Architecture Is All You Need: Diversity-Enabled Sweet Spots for Robust Humanoid Locomotion
作者: Blake Werner, Lizhi Yang, Aaron D. Ames
分类: cs.RO, cs.AI, cs.LG, eess.SY
发布日期: 2025-10-16 (更新: 2025-10-19)
备注: 8 pages
💡 一句话要点
提出分层控制架构,提升人形机器人复杂地形的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 人形机器人 分层控制 鲁棒运动 深度学习 感知决策
📋 核心要点
- 现有端到端人形机器人控制方法难以平衡快速稳定和慢速感知决策,导致在复杂环境中鲁棒性不足。
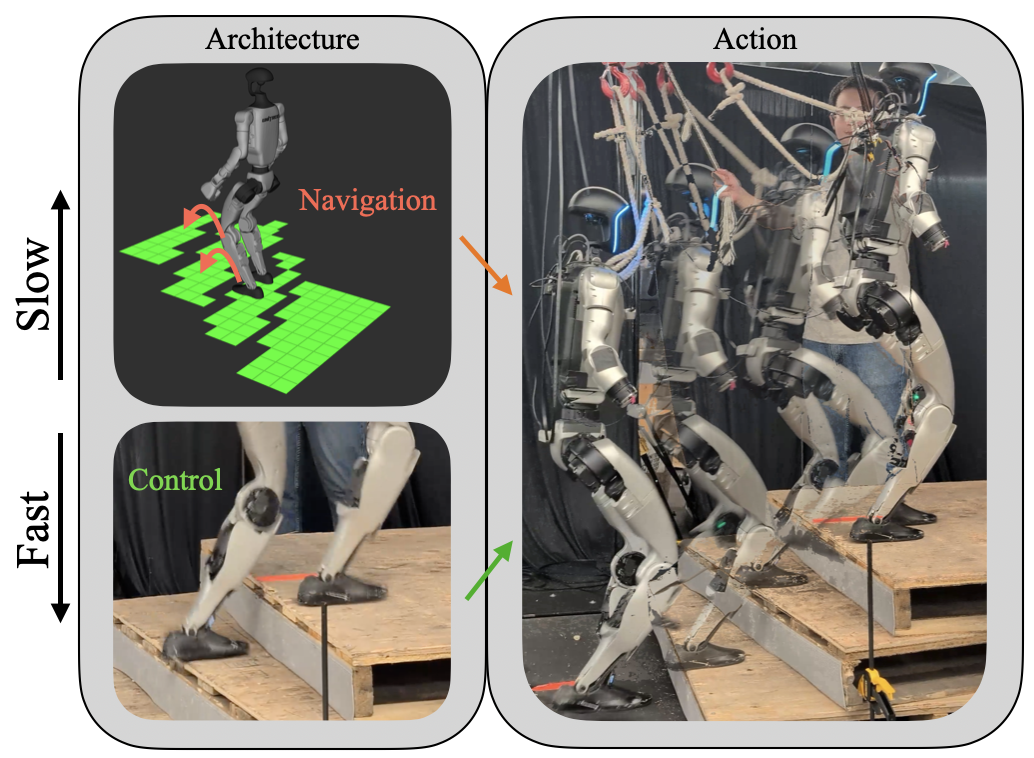
- 论文提出分层控制架构,将高速本体感受稳定器与低速感知策略分离,实现时间尺度解耦,提升鲁棒性。
- 实验表明,分层策略在仿真和硬件上均优于单阶段策略,成功完成楼梯和边缘等复杂任务,验证了架构分离的有效性。
📝 摘要(中文)
在非结构化环境中实现鲁棒的人形机器人运动,需要平衡快速的底层稳定控制和较慢的感知决策。本文提出一种简单的分层控制架构(LCA),它由一个高速率的本体感受稳定器和一个低速率的紧凑感知策略组成。实验表明,相比于单体端到端设计,即使使用最小的感知编码器,分层策略也能实现更鲁棒的性能。通过两阶段训练课程(盲稳定器预训练和感知微调),分层策略在仿真和硬件上始终优于单阶段替代方案。在Unitree G1人形机器人上,该方法成功完成了单阶段感知策略失败的楼梯和边缘任务。这些结果表明,时间尺度的架构分离,而非网络规模或复杂性,是实现鲁棒的感知条件运动的关键。
🔬 方法详解
问题定义:现有的人形机器人控制方法,特别是端到端的深度学习方法,在复杂环境中难以实现鲁棒的运动控制。这些方法通常难以平衡快速的底层稳定控制和较慢的高层感知决策,导致对环境变化的适应能力较差,容易在非结构化地形中失败。痛点在于缺乏一种有效的架构来解耦不同时间尺度的控制需求。
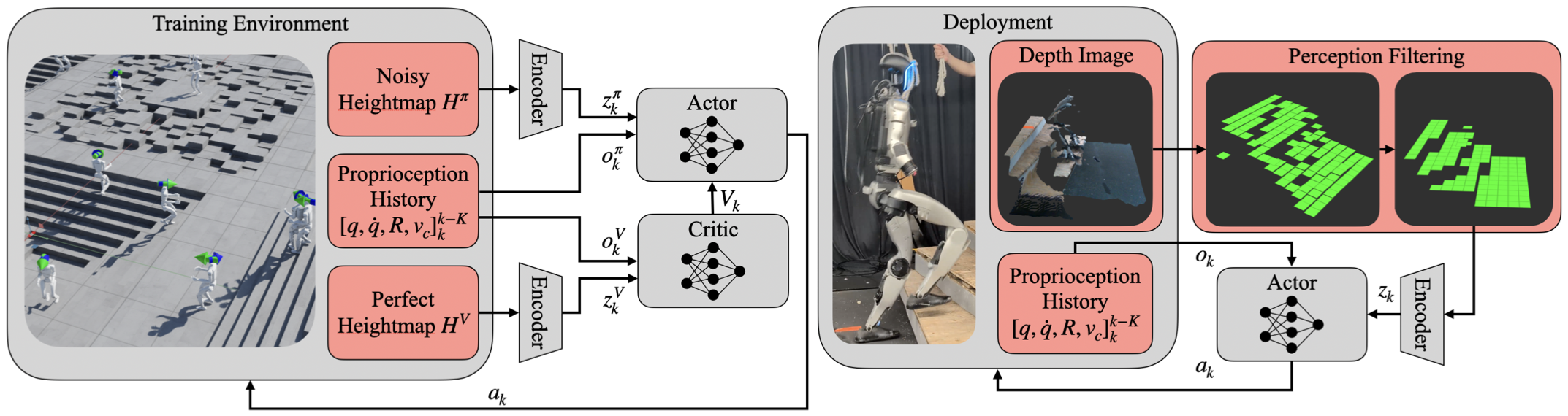
核心思路:论文的核心思路是将人形机器人的控制系统分解为两个层次:一个高速率的本体感受稳定器和一个低速率的感知策略。高速率稳定器负责快速响应机器人的状态变化,维持平衡和姿态稳定;低速率感知策略则负责根据环境信息进行决策,指导机器人的运动方向和目标。通过这种分层架构,可以有效地解耦不同时间尺度的控制需求,提高机器人在复杂环境中的鲁棒性。
技术框架:整体架构是一个两层的控制系统。第一层是高速率的本体感受稳定器,它接收机器人的关节角度、角速度等本体感受信息,并输出关节力矩,以维持机器人的平衡和姿态稳定。第二层是低速率的感知策略,它接收环境信息(例如视觉图像、深度信息),并输出运动指令,例如目标速度、步长等。感知策略的输出作为稳定器的参考输入,从而实现感知引导的运动控制。训练过程分为两个阶段:首先预训练稳定器,使其能够在没有感知信息的情况下维持平衡;然后,固定稳定器的参数,训练感知策略,使其能够根据环境信息进行决策。
关键创新:最重要的技术创新点在于分层控制架构的设计,它将快速的底层稳定控制和较慢的高层感知决策分离,实现了时间尺度的解耦。这种架构能够有效地提高机器人在复杂环境中的鲁棒性,使其能够适应环境的变化。与传统的端到端方法相比,分层架构更易于训练和调试,并且具有更好的泛化能力。
