Risk-Aware Reinforcement Learning with Bandit-Based Adaptation for Quadrupedal Locomotion
作者: Yuanhong Zeng, Anushri Dixit
分类: cs.RO
发布日期: 2025-10-16
💡 一句话要点
提出基于Bandit自适应的风险感知强化学习,提升四足机器人运动鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 风险感知强化学习 四足机器人 运动控制 多臂老虎机 自适应控制
📋 核心要点
- 现有四足机器人强化学习方法在未知环境中泛化性差,难以保证运动的稳定性和鲁棒性。
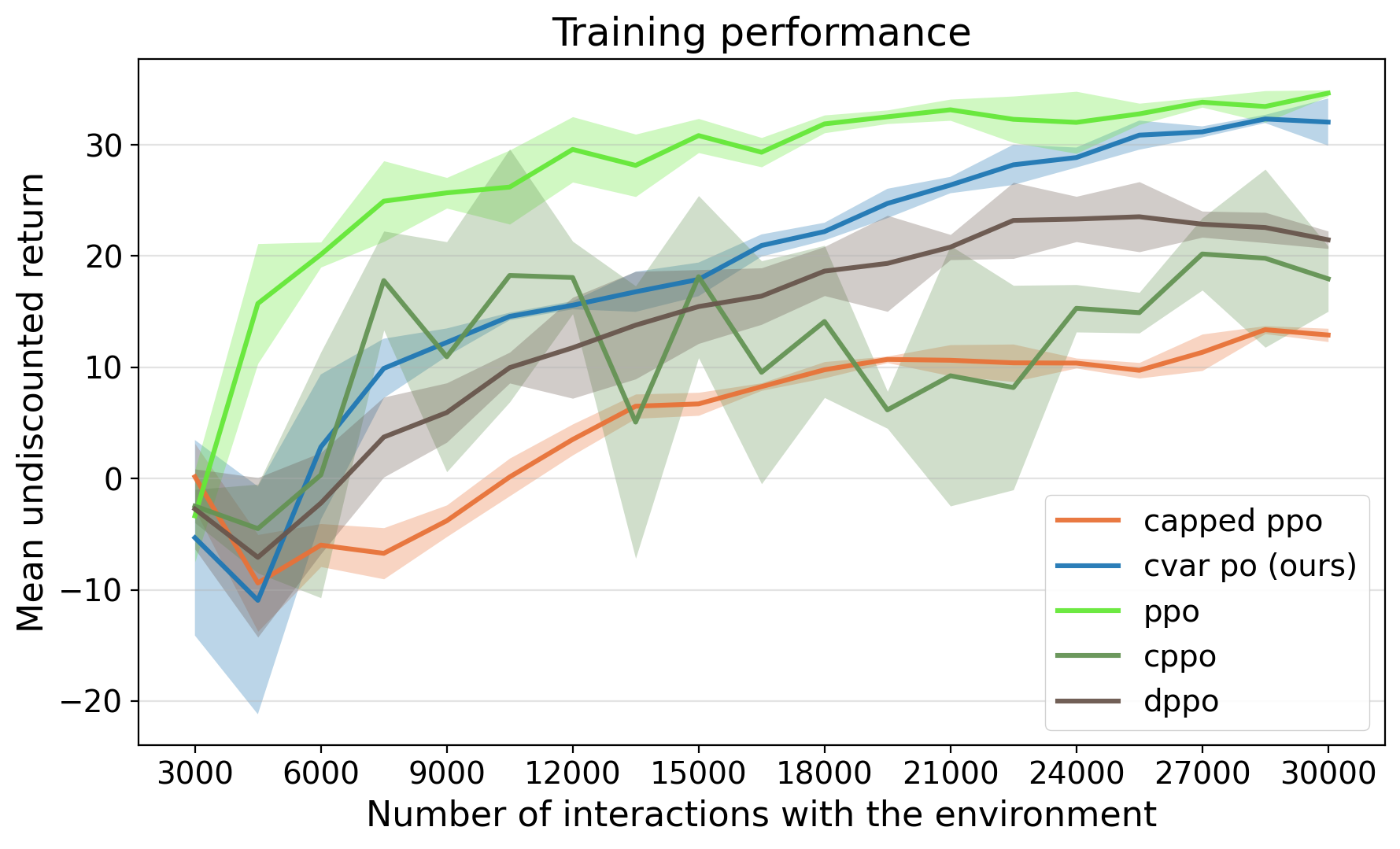
- 提出基于CVaR约束的风险感知强化学习,训练一系列不同风险水平的策略,提高策略的鲁棒性。
- 采用多臂老虎机框架,根据在线观测的回报自适应选择最佳策略,无需环境先验知识,快速适应未知环境。
📝 摘要(中文)
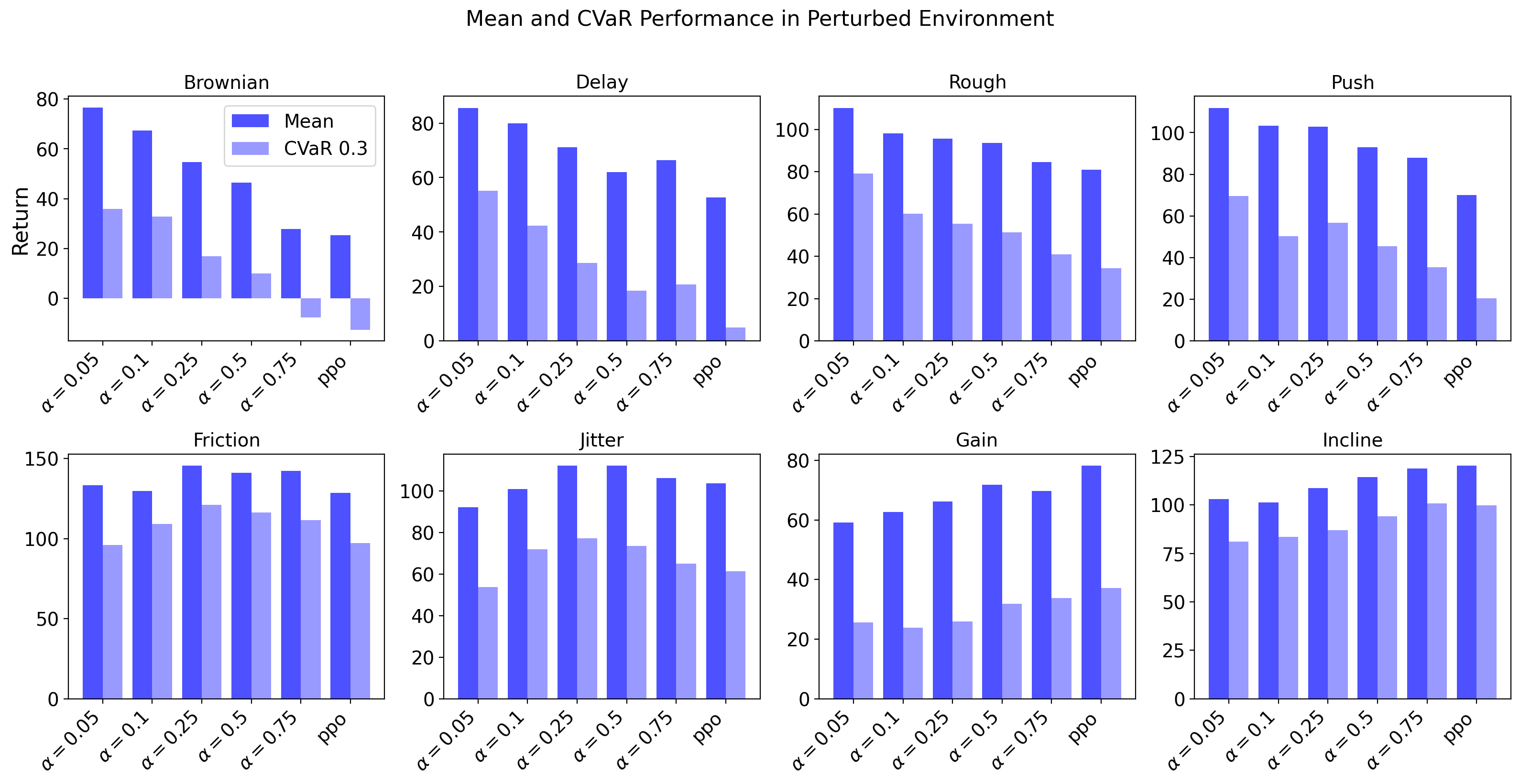
本文研究了用于四足机器人运动的风险感知强化学习。该方法使用条件风险价值(CVaR)约束的策略优化技术训练一系列风险条件策略,从而提高稳定性和样本效率。在部署时,我们使用多臂老虎机框架自适应地从策略族中选择性能最佳的策略,该框架仅使用观察到的情节回报,无需任何特权环境信息,并能动态适应未知条件。因此,我们使用CVaR训练具有不同鲁棒性水平的四足运动策略,并自适应地在线选择所需的鲁棒性水平,以确保在未知环境中的性能。我们在模拟中跨越八个未见过的设置(通过改变动力学、接触、传感噪声和地形)以及在Unitree Go2机器人上在先前未见过的地形中评估了我们的方法。与其它基线相比,我们的风险感知策略在未见过的环境中获得了近两倍的平均和尾部性能,并且我们的基于bandit的自适应在运行两分钟内在未知地形中选择了性能最佳的风险感知策略。
