InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
作者: Xinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, Jiaya Jia, Weiyang Jin, Hao Li, Yao Mu, Jiangmiao Pang, Yu Qiao, Yang Tian, Bin Wang, Bolun Wang, Fangjing Wang, Hanqing Wang, Tai Wang, Ziqin Wang, Xueyuan Wei, Chao Wu, Shuai Yang, Jinhui Ye, Junqiu Yu, Jia Zeng, Jingjing Zhang, Jinyu Zhang, Shi Zhang, Feng Zheng, Bowen Zhou, Yangkun Zhu
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-10-15
备注: Technical report
🔗 代码/项目: GITHUB
💡 一句话要点
InternVLA-M1:面向通用机器人策略的空间引导视觉-语言-动作框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 视觉语言动作 空间推理 指令跟随 通用机器人
📋 核心要点
- 现有机器人指令跟随方法缺乏对空间信息的有效利用,限制了其泛化性和鲁棒性。
- InternVLA-M1通过空间引导的视觉-语言-动作训练,将指令与视觉空间位置对齐,实现更精确的动作控制。
- 实验表明,InternVLA-M1在多个机器人平台和任务中显著优于现有方法,尤其在长时程推理任务中提升显著。
📝 摘要(中文)
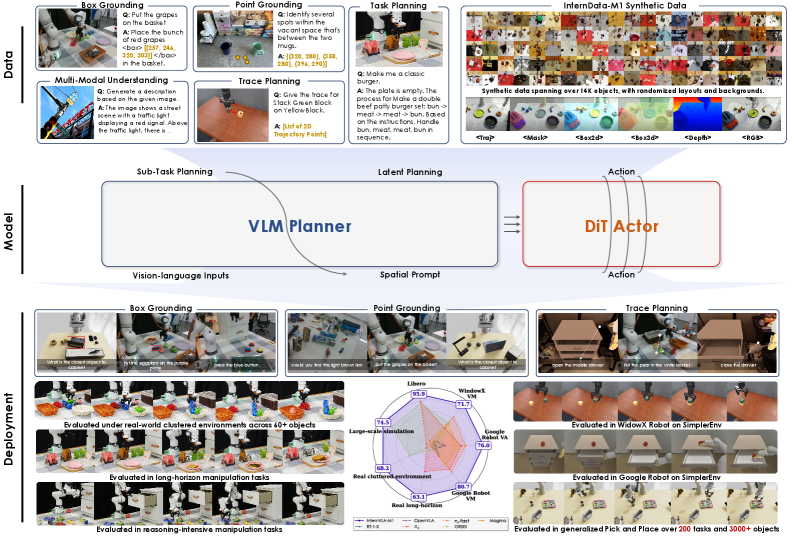
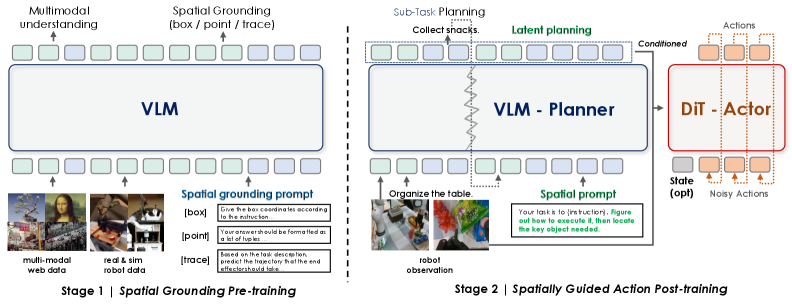
本文提出InternVLA-M1,一个用于空间定位和机器人控制的统一框架,旨在推动指令跟随机器人向可扩展的通用智能发展。其核心思想是空间引导的视觉-语言-动作训练,其中空间定位充当指令和机器人动作之间的关键连接。InternVLA-M1采用两阶段流程:(i)在超过230万个空间推理数据上进行空间定位预训练,通过将指令与视觉、与具体实现无关的位置对齐来确定“在哪里行动”;(ii)空间引导的动作后训练,通过即插即用的空间提示生成与具体实现相关的动作,从而决定“如何行动”。这种空间引导的训练方法产生了持续的收益:InternVLA-M1在SimplerEnv Google Robot上优于没有空间引导的变体+14.6%,在WidowX上+17%,在LIBERO Franka上+4.3%,同时在盒子、点和轨迹预测中表现出更强的空间推理能力。为了进一步扩展指令跟随,我们构建了一个仿真引擎来收集24.4万个可泛化的抓取和放置片段,从而在200个任务和3000多个对象上实现了6.2%的平均改进。在真实世界的集群抓取和放置中,InternVLA-M1提高了7.3%,通过合成协同训练,在未见过的对象和新颖配置上实现了+20.6%。此外,在长时程推理密集型场景中,它超过了现有工作10%以上。这些结果突出了空间引导训练作为可扩展和弹性通用机器人的统一原则。
🔬 方法详解
问题定义:现有机器人指令跟随方法在理解和执行指令时,往往忽略了指令中蕴含的空间信息,导致机器人难以准确地定位目标物体或执行特定位置相关的动作。此外,现有方法在不同机器人平台之间的泛化能力较弱,难以适应复杂多变的环境。
核心思路:InternVLA-M1的核心思路是利用空间引导的训练方式,将视觉信息、语言指令和机器人动作三者联系起来。通过学习指令与视觉空间位置之间的对应关系,机器人可以更准确地理解指令的意图,并生成相应的动作。这种方法强调空间信息的重要性,并将其作为连接指令和动作的关键桥梁。
技术框架:InternVLA-M1采用两阶段训练流程。第一阶段是空间定位预训练,利用大规模空间推理数据,训练模型学习将指令与视觉场景中的位置信息对齐。第二阶段是空间引导的动作后训练,利用预训练的空间定位模型,指导机器人生成具体的动作。该框架采用即插即用的空间提示,使得模型可以灵活地适应不同的机器人平台。
关键创新:InternVLA-M1的关键创新在于其空间引导的训练方法。与传统的端到端训练方法不同,InternVLA-M1显式地学习指令与空间位置之间的关系,从而提高了模型对空间信息的利用率。此外,该框架采用两阶段训练流程,将空间定位和动作生成解耦,使得模型可以更好地泛化到不同的任务和环境。
关键设计:在空间定位预训练阶段,论文使用了超过230万个空间推理数据。在动作后训练阶段,采用了空间提示机制,允许模型根据不同的机器人平台和任务动态地调整动作生成策略。损失函数的设计也考虑了空间信息的准确性,例如,使用了位置预测的损失函数来约束模型对目标位置的预测。
