Adaptive Legged Locomotion via Online Learning for Model Predictive Control
作者: Hongyu Zhou, Xiaoyu Zhang, Vasileios Tzoumas
分类: cs.RO, eess.SY
发布日期: 2025-10-17 (更新: 2025-11-30)
备注: IEEE Robotics and Automation Letters
💡 一句话要点
提出基于在线学习模型预测控制的自适应腿式机器人运动算法,解决未知扰动下的复杂任务。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 腿式机器人 模型预测控制 在线学习 残差动力学 自适应控制
📋 核心要点
- 现有腿式机器人控制方法难以应对未知扰动,如有效载荷变化和复杂地形,导致控制性能下降。
- 该论文提出在线学习残差动力学的方法,利用随机傅里叶特征近似残差,并结合模型预测控制实现自适应运动。
- 在Gazebo和MuJoCo仿真中验证了算法的有效性,包括在复杂地形和存在未知扰动的情况下,机器人能够跟踪参考轨迹。
📝 摘要(中文)
本文提出了一种基于在线学习和模型预测控制的自适应腿式机器人运动算法。该算法由两个相互作用的模块组成:模型预测控制(MPC)和残差动力学的在线学习。残差动力学可以表示建模误差和外部扰动。我们的动机是四足机器人在自主执行复杂任务时,能够应对现实世界中未知的扰动,例如未知的有效载荷和不平坦的地形。该算法使用随机傅里叶特征来近似再生核希尔伯特空间中的残差动力学。然后,它采用基于当前学习到的残差动力学模型的MPC。该模型以自监督的方式在线更新,使用基于最小二乘法的数据,这些数据是在控制四足机器人时收集的。该算法具有次线性动态遗憾,定义为相对于知道残差动力学的最优先知控制器的次优性。我们在Gazebo和MuJoCo模拟中验证了我们的算法,其中四足机器人旨在跟踪参考轨迹。Gazebo模拟包括高达12g的恒定未知外力(g是重力矢量),在平坦地形、倾斜20度的斜坡地形和高度变化为0.25米的粗糙地形中。MuJoCo模拟包括高达8公斤的有效载荷的时变未知扰动和平坦地形中时变的地面摩擦系数。
🔬 方法详解
问题定义:腿式机器人需要在未知扰动(如未知的有效载荷、不平坦的地形、时变的地面摩擦系数等)下实现精确的运动控制。传统的模型预测控制方法依赖于精确的动力学模型,当模型存在误差或受到外部扰动时,控制性能会显著下降。现有方法难以在未知环境中保持鲁棒性和适应性。
核心思路:该论文的核心思路是通过在线学习来估计残差动力学,从而补偿模型误差和外部扰动。通过不断地从实际控制过程中收集数据,并利用这些数据来更新残差动力学模型,使得机器人能够逐渐适应未知的环境和扰动。这种自适应的方法能够提高机器人在复杂环境中的运动控制性能。
技术框架:该算法包含两个主要模块:模型预测控制(MPC)和残差动力学的在线学习。首先,使用随机傅里叶特征来近似残差动力学,将其表示在再生核希尔伯特空间中。然后,基于当前学习到的残差动力学模型,使用MPC来计算控制指令。在控制过程中,收集机器人的状态和控制输入数据,并使用最小二乘法在线更新残差动力学模型。这两个模块相互作用,不断提高机器人的控制性能。
关键创新:该论文的关键创新在于将在线学习与模型预测控制相结合,实现对残差动力学的自适应估计。与传统的离线学习方法相比,在线学习能够更好地适应环境的变化。此外,使用随机傅里叶特征来近似残差动力学,降低了计算复杂度,使得算法能够实时运行。
关键设计:残差动力学使用随机傅里叶特征进行近似,这涉及到随机傅里叶特征的选取和核函数的选择。在线学习使用最小二乘法进行参数更新,需要选择合适的学习率和正则化参数。MPC的设计需要考虑控制频率、预测时域长度和控制权重等参数。动态遗憾被用作评估算法性能的指标。
🖼️ 关键图片

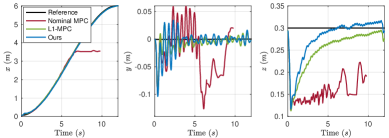
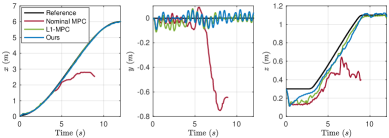
📊 实验亮点
在Gazebo仿真中,该算法能够在高达12g的恒定未知外力下,在平坦、倾斜和粗糙地形中实现稳定的轨迹跟踪。在MuJoCo仿真中,该算法能够在高达8kg的有效载荷和时变地面摩擦系数下实现有效的控制。实验结果表明,该算法能够显著提高腿式机器人在未知扰动下的运动控制性能。
🎯 应用场景
该研究成果可应用于各种腿式机器人的自主导航和操作任务,尤其是在复杂和未知的环境中,如搜救、勘探、物流等。通过自适应地学习环境动力学,机器人能够更好地应对各种挑战,提高任务完成的效率和可靠性。该技术还有潜力应用于其他类型的机器人,如无人机和水下机器人。
📄 摘要(原文)
We provide an algorithm for adaptive legged locomotion via online learning and model predictive control. The algorithm is composed of two interacting modules: model predictive control (MPC) and online learning of residual dynamics. The residual dynamics can represent modeling errors and external disturbances. We are motivated by the future of autonomy where quadrupeds will autonomously perform complex tasks despite real-world unknown uncertainty, such as unknown payload and uneven terrains. The algorithm uses random Fourier features to approximate the residual dynamics in reproducing kernel Hilbert spaces. Then, it employs MPC based on the current learned model of the residual dynamics. The model is updated online in a self-supervised manner using least squares based on the data collected while controlling the quadruped. The algorithm enjoys sublinear \textit{dynamic regret}, defined as the suboptimality against an optimal clairvoyant controller that knows how the residual dynamics. We validate our algorithm in Gazebo and MuJoCo simulations, where the quadruped aims to track reference trajectories. The Gazebo simulations include constant unknown external forces up to $12\boldsymbol{g}$, where $\boldsymbol{g}$ is the gravity vector, in flat terrain, slope terrain with $20\degree$ inclination, and rough terrain with $0.25m$ height variation. The MuJoCo simulations include time-varying unknown disturbances with payload up to $8~kg$ and time-varying ground friction coefficients in flat terrain.