VDRive: Leveraging Reinforced VLA and Diffusion Policy for End-to-end Autonomous Driving
作者: Ziang Guo, Zufeng Zhang
分类: cs.RO
发布日期: 2025-10-17
备注: 1st version
💡 一句话要点
VDRive:利用强化VLA和扩散策略实现端到端自动驾驶
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 端到端学习 视觉语言动作模型 扩散模型 强化学习
📋 核心要点
- 自动驾驶面临动态环境和极端情况的挑战,现有方法在车辆状态理解和决策方面存在不足。
- VDRive通过建模状态-动作映射,并结合VLA的状态理解能力和扩散策略的动作生成能力,实现鲁棒决策。
- 实验结果表明,VDRive在Bench2Drive和nuScenes数据集上取得了领先的性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种用于端到端自动驾驶的新型流程VDRive,它显式地建模了状态-动作映射,以应对动态环境和极端情况对自动驾驶车辆状态理解和决策带来的挑战,从而实现可解释和鲁棒的决策。VDRive利用视觉-语言-动作模型(VLA)在状态理解方面的进步,以及基于生成扩散策略的动作头,在上下文和几何上引导驾驶。在上下文中,VLA通过token生成预训练来预测未来的观测,其中观测由条件向量量化变分自编码器(CVQ-VAE)表示为离散代码。在几何上,我们对VLA进行强化学习微调,以基于当前的驾驶条件预测未来的轨迹和动作。VLA为动作策略头提供当前状态token和预测状态token,以生成分层动作和轨迹。在策略训练期间,一个学习到的评论家评估策略生成的动作,并提供基于梯度的反馈,形成一个actor-critic框架,从而实现基于强化的策略学习流程。实验表明,我们的VDRive在Bench2Drive闭环基准测试和nuScenes开环规划中都取得了最先进的性能。
🔬 方法详解
问题定义:自动驾驶系统需要在复杂和动态的环境中做出安全可靠的决策。现有的端到端自动驾驶方法在处理corner cases和理解车辆状态方面存在挑战,导致鲁棒性不足。论文旨在解决自动驾驶车辆在复杂环境下的状态理解和决策问题,提高系统的鲁棒性和安全性。
核心思路:论文的核心思路是将视觉-语言-动作模型(VLA)与生成扩散策略相结合,显式地建模状态-动作映射。VLA负责理解驾驶环境的上下文信息,并预测未来的状态。扩散策略则基于VLA的输出生成分层动作和轨迹。通过强化学习微调VLA,使其能够更好地适应驾驶任务。
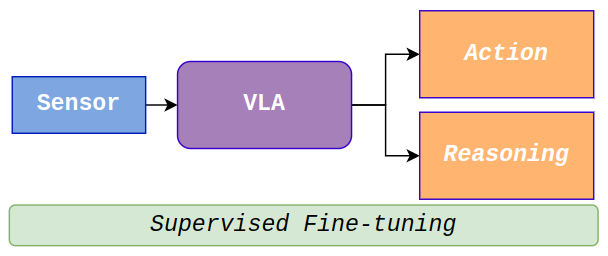
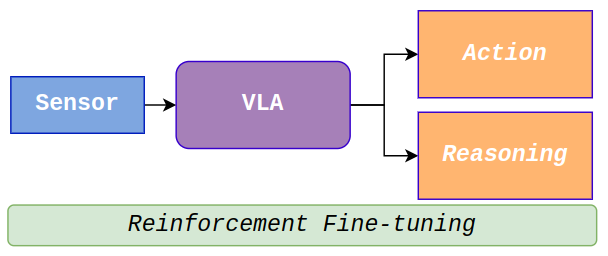
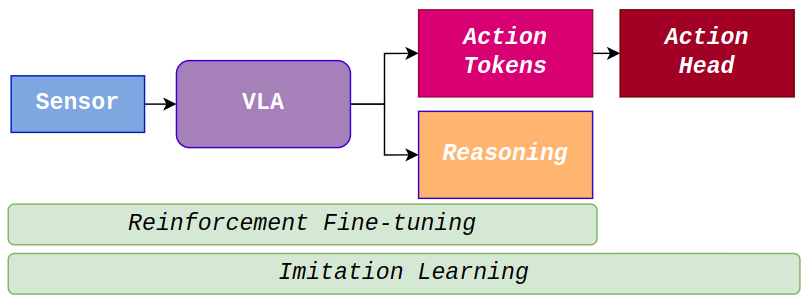
技术框架:VDRive的整体框架包含以下几个主要模块:1) 条件向量量化变分自编码器(CVQ-VAE):将观测数据编码为离散的token表示。2) 视觉-语言-动作模型(VLA):利用token生成预训练预测未来观测。3) 扩散策略动作头:基于VLA的输出生成分层动作和轨迹。4) 强化学习模块:通过actor-critic框架对VLA进行微调,优化策略。整个流程是端到端的,从原始的视觉输入到最终的车辆控制指令。
关键创新:VDRive的关键创新在于将VLA与扩散策略相结合,并使用强化学习进行微调。VLA提供了丰富的上下文信息,扩散策略则能够生成多样化的动作。强化学习则能够优化策略,使其更好地适应驾驶任务。这种结合使得VDRive能够更好地理解驾驶环境,并做出更安全可靠的决策。与现有方法相比,VDRive显式地建模了状态-动作映射,从而提高了系统的可解释性和鲁棒性。
关键设计:CVQ-VAE用于将高维的视觉输入压缩为离散的token表示,这有助于VLA更好地理解驾驶环境。VLA使用Transformer架构,通过token生成预训练来学习驾驶环境的动态特性。扩散策略使用U-Net架构,通过逐步去噪的方式生成动作。强化学习模块使用actor-critic算法,其中actor负责生成动作,critic负责评估动作的质量。损失函数包括重构损失、KL散度和强化学习奖励。
