CBF-RL: Safety Filtering Reinforcement Learning in Training with Control Barrier Functions
作者: Lizhi Yang, Blake Werner, Massimiliano de Sa, Aaron D. Ames
分类: cs.RO, cs.AI, cs.LG, eess.SY
发布日期: 2025-10-16 (更新: 2025-10-19)
备注: 8 pages
💡 一句话要点
提出CBF-RL,通过控制屏障函数在训练中进行安全过滤的强化学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 控制屏障函数 安全控制 机器人控制 安全滤波 自主导航 人形机器人
📋 核心要点
- 传统强化学习在追求高性能时忽略安全性,导致实际应用中存在潜在风险,尤其是在机器人控制等领域。
- CBF-RL通过在训练过程中引入控制屏障函数,并对策略rollout进行安全过滤,从而在学习过程中融入安全约束。
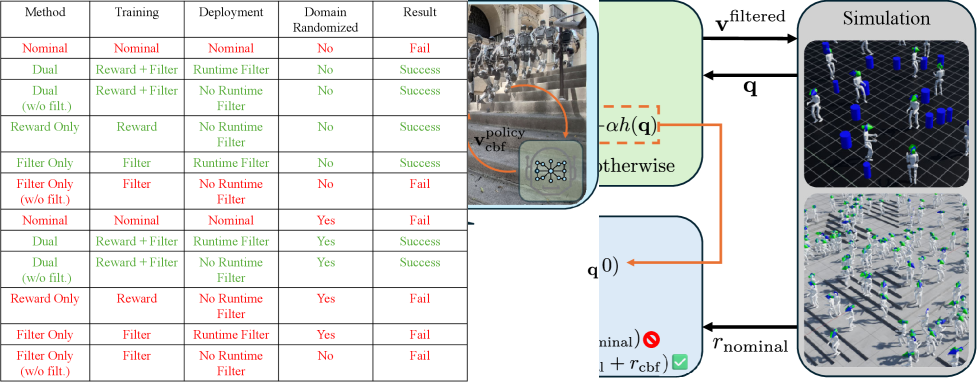
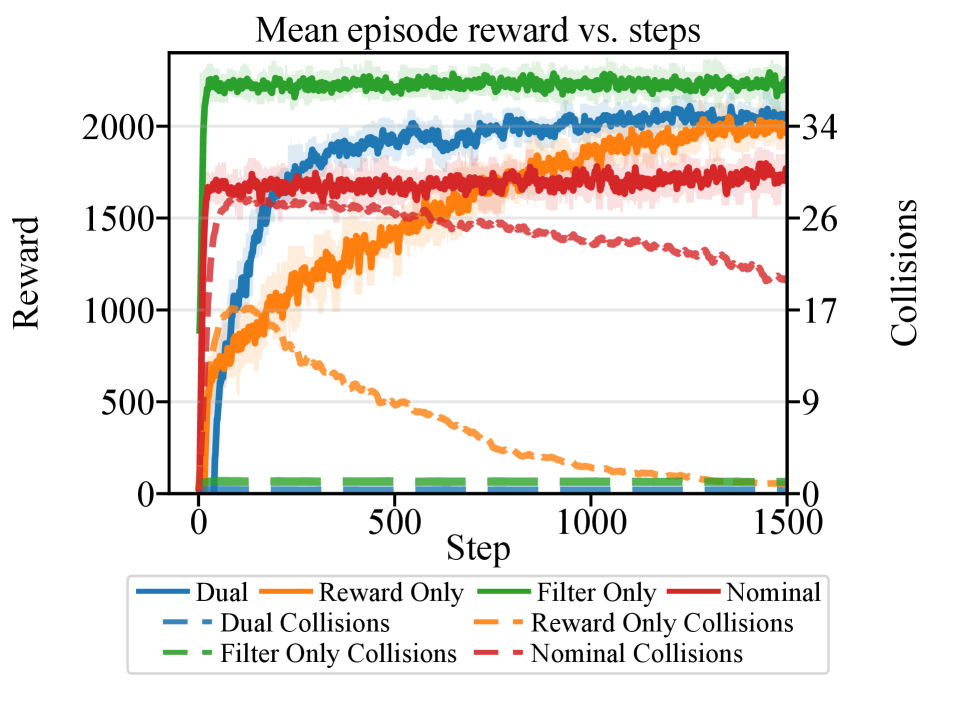
- 实验表明,CBF-RL能使机器人更安全地探索环境,加速收敛,并在不确定性下表现出更强的鲁棒性,无需在线安全滤波器。
📝 摘要(中文)
强化学习(RL)虽然强大且具有表现力,但常常以牺牲安全性为代价来优先考虑性能。然而,安全违规可能导致现实部署中的灾难性后果。控制屏障函数(CBF)提供了一种强制执行动态安全性的原则性方法,传统上通过安全滤波器在线部署。虽然结果是安全的行为,但RL策略不了解CBF这一事实可能导致保守的行为。本文提出了CBF-RL,一个通过在训练中强制执行CBF来生成具有RL的安全行为的框架。CBF-RL具有两个关键属性:(1)最小程度地修改标称RL策略,以通过CBF项编码安全约束,(2)以及在训练中对策略rollout进行安全过滤。从理论上讲,我们证明了连续时间安全滤波器可以通过离散时间rollout上的闭式表达式进行部署。在实践中,我们证明了CBF-RL将安全约束内化到学习的策略中——既强制执行更安全的动作,又偏向更安全的回报——从而无需在线安全滤波器即可实现安全部署。我们通过在导航任务和Unitree G1人形机器人上的消融研究验证了我们的框架,其中CBF-RL实现了更安全的探索、更快的收敛以及在不确定性下的鲁棒性能,使人形机器人能够在没有运行时安全滤波器的情况下安全地避开障碍物并安全地爬楼梯。
🔬 方法详解
问题定义:强化学习在机器人控制等安全攸关的应用中,常常难以保证安全性。传统的安全保障方法,如在线安全滤波器,虽然可以保证安全,但会限制策略的探索,导致保守的行为。因此,如何在强化学习训练过程中有效地融入安全约束,学习到既安全又高效的策略,是一个重要的挑战。
核心思路:CBF-RL的核心思路是在强化学习训练过程中,利用控制屏障函数(CBF)来显式地编码安全约束。通过在训练中对策略的rollout进行安全过滤,使策略能够学习到满足安全约束的行为。同时,通过修改奖励函数,使策略倾向于选择更安全的动作,从而将安全约束内化到策略中。
技术框架:CBF-RL框架主要包含以下几个模块:1)标称RL策略:使用任意的强化学习算法训练一个初始策略。2)控制屏障函数(CBF):定义系统的安全区域,并提供一个安全约束。3)安全滤波器:利用CBF对策略的动作进行修正,保证动作的安全性。4)奖励函数修改:根据CBF的值修改奖励函数,使策略倾向于选择更安全的动作。在训练过程中,首先使用标称RL策略生成rollout,然后使用安全滤波器对rollout进行过滤,并根据CBF的值修改奖励函数。最后,使用修改后的rollout和奖励函数更新策略。
关键创新:CBF-RL的关键创新在于将控制屏障函数融入到强化学习的训练过程中,从而使策略能够学习到满足安全约束的行为。与传统的在线安全滤波器相比,CBF-RL能够将安全约束内化到策略中,从而避免了保守的行为。此外,CBF-RL还提供了一种在离散时间rollout上部署连续时间安全滤波器的方法。
