VLA-0: Building State-of-the-Art VLAs with Zero Modification
作者: Ankit Goyal, Hugo Hadfield, Xuning Yang, Valts Blukis, Fabio Ramos
分类: cs.RO, cs.AI
发布日期: 2025-10-15
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
VLA-0:零修改构建最先进的视觉-语言-动作模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人操作 零修改 文本表示 预训练模型
📋 核心要点
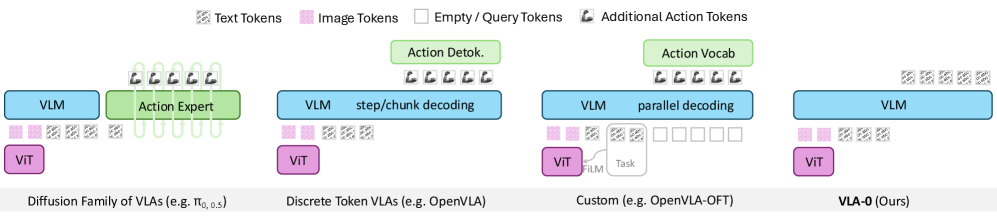
- 现有VLA模型构建方法复杂,例如修改VLM词汇或引入动作头,缺乏对简单文本表示动作的探索。
- VLA-0的核心思想是将动作直接表示为文本,避免对现有VLM进行修改,简化模型设计。
- 实验表明,VLA-0在LIBERO基准上超越了其他VLA模型,无需大规模机器人数据训练也能取得优异性能。
📝 摘要(中文)
视觉-语言-动作模型(VLA)在实现通用机器人操作方面具有巨大潜力。然而,构建它们的最佳方式仍然是一个开放的问题。目前的方法通常增加复杂性,例如用动作token修改现有视觉-语言模型(VLM)的词汇表或引入特殊的动作头。令人惊讶的是,直接将动作表示为文本的最简单策略在很大程度上仍未被探索。这项工作介绍了VLA-0来研究这个想法。我们发现VLA-0不仅有效,而且非常强大。通过正确的设计,VLA-0优于更复杂的模型。在LIBERO上,一个用于评估VLA的流行基准,VLA-0优于所有使用相同机器人数据训练的现有方法,包括$π_0.5$-KI、OpenVLA-OFT和SmolVLA。此外,在没有大规模机器人特定训练的情况下,它优于使用大规模机器人数据训练的方法,如$π_0.5$-KI、$π_0$、GR00T-N1和MolmoAct。这些发现也适用于现实世界,VLA-0优于SmolVLA,这是一个在大型真实数据上预训练的VLA模型。本文总结了我们意想不到的发现,并阐明了解锁这种简单而强大的VLA设计的高性能所需的特定技术。
🔬 方法详解
问题定义:论文旨在解决如何以更简单有效的方式构建视觉-语言-动作模型(VLA)的问题。现有VLA模型通常通过修改视觉-语言模型(VLM)的词汇表或引入专门的动作头来集成动作信息,增加了模型的复杂性,并且可能限制了VLM的通用性。
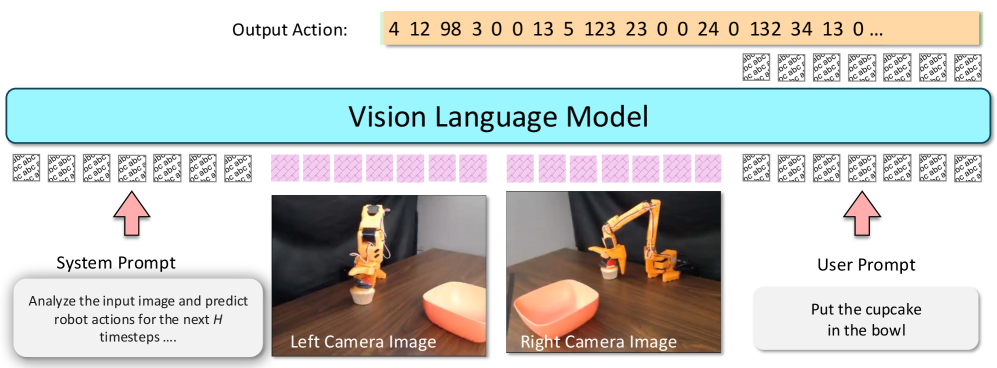
核心思路:论文的核心思路是将动作直接表示为文本,利用VLM强大的文本理解能力来处理动作指令。这种方法避免了对VLM结构的修改,保持了模型的简洁性和通用性,同时允许VLA模型利用预训练VLM的知识。
技术框架:VLA-0模型的核心是利用预训练的VLM,例如CLIP或类似的模型。视觉输入通过视觉编码器转换为视觉特征,文本指令(包括动作描述)通过文本编码器转换为文本特征。然后,模型通过对比学习或其他方式将视觉特征和文本特征对齐,从而学习将视觉场景与相应的动作指令关联起来。模型的输出是执行动作的概率或参数。
关键创新:VLA-0的关键创新在于其极简的设计理念,即“零修改”。它避免了对现有VLM的任何修改,而是直接利用VLM的文本理解能力来处理动作指令。这种方法简化了VLA模型的构建过程,并使其更容易利用预训练VLM的知识。
关键设计:VLA-0的关键设计包括:1) 使用预训练的VLM作为基础模型;2) 将动作指令表示为文本;3) 使用对比学习或其他方法对齐视觉特征和文本特征;4) 设计合适的损失函数来优化模型的性能。具体的参数设置和网络结构可能因所使用的VLM而异,但核心思想保持不变。
🖼️ 关键图片

📊 实验亮点
