RM-RL: Role-Model Reinforcement Learning for Precise Robot Manipulation
作者: Xiangyu Chen, Chuhao Zhou, Yuxi Liu, Jianfei Yang
分类: cs.RO
发布日期: 2025-10-16
💡 一句话要点
提出RM-RL,用于精确机器人操作,无需人工演示。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 强化学习 模仿学习 角色模型 在线学习 离线学习 精确操作
📋 核心要点
- 现有机器人操作方法依赖专家演示,获取高质量演示困难且耗时,离线强化学习存在分布偏移和数据效率问题。
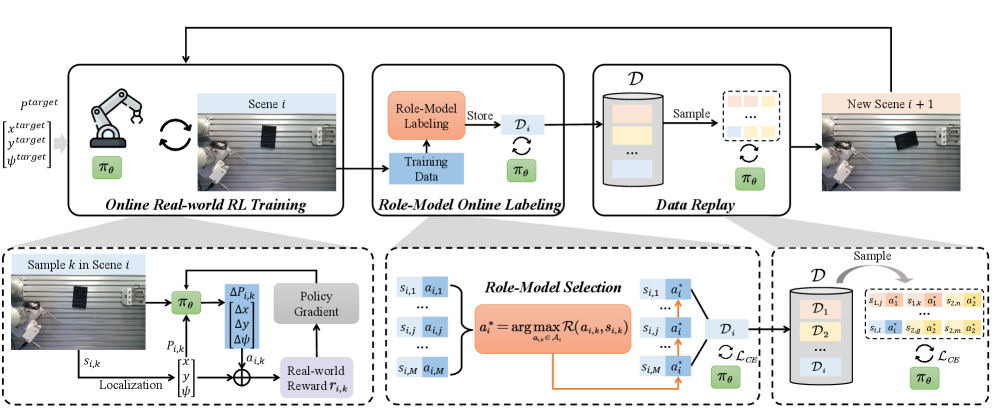
- RM-RL框架通过角色模型策略自动生成在线训练标签,无需人工演示,并将策略学习转化为监督训练。
- 实验表明,RM-RL收敛更快更稳定,在真实操作中平移精度提升53%,旋转精度提升20%,成功完成复杂任务。
📝 摘要(中文)
精确的机器人操作对于精细应用至关重要,例如化学和生物实验,即使是微小的误差也可能导致整个任务失效。现有方法依赖于预先收集的专家演示,并通过模仿学习(IL)或离线强化学习(RL)训练策略。然而,获取高质量的精确任务演示既困难又耗时,而离线RL通常受到分布偏移和数据效率低的困扰。我们引入了一种角色模型强化学习(RM-RL)框架,该框架统一了真实环境中的在线和离线训练。其核心思想是一种角色模型策略,该策略使用近似最优动作自动生成在线训练数据的标签,从而无需人工演示。RM-RL将策略学习重新定义为监督训练,减少了分布不匹配带来的不稳定性,并提高了效率。混合训练方案进一步利用在线角色模型数据进行离线重用,通过重复采样提高数据效率。大量实验表明,RM-RL比现有的RL方法收敛更快、更稳定,并在真实操作中产生了显著的收益:平移精度提高了53%,旋转精度提高了20%。最后,我们展示了成功执行一项具有挑战性的任务,即将细胞板精确地放置在架子上,突出了该框架在现有方法失败时的有效性。
🔬 方法详解
问题定义:论文旨在解决精确机器人操作中,依赖人工演示导致数据获取困难,以及离线强化学习中分布偏移和数据效率低下的问题。现有方法难以在真实环境中高效、稳定地训练出精确的操作策略。
核心思路:论文的核心思路是利用“角色模型”自动生成高质量的训练标签,从而避免对人工演示的依赖。角色模型通过近似最优动作来指导在线训练,并将强化学习问题转化为监督学习问题,降低了分布偏移带来的影响。
技术框架:RM-RL框架包含在线和离线训练两个阶段。在线阶段,角色模型根据当前状态生成动作标签,用于训练策略网络。离线阶段,利用在线生成的数据进行离线重用,通过混合训练进一步提高数据效率。整体流程是:环境交互 -> 角色模型生成标签 -> 策略网络训练 -> 离线数据重用。
关键创新:最重要的技术创新点是角色模型的引入,它取代了人工演示,实现了自动化的标签生成。这使得RM-RL能够在真实环境中进行高效的在线学习,并克服了离线强化学习的局限性。角色模型的设计是关键,需要能够提供足够准确的动作指导。
关键设计:角色模型的具体实现方式未知,论文中可能涉及特定的网络结构、损失函数设计以及参数设置,以保证角色模型能够生成高质量的动作标签。混合训练方案的具体实现细节,例如如何平衡在线和离线数据,也是关键的设计考虑。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RM-RL在真实机器人操作任务中表现出色,平移精度提高了53%,旋转精度提高了20%,显著优于现有的强化学习方法。此外,RM-RL成功完成了一项具有挑战性的任务,即将细胞板精确地放置在架子上,证明了该框架在现有方法失败时的有效性。这些结果验证了RM-RL在精确机器人操作方面的优势。
🎯 应用场景
该研究成果可广泛应用于需要高精度操作的机器人应用领域,例如:化学和生物实验中的试剂配比、医疗手术中的微创操作、精密仪器组装等。通过降低对人工演示的依赖,可以加速机器人技术的部署和应用,提高自动化水平和生产效率。未来,该方法有望扩展到更复杂的机器人任务中。
📄 摘要(原文)
Precise robot manipulation is critical for fine-grained applications such as chemical and biological experiments, where even small errors (e.g., reagent spillage) can invalidate an entire task. Existing approaches often rely on pre-collected expert demonstrations and train policies via imitation learning (IL) or offline reinforcement learning (RL). However, obtaining high-quality demonstrations for precision tasks is difficult and time-consuming, while offline RL commonly suffers from distribution shifts and low data efficiency. We introduce a Role-Model Reinforcement Learning (RM-RL) framework that unifies online and offline training in real-world environments. The key idea is a role-model strategy that automatically generates labels for online training data using approximately optimal actions, eliminating the need for human demonstrations. RM-RL reformulates policy learning as supervised training, reducing instability from distribution mismatch and improving efficiency. A hybrid training scheme further leverages online role-model data for offline reuse, enhancing data efficiency through repeated sampling. Extensive experiments show that RM-RL converges faster and more stably than existing RL methods, yielding significant gains in real-world manipulation: 53% improvement in translation accuracy and 20% in rotation accuracy. Finally, we demonstrate the successful execution of a challenging task, precisely placing a cell plate onto a shelf, highlighting the framework's effectiveness where prior methods fail.