RoboHiMan: A Hierarchical Evaluation Paradigm for Compositional Generalization in Long-Horizon Manipulation
作者: Yangtao Chen, Zixuan Chen, Nga Teng Chan, Junting Chen, Junhui Yin, Jieqi Shi, Yang Gao, Yong-Lu Li, Jing Huo
分类: cs.RO
发布日期: 2025-10-15
备注: Under review. These first two authors contributed equally to this work
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出RoboHiMan,用于评估长时程操作中组合泛化的分层框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长时程操作 组合泛化 分层评估 机器人操作 基准测试
📋 核心要点
- 现有端到端模型在长时程操作任务中泛化能力不足,分层方法在复杂扰动下技能组合能力受限。
- RoboHiMan通过HiMan-Bench基准和三种评估范式,系统性地评估组合泛化、鲁棒性以及规划与执行的相互作用。
- 实验结果揭示了现有模型在长时程操作任务中的能力差距,为未来模型设计提供了指导。
📝 摘要(中文)
本文提出RoboHiMan,一个用于评估长时程操作中组合泛化的分层评估范式。现有端到端视觉语言动作模型在训练分布外泛化能力有限。分层方法虽有改进,但在复杂扰动下仍表现出技能组合能力不足。现有基准测试主要关注长时程任务完成,缺乏对组合泛化、鲁棒性以及规划与执行之间相互作用的深入研究。RoboHiMan引入HiMan-Bench,一个包含原子和组合任务的基准,支持多层次训练数据集以分析渐进式数据缩放。同时,提出了三种评估范式(vanilla, decoupled, coupled),用于探究技能组合的必要性并揭示分层架构中的瓶颈。实验结果表明,代表性模型和架构存在明显的能力差距,为改进更适合真实世界长时程操作任务的模型指明了方向。
🔬 方法详解
问题定义:现有长时程操作任务的组合泛化能力评估不足,尤其是在存在复杂扰动的情况下。现有的端到端模型难以泛化到训练分布之外,而分层方法虽然有所改进,但在技能组合方面仍然存在局限性。现有基准测试主要关注任务完成,缺乏对组合泛化、鲁棒性以及规划与执行之间相互作用的深入分析。
核心思路:RoboHiMan的核心思路是通过构建一个分层评估范式,系统性地评估模型在长时程操作任务中的组合泛化能力。该范式包含一个精心设计的基准测试HiMan-Bench,以及三种不同的评估策略,旨在揭示分层架构中的瓶颈,并为未来的模型设计提供指导。
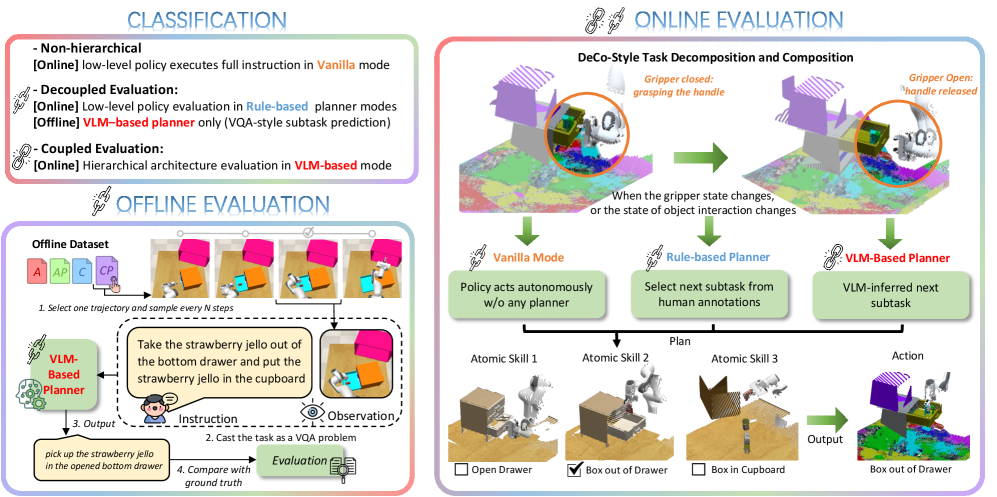
技术框架:RoboHiMan的技术框架主要包含三个部分:1) HiMan-Bench基准测试,包含原子和组合任务,并提供多层次训练数据集;2) 三种评估范式(vanilla, decoupled, coupled),用于探究技能组合的必要性;3) 实验评估,通过在代表性模型和架构上进行实验,分析其在组合泛化方面的能力差距。
关键创新:RoboHiMan的关键创新在于其系统性的评估范式,能够深入分析模型在长时程操作任务中的组合泛化能力。HiMan-Bench基准测试提供了多样化的任务和扰动,能够更全面地评估模型的鲁棒性。三种评估范式能够分别考察模型的整体性能、规划能力和执行能力,从而更精确地定位模型的瓶颈。
关键设计:HiMan-Bench基准测试包含多种原子任务和组合任务,任务难度可调,并引入了多种扰动,例如物体位置变化、光照变化等。三种评估范式分别从不同角度评估模型的性能:vanilla评估直接评估模型的整体性能;decoupled评估将规划和执行分离,分别评估其性能;coupled评估则考察规划和执行之间的相互作用。
🖼️ 关键图片
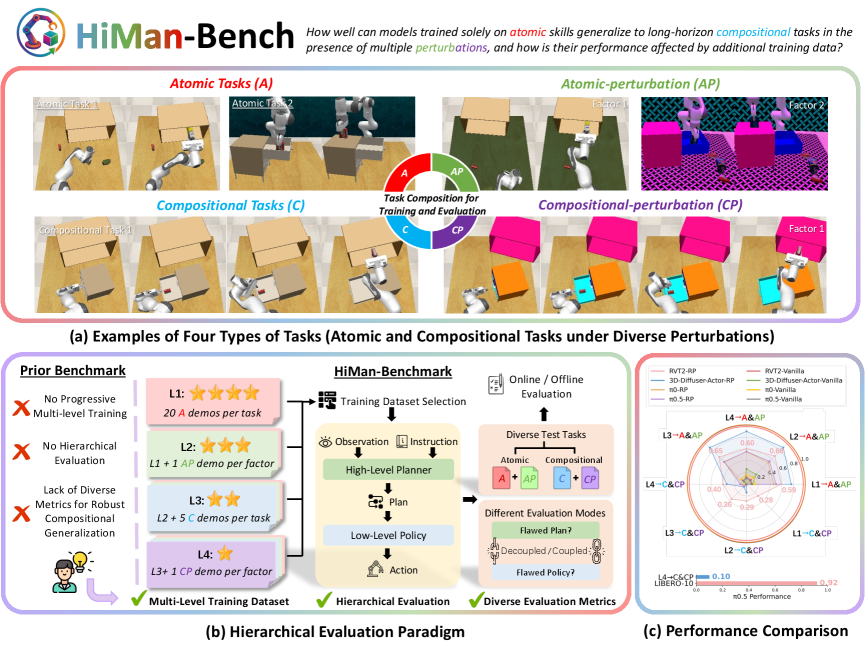

📊 实验亮点
