VT-Refine: Learning Bimanual Assembly with Visuo-Tactile Feedback via Simulation Fine-Tuning
作者: Binghao Huang, Jie Xu, Iretiayo Akinola, Wei Yang, Balakumar Sundaralingam, Rowland O'Flaherty, Dieter Fox, Xiaolong Wang, Arsalan Mousavian, Yu-Wei Chao, Yunzhu Li
分类: cs.RO, cs.LG
发布日期: 2025-10-16 (更新: 2025-10-18)
备注: Accepted by 9th Conference on Robot Learning (CoRL 2025); Website: https://binghao-huang.github.io/vt_refine/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
VT-Refine:通过模拟微调学习基于视觉-触觉反馈的双臂装配
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 双臂装配 视觉触觉融合 强化学习 模拟微调 策略学习 机器人操作 触觉传感器
📋 核心要点
- 现有方法难以仅通过行为克隆,利用人类演示中的触觉反馈进行双臂装配,原因是人类演示的次优性和多样性有限。
- VT-Refine结合真实演示、高保真触觉模拟和强化学习,通过模拟环境中的策略微调,提升双臂装配的鲁棒性和泛化能力。
- 实验表明,VT-Refine通过增加数据多样性,实现了更有效的策略微调,从而提高了模拟和真实环境中的装配性能。
📝 摘要(中文)
本文提出了一种名为VT-Refine的视觉-触觉策略学习框架,用于解决精确且富含接触的双臂装配任务。该框架结合了真实世界的演示、高保真触觉模拟和强化学习。首先,使用同步的视觉和触觉输入,在少量演示数据上训练扩散策略。然后,将该策略迁移到配备模拟触觉传感器的模拟数字孪生体中,并通过大规模强化学习进一步优化,以增强鲁棒性和泛化能力。为了实现精确的sim-to-real迁移,利用高分辨率压阻式触觉传感器,提供法向力信号,并可以使用GPU加速模拟进行逼真建模。实验结果表明,VT-Refine通过增加数据多样性并实现更有效的策略微调,提高了模拟和真实环境中的装配性能。
🔬 方法详解
问题定义:论文旨在解决机器人双臂装配任务中,难以有效利用触觉反馈的问题。现有方法依赖于行为克隆,直接从人类演示中学习,但人类演示数据存在次优性和多样性不足的问题,导致机器人难以适应复杂和精细的装配过程。尤其是在接触密集型的装配任务中,触觉信息的缺失或不准确会严重影响装配的成功率。
核心思路:论文的核心思路是结合真实世界的少量演示数据和大规模的模拟数据,通过模拟环境中的强化学习来微调策略,从而提高策略的鲁棒性和泛化能力。利用高保真触觉模拟,弥补真实数据中触觉信息不足的问题,并允许通过强化学习探索更多样化的策略。
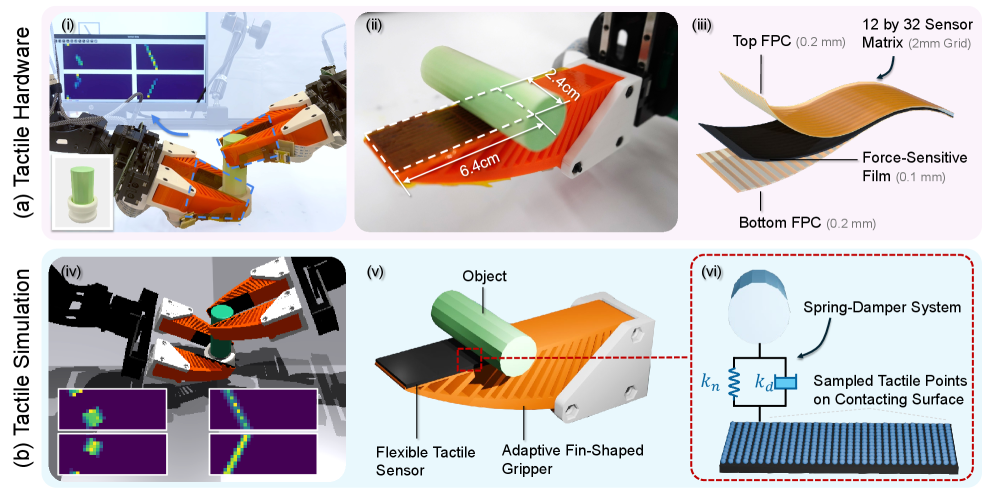
技术框架:VT-Refine框架包含三个主要阶段:1) 基于真实演示数据的扩散策略训练;2) 将训练好的策略迁移到模拟数字孪生体中;3) 在模拟环境中,利用强化学习对策略进行微调。框架利用同步的视觉和触觉输入,并采用高分辨率压阻式触觉传感器,以实现更精确的触觉感知和模拟。
关键创新:最重要的技术创新点在于结合了真实演示数据、高保真触觉模拟和强化学习,实现了一种有效的sim-to-real迁移方法。通过在模拟环境中进行大规模强化学习,可以探索更多样化的策略,并提高策略的鲁棒性和泛化能力。与传统的行为克隆方法相比,VT-Refine能够更好地利用触觉信息,并适应复杂和精细的装配过程。
关键设计:论文使用了扩散模型来学习初始策略,并采用强化学习算法(具体算法未知)在模拟环境中进行策略微调。高分辨率压阻式触觉传感器提供法向力信号,并使用GPU加速模拟进行逼真建模。具体的损失函数和网络结构等技术细节在论文中可能有所描述,但此处信息不足,无法详细说明。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VT-Refine在模拟和真实环境中均取得了显著的性能提升。具体的数据和对比基线未知,但论文强调VT-Refine通过增加数据多样性并实现更有效的策略微调,提高了装配成功率和鲁棒性。高保真触觉模拟和强化学习在策略优化中起到了关键作用。
🎯 应用场景
该研究成果可应用于自动化装配线、精密仪器制造、医疗机器人等领域。通过提高机器人双臂装配的精度和鲁棒性,可以降低生产成本,提高生产效率,并实现更复杂和精细的装配任务。未来,该技术有望应用于更广泛的机器人操作任务中,例如家庭服务机器人、灾难救援机器人等。
📄 摘要(原文)
Humans excel at bimanual assembly tasks by adapting to rich tactile feedback -- a capability that remains difficult to replicate in robots through behavioral cloning alone, due to the suboptimality and limited diversity of human demonstrations. In this work, we present VT-Refine, a visuo-tactile policy learning framework that combines real-world demonstrations, high-fidelity tactile simulation, and reinforcement learning to tackle precise, contact-rich bimanual assembly. We begin by training a diffusion policy on a small set of demonstrations using synchronized visual and tactile inputs. This policy is then transferred to a simulated digital twin equipped with simulated tactile sensors and further refined via large-scale reinforcement learning to enhance robustness and generalization. To enable accurate sim-to-real transfer, we leverage high-resolution piezoresistive tactile sensors that provide normal force signals and can be realistically modeled in parallel using GPU-accelerated simulation. Experimental results show that VT-Refine improves assembly performance in both simulation and the real world by increasing data diversity and enabling more effective policy fine-tuning. Our project page is available at https://binghao-huang.github.io/vt_refine/.