From Language to Locomotion: Retargeting-free Humanoid Control via Motion Latent Guidance
作者: Zhe Li, Cheng Chi, Yangyang Wei, Boan Zhu, Yibo Peng, Tao Huang, Pengwei Wang, Zhongyuan Wang, Shanghang Zhang, Chang Xu
分类: cs.RO, cs.CV
发布日期: 2025-10-16 (更新: 2025-10-17)
💡 一句话要点
RoboGhost:提出一种无重定向的语言引导人形机器人运动控制框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人形机器人控制 语言引导 运动生成 扩散模型 无重定向 Transformer 运动潜在空间
📋 核心要点
- 现有语言引导的人形机器人运动控制流程繁琐且不可靠,存在累积误差和高延迟问题。
- RoboGhost通过语言引导的运动潜在空间,直接调节人形机器人策略,无需显式运动解码和重定向。
- 实验结果表明,RoboGhost降低了延迟,提高了成功率和跟踪精度,并生成了平滑的运动。
📝 摘要(中文)
本文提出了一种名为RoboGhost的无重定向框架,用于直接根据语言引导人形机器人运动。该方法避免了解码人体运动并将其重定向到机器人形态的传统流程,从而消除了累积误差、降低了延迟,并增强了语义与控制之间的耦合。RoboGhost利用基于扩散的策略,直接从噪声中去噪可执行的动作,保留语义意图并支持快速、反应式的控制。混合因果Transformer-扩散运动生成器进一步确保了长时程一致性,同时保持稳定性和多样性,从而为精确的人形机器人行为产生丰富的潜在表示。实验表明,RoboGhost显著降低了部署延迟,提高了成功率和跟踪精度,并在真实人形机器人上产生了平滑、语义对齐的运动。此外,该框架可以自然地扩展到其他模态,如图像、音频和音乐,为视觉-语言-动作人形机器人系统提供了一个通用的基础。
🔬 方法详解
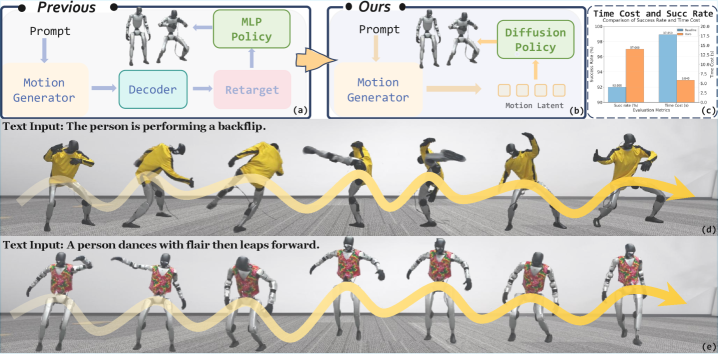
问题定义:现有语言引导的人形机器人控制方法通常需要先解码人类运动,然后将其重定向到机器人形态,最后通过物理控制器进行跟踪。这种多阶段流程容易产生累积误差,引入较高的延迟,并且语义和控制之间的耦合较弱。因此,需要一种更直接的从语言到动作的路径,消除脆弱的中间阶段。
核心思路:RoboGhost的核心思路是绕过显式的运动解码和重定向步骤,直接根据语言引导的运动潜在空间来调节人形机器人的控制策略。通过这种方式,可以避免中间步骤引入的误差,降低延迟,并增强语义和控制之间的直接关联。
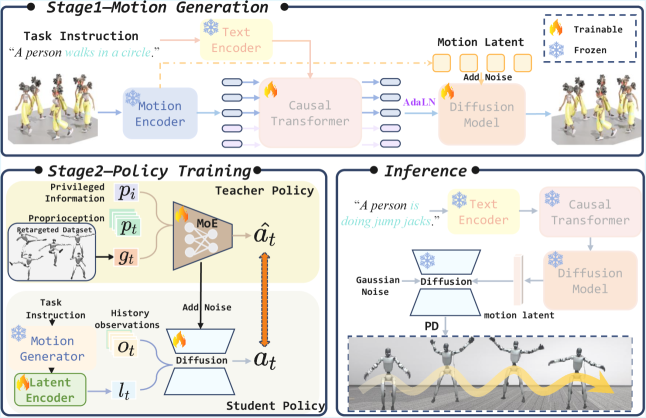
技术框架:RoboGhost框架包含一个混合因果Transformer-扩散运动生成器和一个基于扩散的控制策略。运动生成器负责根据语言输入生成运动潜在表示,该表示随后被用作控制策略的条件。控制策略则直接从噪声中去噪可执行的机器人动作,以实现期望的运动。
关键创新:RoboGhost的关键创新在于其无重定向的设计,以及使用扩散模型直接生成机器人动作。这与传统的先生成人类运动再重定向到机器人的方法不同,避免了重定向过程中的信息损失和误差累积。此外,混合因果Transformer-扩散运动生成器能够生成长时程一致且多样化的运动潜在表示。
关键设计:运动生成器采用混合因果Transformer-扩散架构,Transformer用于捕捉长时程依赖关系,扩散模型用于生成多样化的运动潜在表示。控制策略使用扩散模型,以运动潜在表示为条件,直接生成机器人关节的控制信号。具体的损失函数和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RoboGhost显著降低了部署延迟,提高了运动控制的成功率和跟踪精度。与现有方法相比,RoboGhost能够生成更平滑、语义对齐的运动,并且在真实人形机器人上取得了良好的效果。具体的性能提升数据和对比基线在论文中进行了详细展示(未知)。
🎯 应用场景
RoboGhost框架可应用于各种需要语言引导的人形机器人控制场景,例如家庭服务、工业自动化、搜救行动等。该框架还可以扩展到其他模态输入,如图像、音频和音乐,为构建通用的人形机器人系统奠定基础,实现更自然、智能的人机交互。
📄 摘要(原文)
Natural language offers a natural interface for humanoid robots, but existing language-guided humanoid locomotion pipelines remain cumbersome and untrustworthy. They typically decode human motion, retarget it to robot morphology, and then track it with a physics-based controller. However, this multi-stage process is prone to cumulative errors, introduces high latency, and yields weak coupling between semantics and control. These limitations call for a more direct pathway from language to action, one that eliminates fragile intermediate stages. Therefore, we present RoboGhost, a retargeting-free framework that directly conditions humanoid policies on language-grounded motion latents. By bypassing explicit motion decoding and retargeting, RoboGhost enables a diffusion-based policy to denoise executable actions directly from noise, preserving semantic intent and supporting fast, reactive control. A hybrid causal transformer-diffusion motion generator further ensures long-horizon consistency while maintaining stability and diversity, yielding rich latent representations for precise humanoid behavior. Extensive experiments demonstrate that RoboGhost substantially reduces deployment latency, improves success rates and tracking precision, and produces smooth, semantically aligned locomotion on real humanoids. Beyond text, the framework naturally extends to other modalities such as images, audio, and music, providing a universal foundation for vision-language-action humanoid systems.