关键设计:稳定器通常采用PD控制或类似的反馈控制方法,其参数需要仔细调整,以保证机器人的平衡和姿态稳定。感知策略通常采用深度神经网络,例如卷积神经网络或循环神经网络,其输入是环境信息,输出是运动指令。损失函数通常包括运动指令的误差、稳定器的控制力矩以及其他正则化项。训练过程中,需要仔细调整学习率、批量大小等超参数,以保证训练的稳定性和收敛性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的分层控制架构在Unitree G1人形机器人上成功完成了楼梯和边缘任务,而单阶段感知策略则失败。在仿真和硬件实验中,分层策略始终优于单阶段替代方案,验证了架构分离的有效性。具体性能数据未知,但论文强调了在复杂地形上的成功率显著提升。
🎯 应用场景
该研究成果可应用于各种人形机器人应用场景,例如搜救、灾后救援、物流配送、家庭服务等。通过提高人形机器人在复杂环境中的鲁棒性,可以使其在这些场景中发挥更大的作用。未来的研究方向包括进一步优化分层控制架构、提高感知策略的精度和效率、以及探索更复杂的环境适应策略。
📄 摘要(原文)
Robust humanoid locomotion in unstructured environments requires architectures that balance fast low-level stabilization with slower perceptual decision-making. We show that a simple layered control architecture (LCA), a proprioceptive stabilizer running at high rate, coupled with a compact low-rate perceptual policy, enables substantially more robust performance than monolithic end-to-end designs, even when using minimal perception encoders. Through a two-stage training curriculum (blind stabilizer pretraining followed by perceptual fine-tuning), we demonstrate that layered policies consistently outperform one-stage alternatives in both simulation and hardware. On a Unitree G1 humanoid, our approach succeeds across stair and ledge tasks where one-stage perceptual policies fail. These results highlight that architectural separation of timescales, rather than network scale or complexity, is the key enabler for robust perception-conditioned locomotion.