实验结果表明,现有代表性模型和架构在RoboHiMan基准测试中存在明显的能力差距,尤其是在复杂扰动和长时程任务中。例如,端到端模型在组合任务中的性能显著低于分层模型,但分层模型在规划和执行的相互作用方面仍存在瓶颈。这些实验结果为未来的模型设计提供了重要的参考依据。
🎯 应用场景
RoboHiMan的研究成果可应用于机器人操作、自动化生产线、智能家居等领域。通过提高机器人在复杂环境下的操作能力,可以实现更高效、更灵活的自动化生产,并为人们提供更智能、更便捷的生活服务。该研究还有助于推动机器人技术在医疗、救援等领域的应用。
📄 摘要(原文)
Enabling robots to flexibly schedule and compose learned skills for novel long-horizon manipulation under diverse perturbations remains a core challenge. Early explorations with end-to-end VLA models show limited success, as these models struggle to generalize beyond the training distribution. Hierarchical approaches, where high-level planners generate subgoals for low-level policies, bring certain improvements but still suffer under complex perturbations, revealing limited capability in skill composition. However, existing benchmarks primarily emphasize task completion in long-horizon settings, offering little insight into compositional generalization, robustness, and the interplay between planning and execution. To systematically investigate these gaps, we propose RoboHiMan, a hierarchical evaluation paradigm for compositional generalization in long-horizon manipulation. RoboHiMan introduces HiMan-Bench, a benchmark of atomic and compositional tasks under diverse perturbations, supported by a multi-level training dataset for analyzing progressive data scaling, and proposes three evaluation paradigms (vanilla, decoupled, coupled) that probe the necessity of skill composition and reveal bottlenecks in hierarchical architectures. Experiments highlight clear capability gaps across representative models and architectures, pointing to directions for advancing models better suited to real-world long-horizon manipulation tasks. Videos and open-source code can be found on our project website: https://chenyt31.github.io/robo-himan.github.io/.