RL-100: Performant Robotic Manipulation with Real-World Reinforcement Learning
作者: Kun Lei, Huanyu Li, Dongjie Yu, Zhenyu Wei, Lingxiao Guo, Zhennan Jiang, Ziyu Wang, Shiyu Liang, Huazhe Xu
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-16 (更新: 2025-11-19)
备注: https://lei-kun.github.io/RL-100/
💡 一句话要点
RL-100:基于真实世界强化学习的高性能机器人操作框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 强化学习 扩散模型 模仿学习 一致性蒸馏 真实世界部署 视觉运动策略
📋 核心要点
- 现有机器人操作方法难以兼顾可靠性、效率和鲁棒性,无法达到熟练操作员的水平。
- RL-100框架融合模仿学习与强化学习,通过扩散模型学习视觉运动策略,实现稳定策略提升。
- 实验表明,RL-100在多种真实机器人任务中达到100%成功率,超越专家水平,并具备良好的泛化能力。
📝 摘要(中文)
本文提出RL-100,一个基于扩散模型的视觉运动策略的真实世界强化学习框架。RL-100在去噪过程中,将模仿学习和强化学习统一在一个PPO风格的目标下,从而在离线和在线阶段实现保守且稳定的策略改进。为了满足部署延迟约束,采用轻量级的一致性蒸馏程序,将多步扩散压缩为单步控制器,以实现高频控制。该框架与任务、机器人形态和表征无关,支持单动作输出和动作分块控制。在七个不同的真实机器人操作任务上评估了RL-100,包括动态推物、敏捷保龄球、倒水、叠布、拧螺丝和多阶段榨汁。RL-100在所有评估试验中均达到100%的成功率,在900个episode中成功900次,在一个任务中连续成功250次,并且在完成时间上与专家遥操作员相匹配或超过。在不重新训练的情况下,单个策略在环境和动力学变化下实现了约90%的零样本成功率,在少量样本情况下适应了显著的任务变化(86.7%),并且对人为扰动保持鲁棒性(约95%)。在公共购物中心的部署中,榨汁机器人连续为随机顾客服务约七个小时而没有出现故障。这些结果表明,实现可部署机器人学习的实用路径是:从人类先验知识开始,将训练目标与人类指标对齐,并可靠地将性能扩展到人类演示之外。
🔬 方法详解
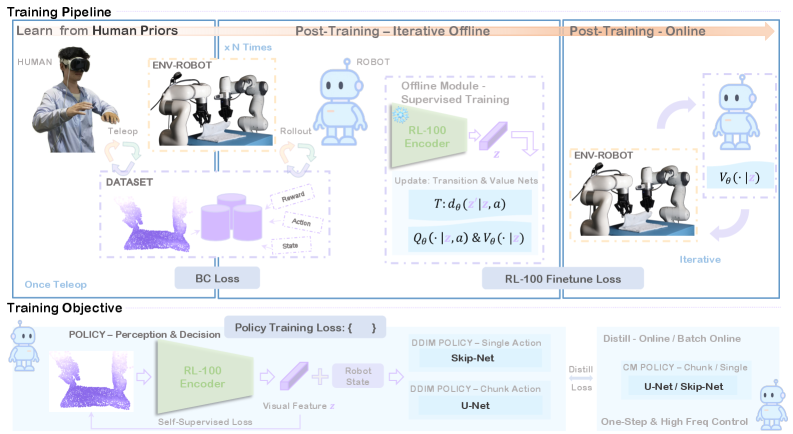
问题定义:现有机器人操作方法在真实世界场景中面临可靠性、效率和鲁棒性的挑战,难以达到甚至超越熟练人类操作员的水平。现有的强化学习方法通常需要大量的训练数据,并且在真实环境中部署时容易受到环境变化和扰动的影响。此外,部署延迟也是一个关键问题,许多方法无法满足实时控制的需求。
核心思路:RL-100的核心思路是将模仿学习和强化学习统一到一个框架中,利用人类演示数据作为先验知识,并通过强化学习进一步优化策略。使用扩散模型学习视觉运动策略,可以有效地处理高维状态空间和动作空间,并生成多样化的动作。通过一致性蒸馏,将多步扩散模型压缩为单步控制器,从而降低部署延迟。
技术框架:RL-100框架包含离线学习和在线优化两个阶段。在离线学习阶段,使用人类演示数据训练一个扩散模型,该模型学习从状态到动作的映射。在在线优化阶段,使用PPO风格的强化学习算法对策略进行微调,以提高性能和鲁棒性。为了降低部署延迟,使用一致性蒸馏将多步扩散模型压缩为单步控制器。整体流程包括数据收集、策略学习、策略优化和策略部署。
关键创新:RL-100的关键创新在于将模仿学习和强化学习统一在一个PPO风格的目标下,并应用于扩散模型的去噪过程。这种方法可以实现保守且稳定的策略改进,避免了传统强化学习方法中常见的策略崩溃问题。此外,使用一致性蒸馏将多步扩散模型压缩为单步控制器,显著降低了部署延迟,使其能够在高频控制场景中使用。
关键设计:RL-100使用扩散模型作为策略网络,该模型将状态作为输入,并输出动作的分布。损失函数包括模仿学习损失和强化学习损失,模仿学习损失用于学习人类演示数据的分布,强化学习损失用于优化策略的奖励。一致性蒸馏使用KL散度作为损失函数,用于衡量多步扩散模型和单步控制器之间的差异。PPO算法用于在线策略优化,使用clip ratio来限制策略更新的幅度。
🖼️ 关键图片


📊 实验亮点
RL-100在七个真实机器人操作任务中实现了100%的成功率,在榨汁任务中连续成功250次。在环境和动力学变化下,单个策略实现了约90%的零样本成功率。在少量样本情况下,适应了显著的任务变化(86.7%),并且对人为扰动保持鲁棒性(约95%)。在公共购物中心的部署中,榨汁机器人连续为随机顾客服务约七个小时而没有出现故障,证明了其在真实世界中的可靠性。
