Expertise need not monopolize: Action-Specialized Mixture of Experts for Vision-Language-Action Learning
作者: Weijie Shen, Yitian Liu, Yuhao Wu, Zhixuan Liang, Sijia Gu, Dehui Wang, Tian Nian, Lei Xu, Yusen Qin, Jiangmiao Pang, Xinping Guan, Xiaokang Yang, Yao Mu
分类: cs.RO, cs.AI
发布日期: 2025-10-16
💡 一句话要点
提出AdaMoE:一种动作专用混合专家模型,用于提升VLA模型的机器人操作性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 混合专家模型 机器人操作 预训练模型 模型扩展 动作专家 解耦技术
📋 核心要点
- 现有VLA模型扩展面临计算资源需求大和机器人数据稀缺的挑战,难以充分利用预训练权重。
- AdaMoE通过继承预训练权重并引入动作专用混合专家层,实现模型扩展和计算效率的平衡。
- 实验表明,AdaMoE在LIBERO、RoboTwin和真实世界机器人操作任务中均显著优于基线模型。
📝 摘要(中文)
视觉-语言-动作(VLA)模型正在快速发展,并在机器人操作任务中展现出良好的潜力。然而,扩展VLA模型面临几个关键挑战:(1)从头开始训练新的VLA模型需要大量的计算资源和广泛的数据集。鉴于目前机器人数据的稀缺性,在扩展过程中充分利用预训练的VLA模型权重变得尤为重要。(2)实时控制需要仔细平衡模型容量与计算效率。为了解决这些挑战,我们提出AdaMoE,一种混合专家(MoE)架构,它继承了密集VLA模型的预训练权重,并通过将前馈层替换为稀疏激活的MoE层来扩展动作专家。AdaMoE采用解耦技术,通过与传统路由选择器一起工作的独立缩放适配器将专家选择与专家加权解耦。这使得专家能够基于任务相关性进行选择,同时以独立控制的权重做出贡献,从而实现协作专家利用,而不是胜者全得的动态。我们的方法表明,专业知识不必垄断。相反,通过协作专家利用,我们可以在保持计算效率的同时实现卓越的性能。AdaMoE在关键基准测试中始终优于基线模型,在LIBERO上实现了1.8%的性能提升,在RoboTwin上实现了9.3%的性能提升。最重要的是,在真实世界实验中实现了21.5%的显著改进,验证了其在机器人操作任务中的实际有效性。
🔬 方法详解
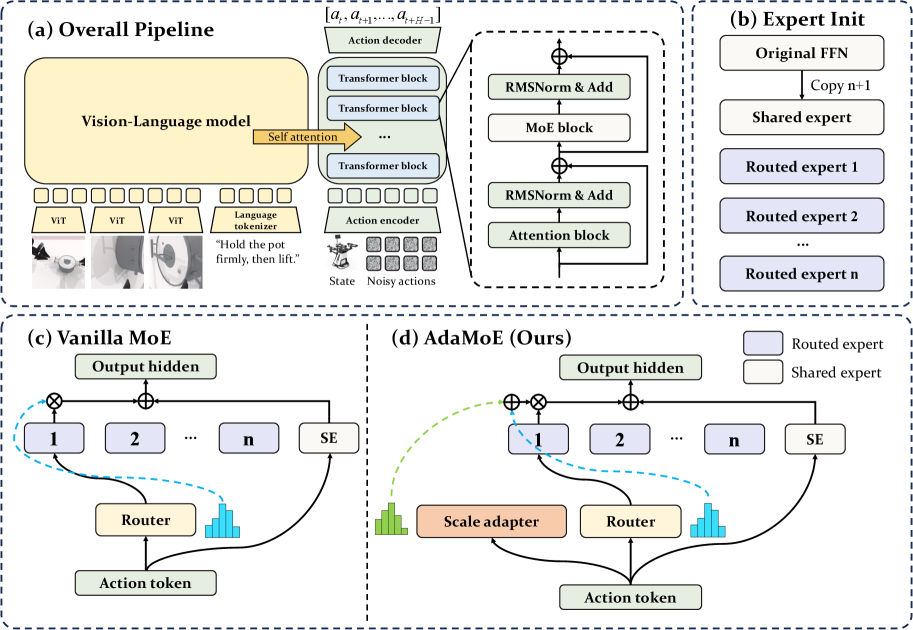
问题定义:现有视觉-语言-动作(VLA)模型在扩展时面临两个主要问题:一是训练成本高昂,需要大量计算资源和机器人数据;二是实时控制对计算效率有较高要求,需要平衡模型容量和计算复杂度。现有方法难以充分利用预训练模型权重,且难以在扩展模型容量的同时保证计算效率。
核心思路:AdaMoE的核心思路是利用混合专家(MoE)架构,并继承预训练VLA模型的权重。通过将动作专家中的前馈层替换为稀疏激活的MoE层,实现模型容量的扩展,同时保持计算效率。此外,AdaMoE引入解耦技术,将专家选择和专家加权分离,允许专家协同工作,避免“胜者全得”的局面。
技术框架:AdaMoE的整体架构基于现有的VLA模型,主要修改在于动作专家部分。具体流程如下:1. 继承预训练VLA模型的权重。2. 将动作专家中的前馈层替换为MoE层。3. 使用路由选择器(Router)选择激活的专家。4. 使用独立的缩放适配器(Scale Adapter)对专家的输出进行加权。5. 将加权后的专家输出进行组合,得到最终的动作预测。
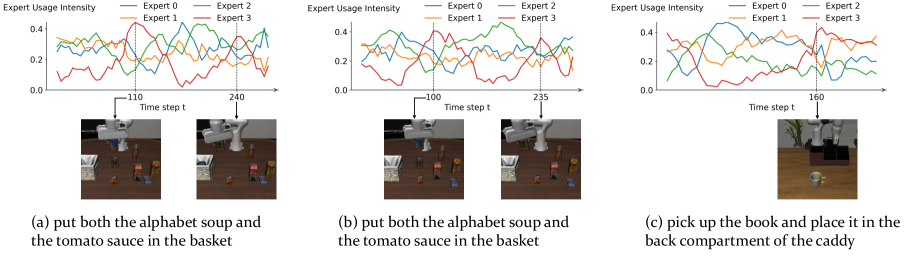
关键创新:AdaMoE的关键创新在于以下几点:1. 动作专用MoE:只在动作专家部分引入MoE,针对性地扩展动作表示能力。2. 解耦的专家选择和加权:通过独立的缩放适配器,允许专家基于任务相关性进行选择,并以独立控制的权重做出贡献,实现专家协同。3. 继承预训练权重:充分利用预训练VLA模型的知识,减少训练成本。
关键设计:AdaMoE的关键设计包括:1. 路由选择器:使用标准的Top-K路由选择器,选择K个最相关的专家。2. 缩放适配器:使用简单的线性层,对专家的输出进行缩放,学习每个专家的权重。3. 损失函数:使用标准的VLA模型损失函数,并添加正则化项,鼓励专家之间的多样性。
🖼️ 关键图片

📊 实验亮点