关键设计:CBF-RL的关键设计包括:1)控制屏障函数的选择:需要根据具体的任务选择合适的控制屏障函数,以保证安全约束的有效性。2)安全滤波器的设计:需要设计一个有效的安全滤波器,以保证动作的安全性,同时尽量减少对策略的干扰。3)奖励函数修改的设计:需要设计一个合适的奖励函数修改方案,以使策略倾向于选择更安全的动作。
🖼️ 关键图片

📊 实验亮点
CBF-RL在导航任务和Unitree G1人形机器人上的实验表明,该方法能够显著提高机器人的安全性,加速收敛,并在不确定性下表现出更强的鲁棒性。例如,在人形机器人爬楼梯的实验中,CBF-RL能够使机器人在没有运行时安全滤波器的情况下安全地避开障碍物并安全地爬楼梯。
🎯 应用场景
CBF-RL可应用于各种安全攸关的机器人控制任务,例如自动驾驶、人形机器人、无人机等。该方法能够提高机器人在复杂环境中的安全性和鲁棒性,降低事故发生的风险。此外,CBF-RL还可以应用于其他需要安全保障的强化学习任务,例如金融交易、医疗决策等。
📄 摘要(原文)
Reinforcement learning (RL), while powerful and expressive, can often prioritize performance at the expense of safety. Yet safety violations can lead to catastrophic outcomes in real-world deployments. Control Barrier Functions (CBFs) offer a principled method to enforce dynamic safety -- traditionally deployed online via safety filters. While the result is safe behavior, the fact that the RL policy does not have knowledge of the CBF can lead to conservative behaviors. This paper proposes CBF-RL, a framework for generating safe behaviors with RL by enforcing CBFs in training. CBF-RL has two key attributes: (1) minimally modifying a nominal RL policy to encode safety constraints via a CBF term, (2) and safety filtering of the policy rollouts in training. Theoretically, we prove that continuous-time safety filters can be deployed via closed-form expressions on discrete-time roll-outs. Practically, we demonstrate that CBF-RL internalizes the safety constraints in the learned policy -- both enforcing safer actions and biasing towards safer rewards -- enabling safe deployment without the need for an online safety filter. We validate our framework through ablation studies on navigation tasks and on the Unitree G1 humanoid robot, where CBF-RL enables safer exploration, faster convergence, and robust performance under uncertainty, enabling the humanoid robot to avoid obstacles and climb stairs safely in real-world settings without a runtime safety filter.