SUM-AgriVLN: Spatial Understanding Memory for Agricultural Vision-and-Language Navigation
作者: Xiaobei Zhao, Xingqi Lyu, Xiang Li
分类: cs.RO, cs.AI
发布日期: 2025-10-16
🔗 代码/项目: GITHUB
💡 一句话要点
提出SUM-AgriVLN,利用空间记忆提升农业场景下的视觉语言导航性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 农业机器人 空间记忆 3D重建 机器人导航
📋 核心要点
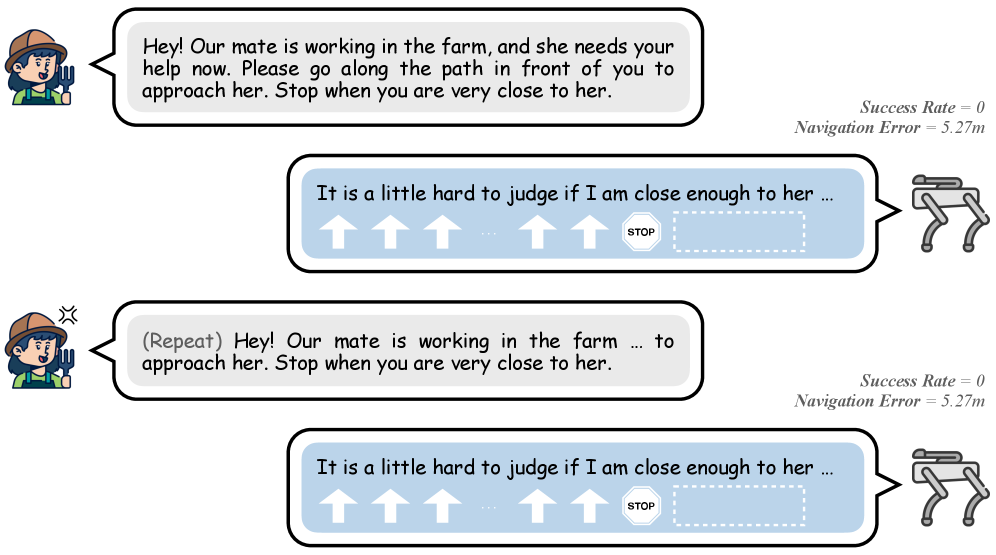
- 现有农业视觉语言导航方法忽略了重复指令间的空间关联,限制了导航性能。
- SUM-AgriVLN通过3D重建和空间记忆模块,利用历史经验提供空间上下文信息。
- 实验表明,SUM-AgriVLN在A2A基准上显著提升了导航成功率,达到SOTA水平。
📝 摘要(中文)
农业机器人正在成为各种农业任务中的强大助手,但目前仍然严重依赖人工操作或固定轨道系统进行移动。 AgriVLN方法和A2A基准率先将视觉语言导航(VLN)扩展到农业领域,使机器人能够按照自然语言指令导航到目标位置。在实际农业场景中,导航指令经常重复出现,但AgriVLN将每个指令视为一个独立的episode,忽略了过去经验为后续指令提供空间上下文的潜力。为了弥合这一差距,我们提出了一种用于农业视觉语言导航的空间理解记忆方法(SUM-AgriVLN),其中SUM模块采用空间理解并通过3D重建和表示来保存空间记忆。在A2A基准上进行评估时,我们的SUM-AgriVLN有效地将成功率从0.47提高到0.54,而导航误差仅从2.91米略微增加到2.93米,展示了在农业领域的最先进性能。
🔬 方法详解
问题定义:现有的AgriVLN方法将每个导航指令视为独立的episode,忽略了农业环境中导航指令重复出现的特性。这种孤立处理方式无法有效利用历史经验提供的空间上下文信息,导致导航效率和准确性受限。因此,如何利用历史导航经验来提升当前导航任务的性能是本文要解决的核心问题。
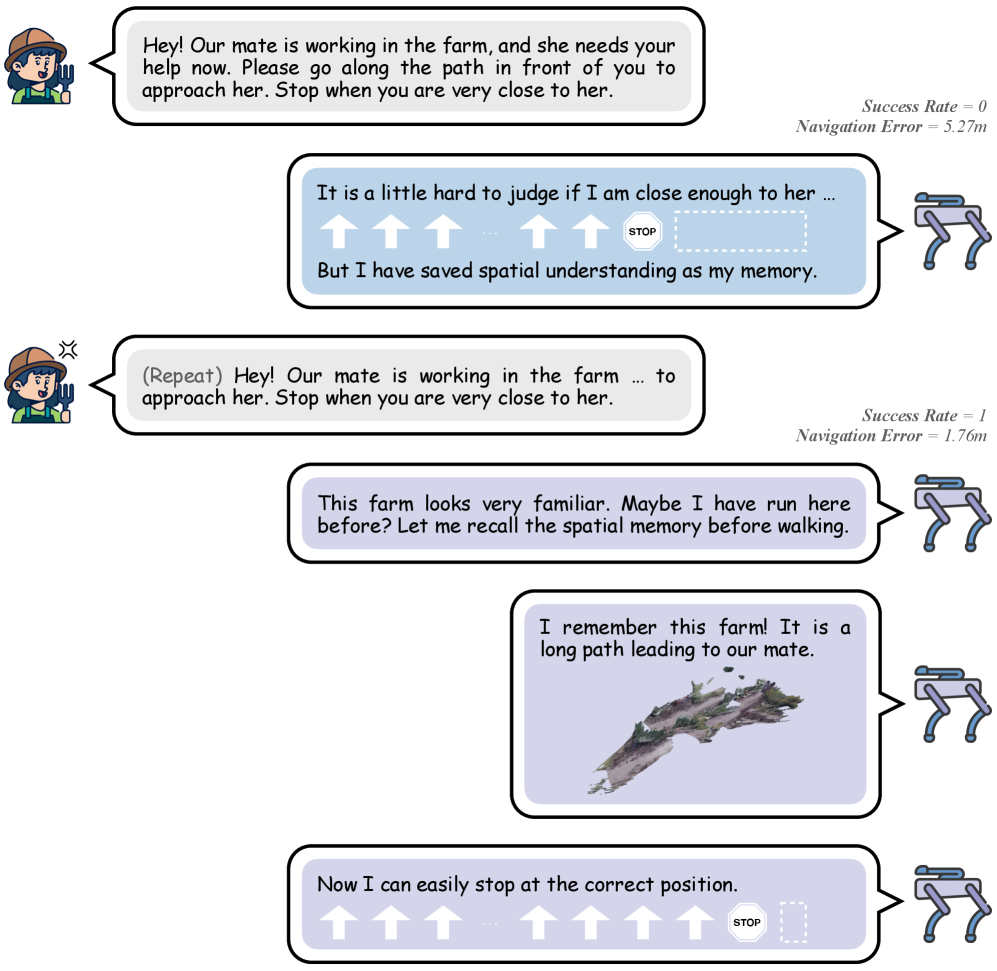
核心思路:本文的核心思路是引入空间理解记忆(Spatial Understanding Memory)模块,该模块通过3D重建和空间表示来保存历史导航过程中的空间信息。在后续导航任务中,该模块可以提供空间上下文,帮助机器人更好地理解当前指令,从而提高导航的成功率。这样设计的目的是为了模拟人类在熟悉环境中的导航方式,即利用记忆中的空间信息来辅助导航。