🖼️ 关键图片
📊 实验亮点
VDRive在Bench2Drive闭环基准测试和nuScenes开环规划中都取得了最先进的性能。在Bench2Drive上,VDRive显著优于现有的端到端自动驾驶方法。在nuScenes上,VDRive也取得了具有竞争力的结果,证明了其在复杂环境下的规划能力。这些实验结果表明,VDRive是一种有效的端到端自动驾驶解决方案。
🎯 应用场景
VDRive具有广泛的应用前景,可用于各种自动驾驶场景,包括城市道路、高速公路和越野环境。该研究的成果可以提高自动驾驶系统的安全性、可靠性和鲁棒性,从而加速自动驾驶技术的商业化落地。此外,该方法还可以应用于机器人导航、游戏AI等领域。
📄 摘要(原文)
In autonomous driving, dynamic environment and corner cases pose significant challenges to the robustness of ego vehicle's state understanding and decision making. We introduce VDRive, a novel pipeline for end-to-end autonomous driving that explicitly models state-action mapping to address these challenges, enabling interpretable and robust decision making. By leveraging the advancement of the state understanding of the Vision Language Action Model (VLA) with generative diffusion policy-based action head, our VDRive guides the driving contextually and geometrically. Contextually, VLA predicts future observations through token generation pre-training, where the observations are represented as discrete codes by a Conditional Vector Quantized Variational Autoencoder (CVQ-VAE). Geometrically, we perform reinforcement learning fine-tuning of the VLA to predict future trajectories and actions based on current driving conditions. VLA supplies the current state tokens and predicted state tokens for the action policy head to generate hierarchical actions and trajectories. During policy training, a learned critic evaluates the actions generated by the policy and provides gradient-based feedback, forming an actor-critic framework that enables a reinforcement-based policy learning pipeline. Experiments show that our VDRive achieves state-of-the-art performance in the Bench2Drive closed-loop benchmark and nuScenes open-loop planning.