AdaMoE在LIBERO数据集上取得了1.8%的性能提升,在RoboTwin数据集上取得了9.3%的性能提升。更重要的是,在真实世界机器人操作实验中,AdaMoE取得了21.5%的显著改进,验证了其在实际应用中的有效性。这些结果表明,AdaMoE能够有效地提升VLA模型在机器人操作任务中的性能。
🎯 应用场景
AdaMoE可应用于各种机器人操作任务,例如物体抓取、放置、组装等。该方法能够提升机器人在复杂环境中的操作能力和泛化性能,降低机器人训练成本,加速机器人在工业、医疗、家庭服务等领域的应用。未来,该研究可以扩展到其他多模态任务,例如自动驾驶、智能助手等。
📄 摘要(原文)
Vision-Language-Action (VLA) models are experiencing rapid development and demonstrating promising capabilities in robotic manipulation tasks. However, scaling up VLA models presents several critical challenges: (1) Training new VLA models from scratch demands substantial computational resources and extensive datasets. Given the current scarcity of robot data, it becomes particularly valuable to fully leverage well-pretrained VLA model weights during the scaling process. (2) Real-time control requires carefully balancing model capacity with computational efficiency. To address these challenges, We propose AdaMoE, a Mixture-of-Experts (MoE) architecture that inherits pretrained weights from dense VLA models, and scales up the action expert by substituting the feedforward layers into sparsely activated MoE layers. AdaMoE employs a decoupling technique that decouples expert selection from expert weighting through an independent scale adapter working alongside the traditional router. This enables experts to be selected based on task relevance while contributing with independently controlled weights, allowing collaborative expert utilization rather than winner-takes-all dynamics. Our approach demonstrates that expertise need not monopolize. Instead, through collaborative expert utilization, we can achieve superior performance while maintaining computational efficiency. AdaMoE consistently outperforms the baseline model across key benchmarks, delivering performance gains of 1.8% on LIBERO and 9.3% on RoboTwin. Most importantly, a substantial 21.5% improvement in real-world experiments validates its practical effectiveness for robotic manipulation tasks.