VO-DP: Semantic-Geometric Adaptive Diffusion Policy for Vision-Only Robotic Manipulation
作者: Zehao Ni, Yonghao He, Lingfeng Qian, Jilei Mao, Fa Fu, Wei Sui, Hu Su, Junran Peng, Zhipeng Wang, Bin He
分类: cs.RO, cs.CV, cs.LG
发布日期: 2025-10-17 (更新: 2025-11-03)
💡 一句话要点
提出VO-DP:一种基于视觉的语义-几何自适应扩散策略,用于机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 扩散策略 视觉学习 语义特征 几何特征 模仿学习 预训练模型
📋 核心要点
- 现有机器人操作扩散策略学习主要依赖点云输入,计算成本高,纯视觉方案潜力未被充分挖掘。
- VO-DP利用预训练视觉模型融合语义和几何特征,通过交叉注意力机制提升特征表达能力。
- VO-DP在仿真和真实环境均超越纯视觉基线,真实环境甚至优于点云方法,且鲁棒性更强。
📝 摘要(中文)
本文提出了一种基于视觉的机器人操作扩散策略学习方法(VO-DP)。现有方法大多依赖点云作为输入,并通过点云特征学习构建场景表示,虽然精度高但缺乏对纯视觉方案的深入探索。VO-DP利用预训练的视觉基础模型,有效融合语义和几何特征。具体而言,VO-DP利用VGG的中间特征,结合DINOv2的语义特征和交替注意力模块的几何特征,通过交叉注意力融合,并使用CNN进行空间压缩,形成策略头的输入。实验表明,VO-DP不仅显著优于纯视觉基线DP,而且在仿真和真实世界任务中均表现出与基于点云的方法DP3相当甚至更优的性能。鲁棒性评估也表明VO-DP在颜色、大小、背景和光照变化下保持高度稳定。最后,本文开源了一个基于Accelerate的机器人操作训练库,支持多机多卡并行训练和混合精度训练,兼容DP、DP3和VO-DP等视觉运动策略,并支持RoboTwin模拟器。
🔬 方法详解
问题定义:现有基于扩散策略的机器人操作方法,大多依赖于点云数据作为输入,这限制了其在实际应用中的灵活性和成本。纯视觉方案虽然具有潜力,但缺乏有效的语义和几何信息融合方法,导致性能受限。因此,需要一种能够仅通过视觉输入,实现高性能机器人操作的策略学习方法。
核心思路:VO-DP的核心思路是利用预训练的视觉基础模型,提取图像中的语义和几何特征,并通过自适应的方式进行融合,从而弥补纯视觉方案的信息缺失问题。通过融合语义信息(例如物体类别)和几何信息(例如形状和空间关系),VO-DP能够更准确地理解场景,并生成更有效的操作策略。
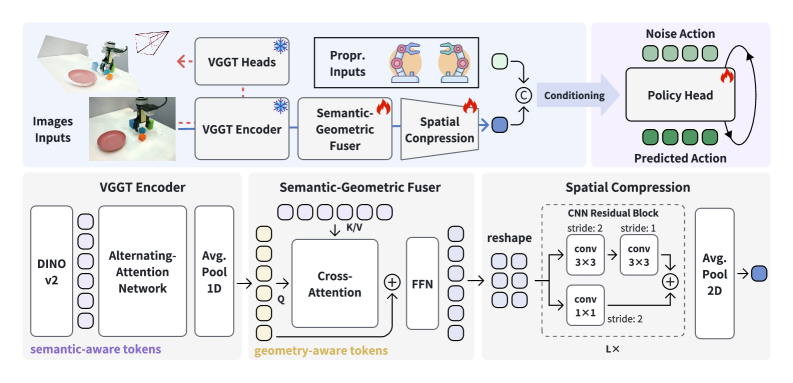
技术框架:VO-DP的整体框架包括以下几个主要模块:1) 特征提取:使用VGG提取图像的中间层特征,作为基础特征表示;2) 语义特征提取:利用DINOv2提取图像的语义特征;3) 几何特征提取:使用交替注意力模块提取图像的几何特征;4) 特征融合:通过交叉注意力机制,将语义特征和几何特征与基础特征进行融合;5) 空间压缩:使用CNN对融合后的特征进行空间压缩,得到策略头的输入;6) 策略头:使用扩散模型生成机器人动作。
关键创新:VO-DP的关键创新在于其语义-几何自适应特征融合机制。通过交叉注意力机制,VO-DP能够根据场景的特点,自适应地调整语义和几何特征的权重,从而实现更有效的特征融合。此外,VO-DP还利用了预训练的视觉基础模型,从而避免了从头开始训练视觉特征提取器的需要,大大降低了训练成本。
关键设计:VO-DP的关键设计包括:1) 使用VGG的中间层特征,以保留更多的空间信息;2) 使用DINOv2提取语义特征,DINOv2是一种自监督学习的视觉模型,能够提取丰富的语义信息;3) 使用交替注意力模块提取几何特征,交替注意力模块能够有效地捕捉图像中的空间关系;4) 使用交叉注意力机制进行特征融合,交叉注意力机制能够自适应地调整语义和几何特征的权重;5) 使用CNN进行空间压缩,CNN能够有效地降低特征维度,并保留重要的空间信息。
🖼️ 关键图片


📊 实验亮点
VO-DP在仿真任务中取得了与基于点云的DP3相当的性能(64.6% vs 64.0%),远高于纯视觉基线DP(34.8%)。更重要的是,在真实世界任务中,VO-DP的成功率达到了87.9%,显著优于DP3(67.5%)和DP(11.2%)。鲁棒性测试表明,VO-DP在颜色、大小、背景和光照变化等条件下均表现出良好的稳定性。
🎯 应用场景
VO-DP在机器人操作领域具有广泛的应用前景,例如:工业自动化、家庭服务机器人、医疗机器人等。它可以应用于各种操作任务,例如:物体抓取、装配、搬运等。VO-DP的纯视觉特性使其更易于部署在实际环境中,降低了对硬件的要求和成本。未来,VO-DP有望成为机器人操作领域的重要技术。
📄 摘要(原文)
In the context of imitation learning, visuomotor-based diffusion policy learning is one of the main directions in robotic manipulation. Most of these approaches rely on point clouds as observation inputs and construct scene representations through point clouds feature learning, which enables them to achieve remarkable accuracy. However, the existing literature lacks an in-depth exploration of vision-only solutions that have significant potential. In this paper, we propose a Vision-Only and single-view Diffusion Policy learning method (VO-DP) that leverages pretrained visual foundation models to achieve effective fusion of semantic and geometric features. We utilize intermediate features from VGGT incorporating semantic features from DINOv2 and geometric features from Alternating Attention blocks. Features are fused via cross-attention and spatially compressed with a CNN to form the input to the policy head. Extensive experiments demonstrate that VO-DP not only outperforms the vision-only baseline DP significantly but also exhibits distinct performance trends against the point cloud-based method DP3: in simulation tasks, VO-DP achieves an average success rate of 64.6% on par with DP3 64.0% and far higher than DP 34.8%, while in real-world tasks, it reaches 87.9%, outperforming both DP3 67.5% and DP 11.2% by a notable margin. Further robustness evaluations confirm that VO-DP remains highly stable under varying conditions including color, size, background, and lighting. Lastly, we open-source a training library for robotic manipulation. Built on Accelerate, this library supports multi-machine and multi-GPU parallel training, as well as mixed precision training. It is compatible with visuomotor policies such as DP, DP3 and VO-DP, and also supports the RoboTwin simulator.