ViTacGen: Robotic Pushing with Vision-to-Touch Generation
作者: Zhiyuan Wu, Yijiong Lin, Yongqiang Zhao, Xuyang Zhang, Zhuo Chen, Nathan Lepora, Shan Luo
分类: cs.RO
发布日期: 2025-10-15 (更新: 2025-10-23)
💡 一句话要点
ViTacGen:基于视觉到触觉生成的机器人推物操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人推物 视觉触觉融合 强化学习 视觉到触觉生成 对比学习
📋 核心要点
- 现有机器人推物操作依赖昂贵的触觉传感器,或面临纯视觉策略性能不足的挑战。
- ViTacGen通过视觉到触觉生成,将视觉信息转化为标准化的触觉表示,用于强化学习。
- 实验表明,ViTacGen在仿真和真实环境中均表现出色,成功率高达86%。
📝 摘要(中文)
机器人推物是一项基础操作任务,需要触觉反馈来捕捉末端执行器和物体之间细微的接触力和动力学。然而,真实的触觉传感器通常面临高成本、易损坏等硬件限制,以及标定和传感器差异带来的部署挑战。纯视觉策略难以达到令人满意的性能。受人类从视觉推断触觉状态能力的启发,我们提出了ViTacGen,一种新颖的机器人操作框架,用于视觉机器人推物,通过强化学习中的视觉到触觉生成来消除对高分辨率真实触觉传感器的依赖,从而在纯视觉机器人系统上实现有效的零样本部署。具体来说,ViTacGen包含一个编码器-解码器视觉到触觉生成网络,该网络直接从视觉图像序列生成接触深度图像(一种标准化的触觉表示),然后是一个强化学习策略,该策略基于视觉和生成的触觉观测,通过对比学习融合视觉-触觉数据。我们在仿真和真实世界实验中验证了我们方法的有效性,证明了其卓越的性能,并实现了高达86%的成功率。
🔬 方法详解
问题定义:论文旨在解决机器人推物任务中对昂贵且脆弱的触觉传感器的依赖问题。现有方法要么依赖于真实的触觉传感器,但成本高昂且难以部署;要么仅使用视觉信息,但性能难以满足实际需求,尤其是在需要精细控制的场景下。
核心思路:论文的核心思路是模仿人类从视觉信息推断触觉状态的能力,通过训练一个视觉到触觉的生成模型,将视觉信息转化为触觉信息的表示。这样,机器人就可以在没有真实触觉传感器的情况下,利用生成的触觉信息进行推物操作。
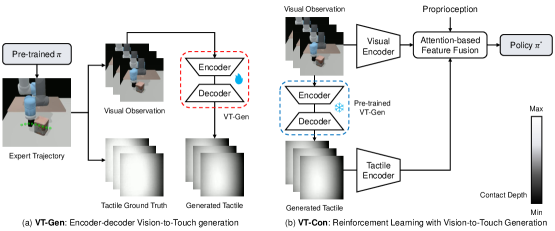
技术框架:ViTacGen框架主要包含两个模块:视觉到触觉生成网络和强化学习策略。首先,视觉到触觉生成网络(一个编码器-解码器结构)从视觉图像序列中生成接触深度图像,作为标准化的触觉表示。然后,强化学习策略将视觉信息和生成的触觉信息融合,通过对比学习来训练一个策略,控制机器人的推物动作。
关键创新:该论文的关键创新在于提出了一个视觉到触觉的生成模型,并将其与强化学习相结合,实现了在没有真实触觉传感器的情况下进行机器人推物操作。这种方法不仅降低了成本,还提高了系统的鲁棒性和泛化能力。
关键设计:视觉到触觉生成网络采用编码器-解码器结构,编码器提取视觉特征,解码器生成接触深度图像。强化学习策略使用对比学习来融合视觉和生成的触觉信息,损失函数包括强化学习的奖励函数和对比学习的损失函数。具体网络结构和参数设置在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
ViTacGen在仿真和真实世界实验中均取得了显著成果。在真实世界实验中,ViTacGen实现了高达86%的成功率,证明了其在复杂环境下的有效性。与仅使用视觉信息的基线方法相比,ViTacGen在性能上取得了显著提升,验证了视觉到触觉生成策略的优越性。
🎯 应用场景
ViTacGen具有广泛的应用前景,可应用于工业自动化、家庭服务机器人等领域。例如,在装配线上,机器人可以利用该技术进行精细的零件组装;在家庭环境中,机器人可以利用该技术进行物品整理和清洁。该研究降低了机器人对昂贵传感器的依赖,促进了机器人技术的普及。
📄 摘要(原文)
Robotic pushing is a fundamental manipulation task that requires tactile feedback to capture subtle contact forces and dynamics between the end-effector and the object. However, real tactile sensors often face hardware limitations such as high costs and fragility, and deployment challenges involving calibration and variations between different sensors, while vision-only policies struggle with satisfactory performance. Inspired by humans' ability to infer tactile states from vision, we propose ViTacGen, a novel robot manipulation framework designed for visual robotic pushing with vision-to-touch generation in reinforcement learning to eliminate the reliance on high-resolution real tactile sensors, enabling effective zero-shot deployment on visual-only robotic systems. Specifically, ViTacGen consists of an encoder-decoder vision-to-touch generation network that generates contact depth images, a standardized tactile representation, directly from visual image sequence, followed by a reinforcement learning policy that fuses visual-tactile data with contrastive learning based on visual and generated tactile observations. We validate the effectiveness of our approach in both simulation and real world experiments, demonstrating its superior performance and achieving a success rate of up to 86\%.