VLA-0在LIBERO基准测试中超越了所有使用相同机器人数据训练的现有方法,包括$π_0.5$-KI、OpenVLA-OFT和SmolVLA。更重要的是,在没有大规模机器人特定训练的情况下,VLA-0的性能优于使用大规模机器人数据训练的方法,如$π_0.5$-KI、$π_0$、GR00T-N1和MolmoAct。在真实世界实验中,VLA-0也优于SmolVLA,后者是一个在大型真实数据上预训练的VLA模型。
🎯 应用场景
VLA-0具有广泛的应用前景,可用于机器人操作、自动化控制、人机交互等领域。例如,它可以应用于家庭服务机器人,使其能够根据用户的自然语言指令执行各种任务,如清洁、整理物品等。此外,VLA-0还可以用于工业自动化,提高生产效率和灵活性。该研究的未来影响在于推动通用机器人技术的发展,使机器人能够更好地理解和执行人类的指令。
📄 摘要(原文)
Vision-Language-Action models (VLAs) hold immense promise for enabling generalist robot manipulation. However, the best way to build them remains an open question. Current approaches often add complexity, such as modifying the existing vocabulary of a Vision-Language Model (VLM) with action tokens or introducing special action heads. Curiously, the simplest strategy of representing actions directly as text has remained largely unexplored. This work introduces VLA-0 to investigate this idea. We find that VLA-0 is not only effective; it is surprisingly powerful. With the right design, VLA-0 outperforms more involved models. On LIBERO, a popular benchmark for evaluating VLAs, VLA-0 outperforms all existing methods trained on the same robotic data, including $π_0.5$-KI, OpenVLA-OFT and SmolVLA. Furthermore, without large-scale robotics-specific training, it outperforms methods trained on large-scale robotic data, like $π_0.5$-KI, $π_0$, GR00T-N1 and MolmoAct. These findings also translate to the real world, where VLA-0 outperforms SmolVLA, a VLA model pre-trained on large-scale real data. This paper summarizes our unexpected findings and spells out the specific techniques required to unlock the high performance of this simple yet potent VLA design. Visual results, code, and trained models are provided here: https://vla0.github.io/.