstrates better scalability than most existing learning and non-learning methods, while achieving a significant improvement in exploration efficiency (up to 20%) over state-of-the-art baselines. We also deploy HEADER on hardware and validate it in complex, large-scale real-life scenarios, including a 300m*230m campus environment.