Actron3D: Learning Actionable Neural Functions from Videos for Transferable Robotic Manipulation
作者: Anran Zhang, Hanzhi Chen, Yannick Burkhardt, Yao Zhong, Johannes Betz, Helen Oleynikova, Stefan Leutenegger
分类: cs.RO
发布日期: 2025-10-14
备注: 8 pages, 5 figures
💡 一句话要点
Actron3D:从少量视频学习可迁移的机器人操作技能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 可迁移学习 神经可供性 视频学习 6自由度操作
📋 核心要点
- 现有机器人操作方法需要大量数据或复杂的校准,限制了其在真实场景中的应用。
- Actron3D通过神经可供性函数,将视频中的几何、外观和可供性信息压缩到轻量级网络中。
- 实验表明,Actron3D仅需少量演示视频即可显著提升操作成功率,优于现有方法。
📝 摘要(中文)
Actron3D是一个框架,它使机器人能够仅从几个单目、未校准的RGB人类视频中获得可迁移的6自由度操作技能。其核心是神经可供性函数,这是一种紧凑的、以对象为中心的表示,它将来自各种未校准视频(几何形状、视觉外观和可供性)的可操作线索提炼成一个轻量级的神经网络,形成操作技能的记忆库。在部署期间,我们采用一种管道,该管道检索相关的可供性函数,并通过粗到精的优化传递精确的6自由度操作策略,这得益于对神经函数中编码的多模态特征的连续查询。在模拟和真实世界的实验表明,Actron3D显著优于先前的方法,在13个任务中的平均成功率提高了14.9个百分点,而每个任务仅需要2-3个演示视频。
🔬 方法详解
问题定义:现有机器人操作方法通常需要大量的训练数据,或者依赖于精确的相机校准和环境建模。这使得它们难以适应新的任务和环境,泛化能力较差。此外,从人类演示中学习操作技能也面临着视角差异、动作模糊等挑战。
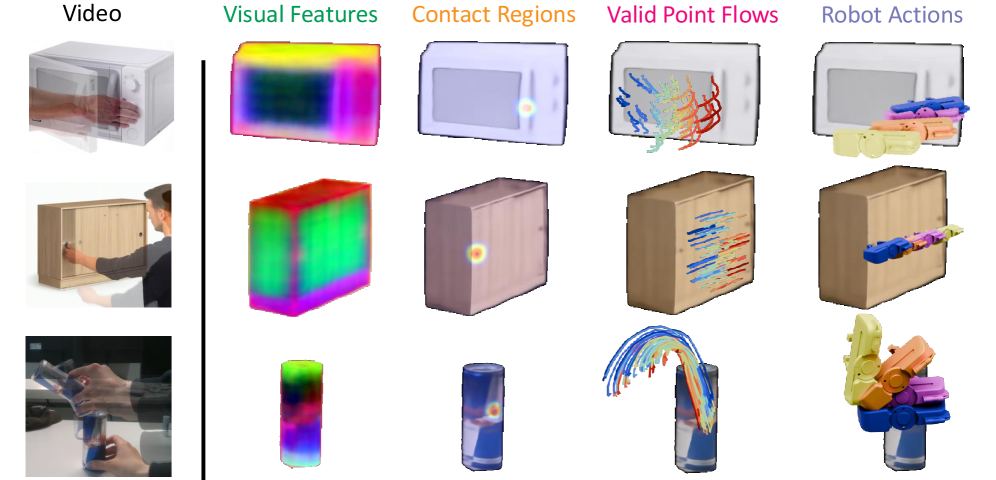
核心思路:Actron3D的核心思想是学习一种通用的、可迁移的“神经可供性函数”。该函数能够从少量未校准的RGB视频中提取关键的操作信息(几何、外观、可供性),并将其编码到一个轻量级的神经网络中。这样,机器人就可以通过查询该函数,快速适应新的操作任务。
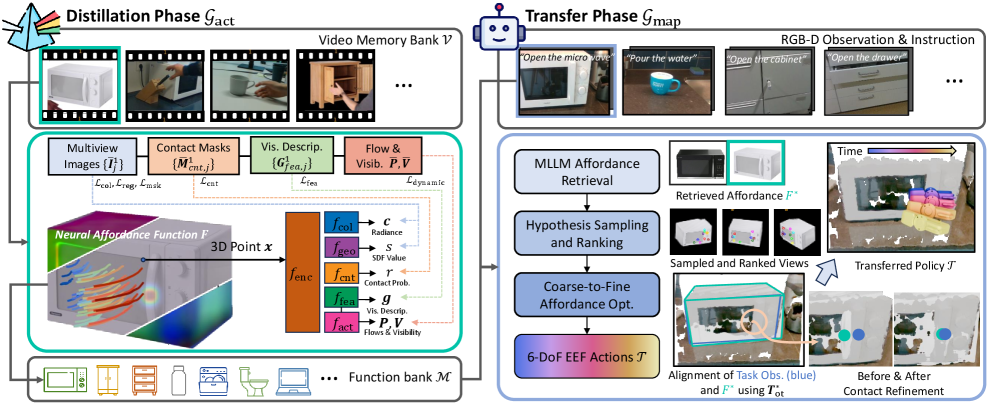
技术框架:Actron3D的整体框架包括三个主要阶段:1) 数据收集:收集少量(2-3个)人类操作的RGB视频,无需校准。2) 神经可供性函数学习:使用视频数据训练神经可供性函数,该函数将对象的三维几何、视觉外观和可供性信息编码到神经网络中。3) 操作策略优化:在新的任务中,检索相关的可供性函数,并通过粗到精的优化方法,生成精确的6自由度操作策略。
关键创新:Actron3D的关键创新在于神经可供性函数的表示方法。它将多种模态的信息(几何、外观、可供性)融合到一个紧凑的神经网络中,实现了高效的知识迁移。此外,该方法不需要精确的相机校准,降低了部署难度。
关键设计:神经可供性函数采用了一种对象中心的表示方法,即以操作对象为中心,提取其局部特征。损失函数的设计考虑了操作的成功率和动作的平滑性。粗到精的优化策略首先进行全局搜索,然后进行局部微调,提高了操作的精度和效率。
🖼️ 关键图片

📊 实验亮点
Actron3D在模拟和真实世界的实验中都取得了显著的成果。在13个不同的操作任务中,Actron3D的平均成功率比现有方法提高了14.9个百分点,并且每个任务仅需要2-3个演示视频。这表明Actron3D具有很强的泛化能力和数据效率。
🎯 应用场景
Actron3D具有广泛的应用前景,例如在家庭服务机器人、工业自动化、医疗辅助机器人等领域。它可以帮助机器人快速学习新的操作技能,适应不同的环境和任务,从而提高机器人的智能化水平和实用性。未来,该技术有望应用于更复杂的机器人操作任务,例如装配、拆卸、维修等。
📄 摘要(原文)
We present Actron3D, a framework that enables robots to acquire transferable 6-DoF manipulation skills from just a few monocular, uncalibrated, RGB-only human videos. At its core lies the Neural Affordance Function, a compact object-centric representation that distills actionable cues from diverse uncalibrated videos-geometry, visual appearance, and affordance-into a lightweight neural network, forming a memory bank of manipulation skills. During deployment, we adopt a pipeline that retrieves relevant affordance functions and transfers precise 6-DoF manipulation policies via coarse-to-fine optimization, enabled by continuous queries to the multimodal features encoded in the neural functions. Experiments in both simulation and the real world demonstrate that Actron3D significantly outperforms prior methods, achieving a 14.9 percentage point improvement in average success rate across 13 tasks while requiring only 2-3 demonstration videos per task.