Generative Models From and For Sampling-Based MPC: A Bootstrapped Approach For Adaptive Contact-Rich Manipulation
作者: Lara Brudermüller, Brandon Hung, Xinghao Zhu, Jiuguang Wang, Nick Hawes, Preston Culbertson, Simon Le Cleac'h
分类: cs.RO
发布日期: 2025-10-16 (更新: 2026-01-07)
备注: 9 pages, 4 figures
💡 一句话要点
提出基于生成模型的采样MPC框架,用于自适应接触式操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 生成模型 模型预测控制 采样式规划 接触式操作 机器人控制
📋 核心要点
- 传统采样MPC方法计算成本高昂,难以实时应用于复杂操作任务,尤其是在接触交互场景下。
- 论文提出一种生成式预测控制框架,利用条件流匹配模型从模拟数据中学习提议分布,引导在线规划过程。
- 实验表明,该方法提高了采样效率,减少了规划范围需求,并在真实四足机器人上实现了稳健的接触式操作。
📝 摘要(中文)
本文提出了一种生成式预测控制(GPC)框架,通过使用在模拟环境中收集的SPC控制序列训练的条件流匹配模型来引导采样式模型预测控制(SPC),从而分摊SPC的计算成本。与依赖迭代优化或基于梯度的求解器的方法不同,我们证明了可以直接从嘈杂的SPC数据中学习到有意义的提议分布,从而在在线规划期间实现更高效和知情的采样。我们进一步首次展示了这种方法在四足机器人的真实世界接触式loco-manipulation中的应用。大量的模拟和硬件实验表明,我们的方法提高了采样效率,降低了规划范围要求,并在任务变化中实现了稳健的泛化。
🔬 方法详解
问题定义:论文旨在解决采样式模型预测控制(SPC)在接触式操作等复杂任务中计算效率低下的问题。传统的SPC方法需要大量的采样才能找到有效的控制序列,尤其是在高维状态空间和复杂动力学模型下,这限制了其在实时机器人控制中的应用。现有的迭代优化或基于梯度的方法可能陷入局部最优,且对初始猜测敏感。
