Adversarial Fine-tuning in Offline-to-Online Reinforcement Learning for Robust Robot Control
作者: Shingo Ayabe, Hiroshi Kera, Kazuhiko Kawamoto
分类: cs.RO, cs.AI
发布日期: 2025-10-15
备注: 16 pages, 8 figures
💡 一句话要点
提出离线到在线的对抗微调方法,提升机器人控制对扰动的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 在线微调 对抗训练 鲁棒控制 机器人控制
📋 核心要点
- 离线强化学习虽然高效,但训练出的策略在面对执行器故障等扰动时表现脆弱,鲁棒性不足。
- 通过对抗微调,在动作中注入扰动,迫使策略学习补偿行为,从而提升对扰动的适应能力。
- 性能感知的课程学习策略,动态调整扰动概率,平衡了策略的鲁棒性和在无扰动下的性能。
📝 摘要(中文)
本文提出了一种离线到在线的强化学习框架,旨在提高机器人控制策略在存在执行器故障等扰动下的鲁棒性。该框架首先在干净的数据集上训练策略,然后进行对抗微调,即在执行的动作中注入扰动,以诱导补偿行为并提高策略的弹性。此外,引入了一种性能感知的课程学习方法,通过指数移动平均信号动态调整训练期间的扰动概率,从而平衡了鲁棒性和稳定性。在连续控制运动任务上的实验表明,所提出的方法始终优于仅离线训练的基线方法,并且比从头开始训练收敛更快。匹配微调和评估条件可以最大程度地提高对动作空间扰动的鲁棒性,而自适应课程策略可以减轻线性课程策略观察到的标称性能下降。总体而言,结果表明对抗微调能够实现不确定环境下的自适应和鲁棒控制,从而弥合了离线效率和在线适应性之间的差距。
🔬 方法详解
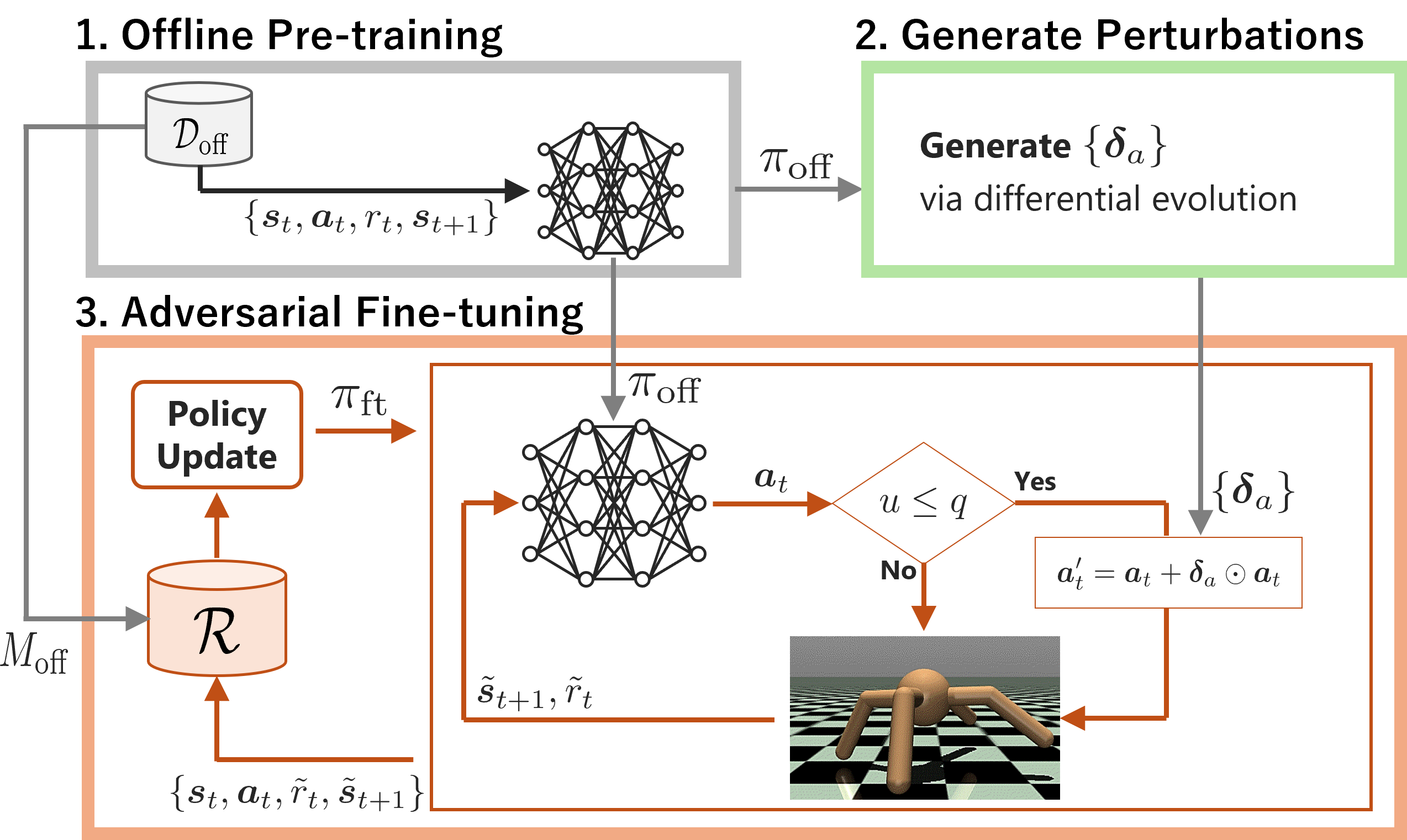
问题定义:离线强化学习虽然避免了在线探索的风险,但其训练的策略往往缺乏对环境扰动的鲁棒性,例如执行器故障。现有方法难以在保证性能的同时,提升策略在真实世界中的泛化能力。
核心思路:核心思想是通过对抗训练的方式,让策略在训练过程中暴露于各种扰动下,从而学习到对这些扰动的补偿行为。具体而言,在离线训练的基础上,通过在线微调,并向执行的动作中注入对抗性扰动,迫使策略适应这些扰动。
技术框架:该框架包含两个主要阶段:离线策略训练和在线对抗微调。首先,利用离线数据集训练一个初始策略。然后,在在线微调阶段,向策略输出的动作中添加扰动,并使用强化学习算法(如PPO)更新策略。为了平衡鲁棒性和性能,引入了性能感知的课程学习策略。
关键创新:关键创新在于将对抗训练的思想引入到离线到在线的强化学习框架中,并提出了一种性能感知的课程学习策略,能够自适应地调整扰动概率,从而在提高鲁棒性的同时,避免了性能的显著下降。
关键设计:性能感知的课程学习策略是关键设计之一。该策略使用指数移动平均(EMA)来估计策略的性能,并根据性能动态调整扰动概率。具体来说,如果策略性能下降,则降低扰动概率,反之则增加扰动概率。扰动的幅度可以设置为固定值或者根据某种分布进行采样。损失函数通常采用标准的强化学习损失函数,例如PPO的裁剪损失。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的对抗微调方法在连续控制运动任务中,显著提高了策略对动作空间扰动的鲁棒性。与仅离线训练的基线方法相比,该方法能够更快地收敛,并且在某些情况下,能够达到更高的性能。性能感知的课程学习策略有效地缓解了线性课程策略导致的性能下降问题。