🔬 方法详解
问题定义:现有四足机器人运动的强化学习方法,在训练环境中表现良好,但在实际部署时,由于环境变化(如地形、动力学参数、传感器噪声等)的影响,性能会显著下降。现有的方法难以在保证平均性能的同时,兼顾运动的稳定性和鲁棒性,容易出现跌倒等问题。因此,需要一种能够在未知环境中自适应调整,并保证一定安全性的强化学习方法。
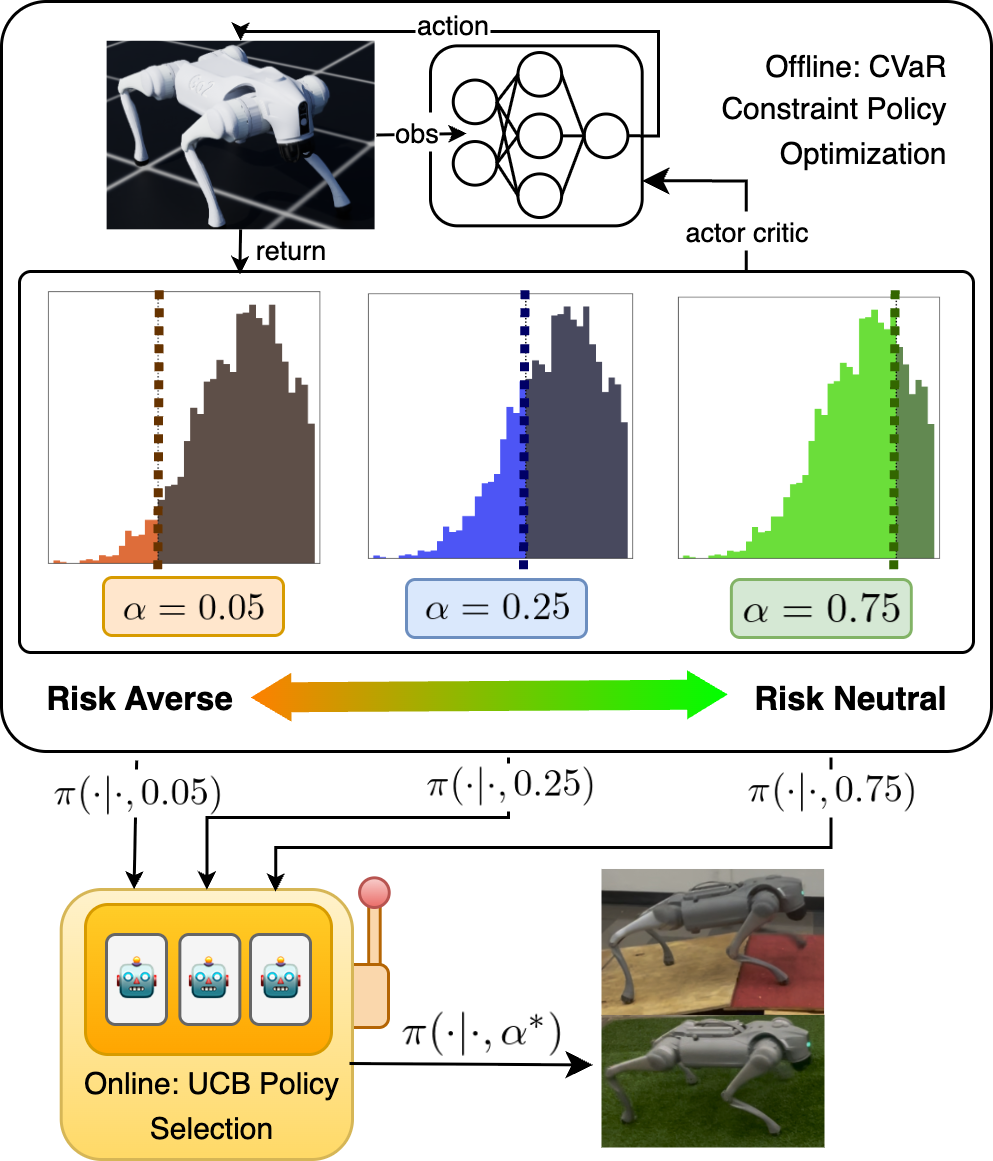
核心思路:本文的核心思路是训练一系列具有不同风险偏好的策略,并在部署时根据环境反馈自适应地选择合适的策略。通过CVaR(条件风险价值)来量化风险,并将其作为约束条件加入到策略优化过程中,从而得到一系列在不同风险水平下表现良好的策略。然后,利用多臂老虎机算法,根据在线观测到的回报,动态地选择当前环境下最优的策略,实现快速适应和鲁棒控制。
技术框架:整体框架包含两个主要阶段:1) 风险感知策略训练阶段:使用CVaR约束的策略优化算法,训练一系列具有不同风险偏好的策略。每个策略对应一个特定的风险水平。2) 在线自适应选择阶段:使用多臂老虎机算法,根据在线观测到的回报,动态地选择当前环境下最优的策略。该阶段不需要任何环境先验知识,仅依赖于观测到的回报。
关键创新:本文的关键创新在于将风险感知的概念引入到四足机器人强化学习中,并结合多臂老虎机算法实现了在线自适应。通过CVaR约束的策略优化,可以有效地控制策略的风险水平,提高策略的鲁棒性。而多臂老虎机算法则可以在未知环境中快速地选择合适的策略,实现自适应控制。这种结合使得机器人能够在各种复杂环境中保持稳定和高效的运动。