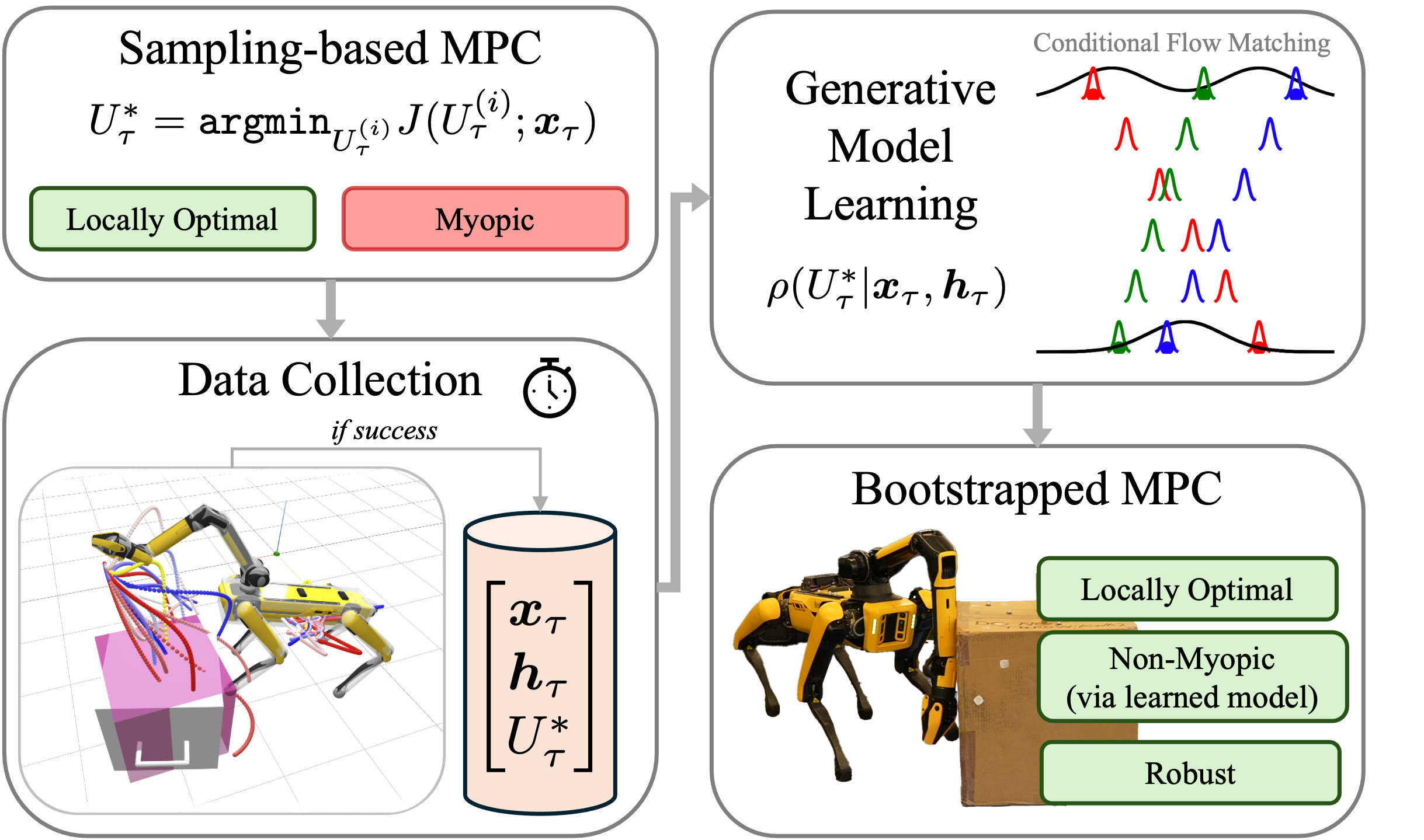
核心思路:论文的核心思路是利用生成模型学习SPC的先验知识,从而引导采样过程,提高采样效率。具体而言,通过在模拟环境中运行SPC收集控制序列数据,然后训练一个条件流匹配模型,该模型能够根据当前状态预测有希望的控制序列分布。在在线规划时,使用该模型生成提议样本,从而减少了随机采样的盲目性。
技术框架:该框架包含离线训练和在线规划两个阶段。离线训练阶段,首先在模拟环境中运行SPC,收集状态-控制序列数据。然后,使用这些数据训练一个条件流匹配模型,该模型以当前状态为条件,输出控制序列的分布参数。在线规划阶段,首先使用条件流匹配模型生成控制序列的提议样本,然后使用SPC对这些样本进行评估和选择,最终执行最优控制序列。
关键创新:该方法最重要的创新点在于利用生成模型直接从SPC数据中学习提议分布,从而避免了迭代优化或梯度下降等复杂过程。与现有方法相比,该方法能够更有效地利用SPC的先验知识,提高采样效率,并降低对初始猜测的敏感性。此外,该方法首次将条件流匹配模型应用于机器人控制领域,并成功应用于真实的四足机器人接触式操作任务。
关键设计:条件流匹配模型采用神经网络结构,输入为当前状态,输出为控制序列的分布参数(例如,高斯分布的均值和方差)。损失函数采用流匹配损失,鼓励模型生成的控制序列与SPC生成的控制序列相似。在在线规划阶段,可以使用不同的采样策略(例如,重要性采样)来利用提议分布生成样本。此外,还可以使用不同的SPC算法(例如,交叉熵方法)来评估和选择样本。
🖼️ 关键图片
📊 实验亮点
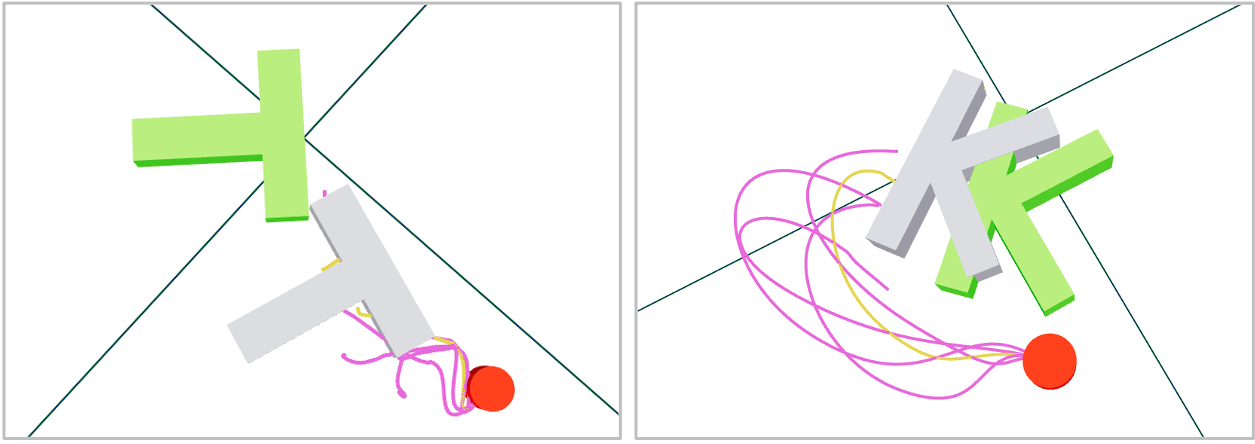
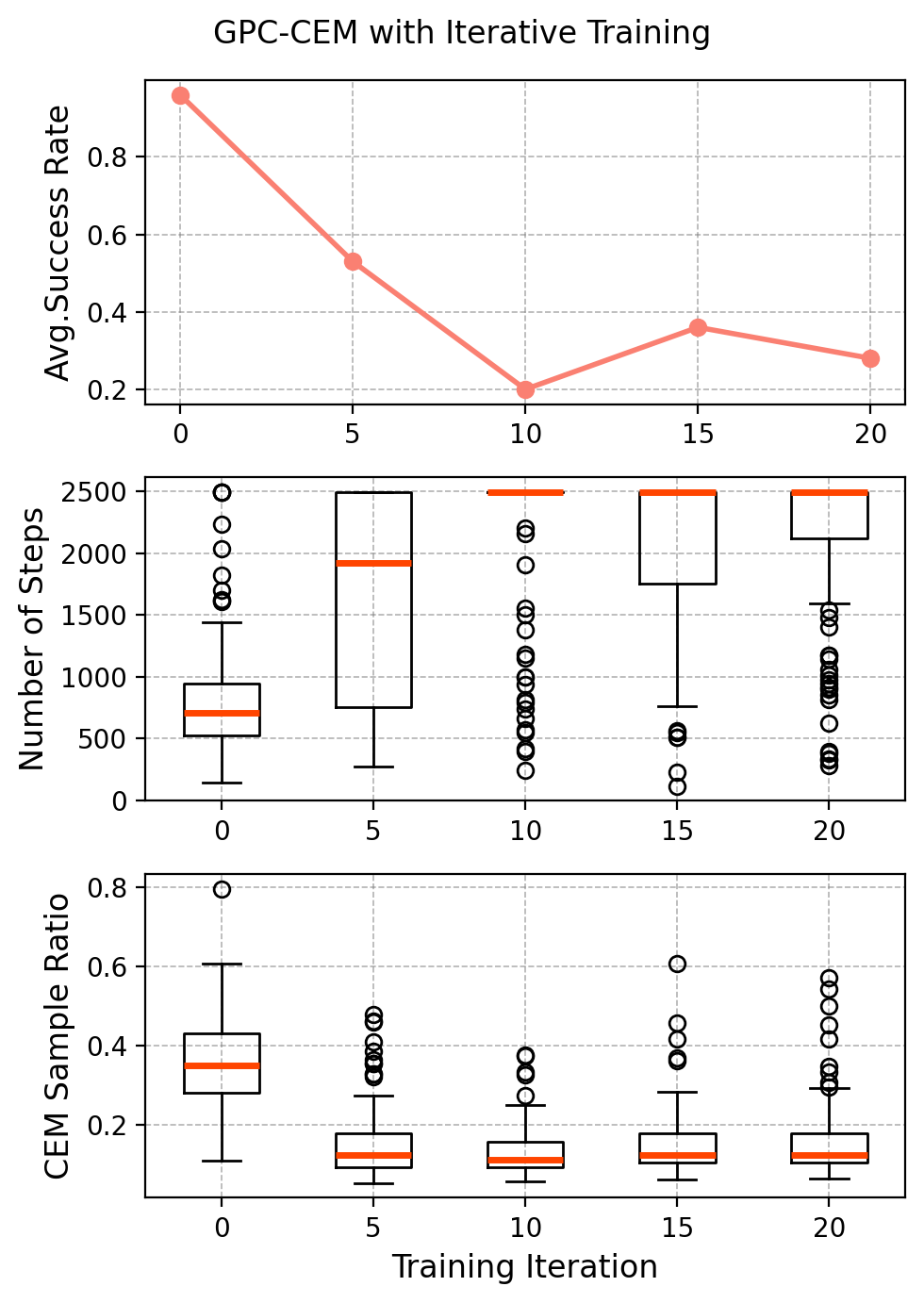
在模拟和真实机器人实验中,该方法显著提高了采样效率,降低了规划范围要求。例如,在四足机器人开门任务中,与传统的SPC方法相比,该方法能够以更少的样本和更短的规划范围成功完成任务。此外,该方法还在不同的任务变体中表现出良好的泛化能力,表明其具有较强的鲁棒性。
🎯 应用场景
该研究成果可应用于各种需要复杂接触交互的机器人操作任务,例如装配、抓取、操作工具等。特别是在资源受限的场景下,例如移动机器人或无人机,提高采样效率可以显著提升控制性能和任务成功率。此外,该方法还可以扩展到其他类型的机器人控制问题,例如运动规划和强化学习。
📄 摘要(原文)
We present a generative predictive control (GPC) framework that amortizes sampling-based Model Predictive Control (SPC) by bootstrapping it with conditional flow-matching models trained on SPC control sequences collected in simulation. Unlike prior work relying on iterative refinement or gradient-based solvers, we show that meaningful proposal distributions can be learned directly from noisy SPC data, enabling more efficient and informed sampling during online planning. We further demonstrate, for the first time, the application of this approach to real-world contact-rich loco-manipulation with a quadruped robot. Extensive experiments in simulation and on hardware show that our method improves sample efficiency, reduces planning horizon requirements, and generalizes robustly across task variations.