🎯 应用场景
RL-100具有广泛的应用前景,可用于家庭服务机器人、工业自动化、医疗机器人等领域。例如,可以用于开发能够执行复杂家务任务的机器人,提高生产线的自动化水平,以及辅助医生进行手术操作。该研究的实际价值在于提供了一种可靠、高效且鲁棒的机器人学习方法,有望加速机器人技术在各个领域的应用。
📄 摘要(原文)
Real-world robotic manipulation in homes and factories demands reliability, efficiency, and robustness that approach or surpass the performance of skilled human operators. We present RL-100, a real-world reinforcement learning framework built on diffusion-based visuomotor policies. RL-100 unifies imitation and reinforcement learning under a single PPO-style objective applied within the denoising process, yielding conservative and stable policy improvements across both offline and online stages. To meet deployment latency constraints, we employ a lightweight consistency distillation procedure that compresses multi-step diffusion into a one-step controller for high-frequency control. The framework is task-, embodiment-, and representation-agnostic, and supports both single-action outputs and action-chunking control. We evaluate RL-100 on seven diverse real-robot manipulation tasks, ranging from dynamic pushing and agile bowling to pouring, cloth folding, unscrewing, and multi-stage juicing. RL-100 attains 100% success across evaluated trials, achieving 900 out of 900 successful episodes, including up to 250 out of 250 consecutive trials on one task, and matches or surpasses expert teleoperators in time-to-completion. Without retraining, a single policy attains approximately 90% zero-shot success under environmental and dynamics shifts, adapts in a few-shot regime to significant task variations (86.7%), and remains robust to aggressive human perturbations (about 95%). In a public shopping-mall deployment, the juicing robot served random customers continuously for roughly seven hours without failure. Together, these results suggest a practical path toward deployment-ready robot learning: start from human priors, align training objectives with human-grounded metrics, and reliably extend performance beyond human demonstrations.