🖼️ 关键图片

📊 实验亮点
InternVLA-M1在多个机器人平台上取得了显著的性能提升。在SimplerEnv Google Robot上,相比没有空间引导的变体,性能提升了14.6%。在WidowX上,性能提升了17%。在LIBERO Franka上,性能提升了4.3%。此外,在真实世界的集群抓取和放置任务中,InternVLA-M1提高了7.3%,通过合成协同训练,在未见过的对象和新颖配置上实现了+20.6%的性能提升。
🎯 应用场景
InternVLA-M1具有广泛的应用前景,可应用于智能家居、工业自动化、医疗机器人等领域。例如,在智能家居中,机器人可以根据用户的语音指令,准确地抓取和放置物体。在工业自动化中,机器人可以执行复杂的装配和搬运任务。在医疗领域,机器人可以辅助医生进行手术和康复治疗。该研究有望推动机器人技术向更通用、更智能的方向发展。
📄 摘要(原文)
We introduce InternVLA-M1, a unified framework for spatial grounding and robot control that advances instruction-following robots toward scalable, general-purpose intelligence. Its core idea is spatially guided vision-language-action training, where spatial grounding serves as the critical link between instructions and robot actions. InternVLA-M1 employs a two-stage pipeline: (i) spatial grounding pre-training on over 2.3M spatial reasoning data to determine
where to act'' by aligning instructions with visual, embodiment-agnostic positions, and (ii) spatially guided action post-training to decidehow to act'' by generating embodiment-aware actions through plug-and-play spatial prompting. This spatially guided training recipe yields consistent gains: InternVLA-M1 outperforms its variant without spatial guidance by +14.6% on SimplerEnv Google Robot, +17% on WidowX, and +4.3% on LIBERO Franka, while demonstrating stronger spatial reasoning capability in box, point, and trace prediction. To further scale instruction following, we built a simulation engine to collect 244K generalizable pick-and-place episodes, enabling a 6.2% average improvement across 200 tasks and 3K+ objects. In real-world clustered pick-and-place, InternVLA-M1 improved by 7.3%, and with synthetic co-training, achieved +20.6% on unseen objects and novel configurations. Moreover, in long-horizon reasoning-intensive scenarios, it surpassed existing works by over 10%. These results highlight spatially guided training as a unifying principle for scalable and resilient generalist robots. Code and models are available at https://github.com/InternRobotics/InternVLA-M1.