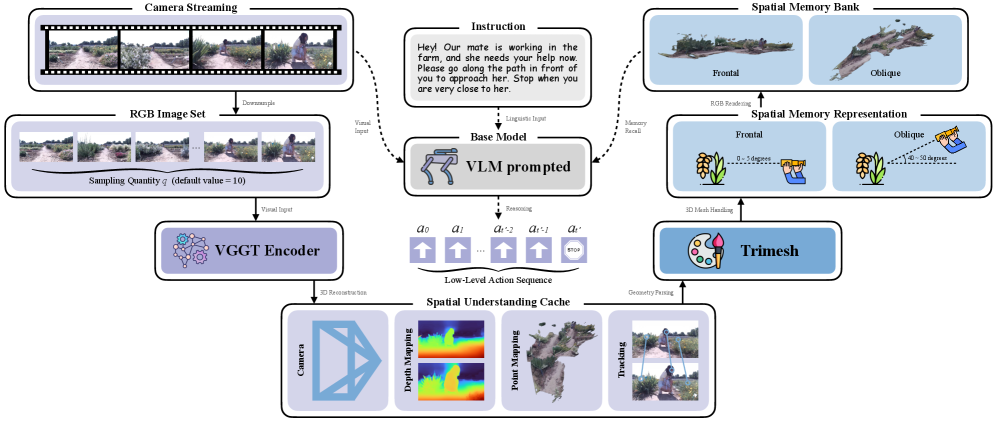
技术框架:SUM-AgriVLN的整体框架包括以下几个主要模块:1) 视觉输入模块:用于处理机器人获取的视觉信息。2) 语言输入模块:用于解析自然语言导航指令。3) 空间理解记忆(SUM)模块:这是本文的核心模块,负责3D重建和空间记忆的存储与检索。4) 导航决策模块:根据视觉信息、语言指令和空间记忆,做出导航决策。整个流程是:机器人首先接收视觉和语言输入,然后SUM模块利用历史经验构建空间记忆,导航决策模块结合这些信息做出下一步行动的决策。
关键创新:本文最重要的技术创新点在于空间理解记忆(SUM)模块的设计。该模块能够将历史导航过程中的空间信息进行3D重建和表示,并存储在空间记忆中。与现有方法相比,SUM模块能够提供更丰富的空间上下文信息,从而帮助机器人更好地理解当前指令,提高导航的成功率。这种利用空间记忆的方式是现有方法所不具备的。
关键设计:SUM模块的关键设计包括:1) 3D重建方法:采用SLAM或SfM等技术,将历史导航过程中的视觉信息重建为3D地图。2) 空间表示方法:使用体素、点云或神经隐式表示等方式,对3D地图进行编码。3) 记忆存储与检索机制:设计高效的存储结构和检索算法,以便快速访问相关的空间信息。4) 损失函数:可能包含重建损失、导航损失等,用于优化SUM模块的性能。具体参数设置和网络结构在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
📊 实验亮点
SUM-AgriVLN在A2A基准测试中取得了显著的性能提升。具体而言,成功率从0.47提高到0.54,提升了约15%。虽然导航误差从2.91米略微增加到2.93米,但成功率的显著提升表明SUM-AgriVLN在农业视觉语言导航任务中具有优越的性能。这些结果证明了空间理解记忆模块的有效性,并为未来的研究提供了有价值的参考。
🎯 应用场景
该研究成果可广泛应用于农业机器人领域,例如自动驾驶收割机、田间巡检机器人、精准施肥机器人等。通过提升机器人在复杂农业环境中的导航能力,可以显著提高农业生产效率,降低人工成本,并实现更精细化的农业管理。未来,该技术还可以扩展到其他需要视觉语言导航的场景,如室内服务机器人、物流机器人等。
📄 摘要(原文)
Agricultural robots are emerging as powerful assistants across a wide range of agricultural tasks, nevertheless, still heavily rely on manual operation or fixed rail systems for movement. The AgriVLN method and the A2A benchmark pioneeringly extend Vision-and-Language Navigation (VLN) to the agricultural domain, enabling robots to navigate to the target positions following the natural language instructions. In practical agricultural scenarios, navigation instructions often repeatedly occur, yet AgriVLN treat each instruction as an independent episode, overlooking the potential of past experiences to provide spatial context for subsequent ones. To bridge this gap, we propose the method of Spatial Understanding Memory for Agricultural Vision-and-Language Navigation (SUM-AgriVLN), in which the SUM module employs spatial understanding and save spatial memory through 3D reconstruction and representation. When evaluated on the A2A benchmark, our SUM-AgriVLN effectively improves Success Rate from 0.47 to 0.54 with slight sacrifice on Navigation Error from 2.91m to 2.93m, demonstrating the state-of-the-art performance in the agricultural domain. Code: https://github.com/AlexTraveling/SUM-AgriVLN.