关键设计:CVaR的计算方式:采用蒙特卡洛采样方法估计CVaR。多臂老虎机算法:采用UCB(Upper Confidence Bound)算法进行策略选择,平衡探索和利用。奖励函数设计:奖励函数综合考虑了前进速度、能量消耗、姿态稳定性和动作平滑性等因素。网络结构:策略网络采用Actor-Critic结构,Actor网络输出动作,Critic网络评估状态价值。
🖼️ 关键图片
📊 实验亮点
在模拟环境中,该方法在八种未见过的设置下,相比于其他基线方法,平均性能和尾部性能提升了近两倍。在真实机器人Unitree Go2上的实验表明,该方法能够在未知地形中,在两分钟内自适应地选择最佳策略,并保持稳定的运动。
🎯 应用场景
该研究成果可应用于各种复杂地形下的四足机器人运动控制,例如搜索救援、物流运输、巡检等。通过自适应选择风险水平,机器人能够在保证安全性的前提下,高效地完成任务。此外,该方法还可以推广到其他类型的机器人和控制任务中,提高机器人的自主性和适应性。
📄 摘要(原文)
In this work, we study risk-aware reinforcement learning for quadrupedal locomotion. Our approach trains a family of risk-conditioned policies using a Conditional Value-at-Risk (CVaR) constrained policy optimization technique that provides improved stability and sample efficiency. At deployment, we adaptively select the best performing policy from the family of policies using a multi-armed bandit framework that uses only observed episodic returns, without any privileged environment information, and adapts to unknown conditions on the fly. Hence, we train quadrupedal locomotion policies at various levels of robustness using CVaR and adaptively select the desired level of robustness online to ensure performance in unknown environments. We evaluate our method in simulation across eight unseen settings (by changing dynamics, contacts, sensing noise, and terrain) and on a Unitree Go2 robot in previously unseen terrains. Our risk-aware policy attains nearly twice the mean and tail performance in unseen environments compared to other baselines and our bandit-based adaptation selects the best-performing risk-aware policy in unknown terrain within two minutes of operation.