🎯 应用场景
该研究成果可应用于各种需要高鲁棒性的机器人控制场景,例如自主导航、工业自动化和灾难救援。通过提高机器人对环境扰动的适应能力,可以显著提升其在复杂和不确定环境中的可靠性和安全性。未来,该方法有望推广到其他类型的扰动,例如传感器噪声和环境变化。
📄 摘要(原文)
Offline reinforcement learning enables sample-efficient policy acquisition without risky online interaction, yet policies trained on static datasets remain brittle under action-space perturbations such as actuator faults. This study introduces an offline-to-online framework that trains policies on clean data and then performs adversarial fine-tuning, where perturbations are injected into executed actions to induce compensatory behavior and improve resilience. A performance-aware curriculum further adjusts the perturbation probability during training via an exponential-moving-average signal, balancing robustness and stability throughout the learning process. Experiments on continuous-control locomotion tasks demonstrate that the proposed method consistently improves robustness over offline-only baselines and converges faster than training from scratch. Matching the fine-tuning and evaluation conditions yields the strongest robustness to action-space perturbations, while the adaptive curriculum strategy mitigates the degradation of nominal performance observed with the linear curriculum strategy. Overall, the results show that adversarial fine-tuning enables adaptive and robust control under uncertain environments, bridging the gap between offline efficiency and online adaptability.