Learning to Grasp Anything by Playing with Random Toys
作者: Dantong Niu, Yuvan Sharma, Baifeng Shi, Rachel Ding, Matteo Gioia, Haoru Xue, Henry Tsai, Konstantinos Kallidromitis, Anirudh Pai, Shankar Shastry, Trevor Darrell, Jitendra Malik, Roei Herzig
分类: cs.RO, cs.CV
发布日期: 2025-10-14
💡 一句话要点
通过与随机玩具互动学习抓取:提升机器人抓取泛化能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人抓取 零样本学习 泛化能力 物体表示 深度学习
📋 核心要点
- 现有机器人操作策略在面对新物体时泛化能力不足,限制了其在实际场景中的应用。
- 本文提出一种基于随机组装玩具的训练方法,学习以物体为中心的视觉表示,提升抓取泛化能力。
- 实验结果表明,该方法在真实机器人上对YCB数据集的零样本抓取成功率达到67%,优于现有方法。
📝 摘要(中文)
机器人操作策略通常难以泛化到新物体,限制了其在现实世界中的应用。受认知科学启发,本文研究机器人是否可以通过掌握少量简单玩具,并将知识应用于更复杂的物品,从而获得类似的可泛化灵巧操作技能。结果表明,机器人可以通过使用由球体、长方体、圆柱体和环形四种基本形状组成的随机组装物体进行训练,学习到可泛化的抓取能力。在这些“玩具”上训练的模型能够鲁棒地泛化到真实世界的物体,产生强大的零样本性能。关键在于,这种泛化的关键是本文提出的检测池化机制所诱导的以物体为中心的视觉表示。在模拟和物理机器人上的评估表明,该模型在YCB数据集上实现了67%的真实世界抓取成功率,优于依赖更多领域内数据的最先进方法。本文进一步研究了零样本泛化性能如何随着训练玩具的数量和多样性以及每个玩具的演示次数而变化。这项工作为机器人操作中可扩展和可泛化的学习提供了一条有希望的途径。
🔬 方法详解
问题定义:现有机器人抓取方法难以泛化到未见过的物体,需要大量特定领域的数据进行训练,成本高昂且泛化性差。痛点在于缺乏一种通用的、鲁棒的物体表示方法,使得机器人能够理解和适应不同形状、大小和材质的物体。
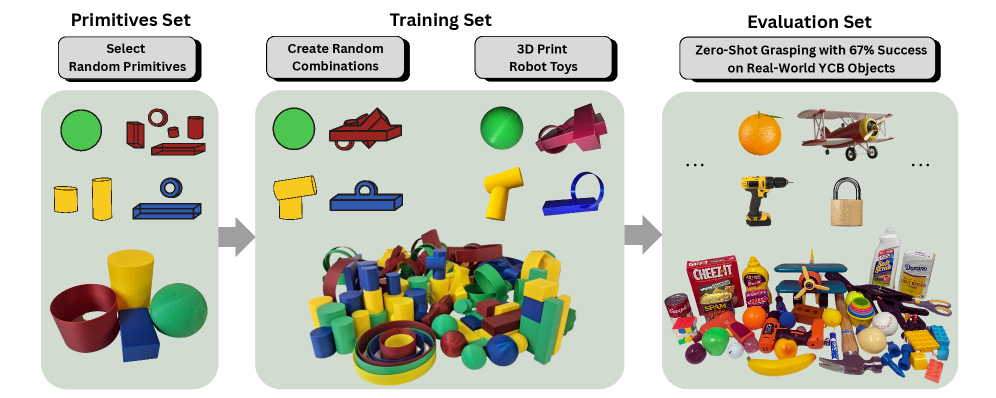
核心思路:借鉴儿童通过玩玩具学习操作技能的认知过程,本文提出使用随机组装的简单“玩具”进行训练,这些玩具由基本的几何形状组成。核心思想是,通过在这些简单物体上学习,机器人可以获得一种通用的、以物体为中心的视觉表示,从而能够泛化到更复杂的真实物体。
技术框架:整体框架包括数据生成、模型训练和评估三个阶段。首先,随机生成由基本几何形状组成的玩具,并收集抓取数据。然后,使用这些数据训练一个抓取模型,该模型包含一个视觉编码器和一个抓取策略网络。视觉编码器负责提取以物体为中心的视觉特征,抓取策略网络则根据这些特征生成抓取动作。最后,在真实世界的物体上评估模型的零样本抓取性能。
关键创新:最重要的创新点在于提出的“检测池化”机制,用于学习以物体为中心的视觉表示。与传统的图像级特征提取方法不同,检测池化首先检测图像中的各个几何形状,然后将这些形状的特征进行池化,得到一个描述整个物体的特征向量。这种方法能够更好地捕捉物体的结构信息,从而提高抓取泛化能力。与现有方法的本质区别在于,本文的方法不依赖于特定物体的3D模型或大量领域内数据,而是通过学习通用的几何形状表示来实现泛化。
关键设计:视觉编码器采用卷积神经网络(CNN)提取图像特征。检测器使用预训练的物体检测模型(如Faster R-CNN)检测图像中的几何形状。池化操作将检测到的形状特征进行最大池化或平均池化,得到物体级别的特征向量。抓取策略网络采用深度神经网络,输入物体特征向量,输出抓取动作的参数(如抓取位置、角度和力度)。损失函数包括抓取成功率损失和正则化损失,用于优化模型参数。
🖼️ 关键图片


📊 实验亮点
该模型在真实机器人上对YCB数据集进行了零样本抓取测试,成功率达到67%,显著优于现有方法。与需要大量领域内数据训练的方法相比,该方法仅使用随机生成的玩具数据进行训练,即可实现更好的泛化性能。实验还表明,增加训练玩具的数量和多样性可以进一步提高抓取成功率。
🎯 应用场景
该研究成果可应用于各种需要机器人进行物体抓取的场景,例如:智能仓储、自动化生产线、家庭服务机器人等。通过提升机器人抓取的泛化能力,可以降低对特定环境和物体的依赖,提高机器人的适应性和灵活性,从而实现更广泛的应用。
📄 摘要(原文)
Robotic manipulation policies often struggle to generalize to novel objects, limiting their real-world utility. In contrast, cognitive science suggests that children develop generalizable dexterous manipulation skills by mastering a small set of simple toys and then applying that knowledge to more complex items. Inspired by this, we study if similar generalization capabilities can also be achieved by robots. Our results indicate robots can learn generalizable grasping using randomly assembled objects that are composed from just four shape primitives: spheres, cuboids, cylinders, and rings. We show that training on these "toys" enables robust generalization to real-world objects, yielding strong zero-shot performance. Crucially, we find the key to this generalization is an object-centric visual representation induced by our proposed detection pooling mechanism. Evaluated in both simulation and on physical robots, our model achieves a 67% real-world grasping success rate on the YCB dataset, outperforming state-of-the-art approaches that rely on substantially more in-domain data. We further study how zero-shot generalization performance scales by varying the number and diversity of training toys and the demonstrations per toy. We believe this work offers a promising path to scalable and generalizable learning in robotic manipulation. Demonstration videos, code, checkpoints and our dataset are available on our project page: https://lego-grasp.github.io/ .