Residual MPC: Blending Reinforcement Learning with GPU-Parallelized Model Predictive Control
作者: Se Hwan Jeon, Ho Jae Lee, Seungwoo Hong, Sangbae Kim
分类: cs.RO
发布日期: 2025-10-14
备注: TRO submission preprint
💡 一句话要点
提出GPU并行残差MPC,融合强化学习与模型预测控制提升机器人运动控制性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模型预测控制 强化学习 残差学习 机器人控制 GPU并行化
📋 核心要点
- 传统MPC依赖频繁重规划,易受模型失配和实时计算约束限制,鲁棒性不足。
- 该论文提出一种残差架构,通过强化学习策略对MPC输出进行修正,融合二者优势。
- 实验表明,该方法在样本效率、奖励收敛、速度跟踪和零样本泛化等方面优于独立MPC和端到端RL。
📝 摘要(中文)
本文提出了一种GPU并行残差架构,将模型预测控制(MPC)与强化学习(RL)紧密结合,在扭矩控制层面融合二者的输出。开发了一种运动学全身MPC公式,在100Hz频率下并行评估数千个智能体,用于强化学习训练。残差策略学习对MPC输出进行有针对性的修正,结合了基于模型的控制的可解释性和约束处理能力与RL的适应性。基于模型的控制先验作为一个强偏差,通过一组简单的奖励来初始化和引导策略朝着期望的行为发展。与独立的MPC或端到端RL相比,该方法实现了更高的样本效率,收敛到更大的渐近奖励,扩大了可跟踪的速度指令范围,并实现了对未见过的步态和不平坦地形的零样本适应。
🔬 方法详解
问题定义:现有的模型预测控制(MPC)方法在机器人运动控制中面临鲁棒性问题,主要原因是模型不准确以及实时计算能力的限制。强化学习(RL)虽然可以学习到鲁棒的策略,但通常缺乏可解释性,容易出现分布外失效,并且需要大量的奖励工程。因此,如何结合MPC的可解释性和RL的适应性,是一个亟待解决的问题。
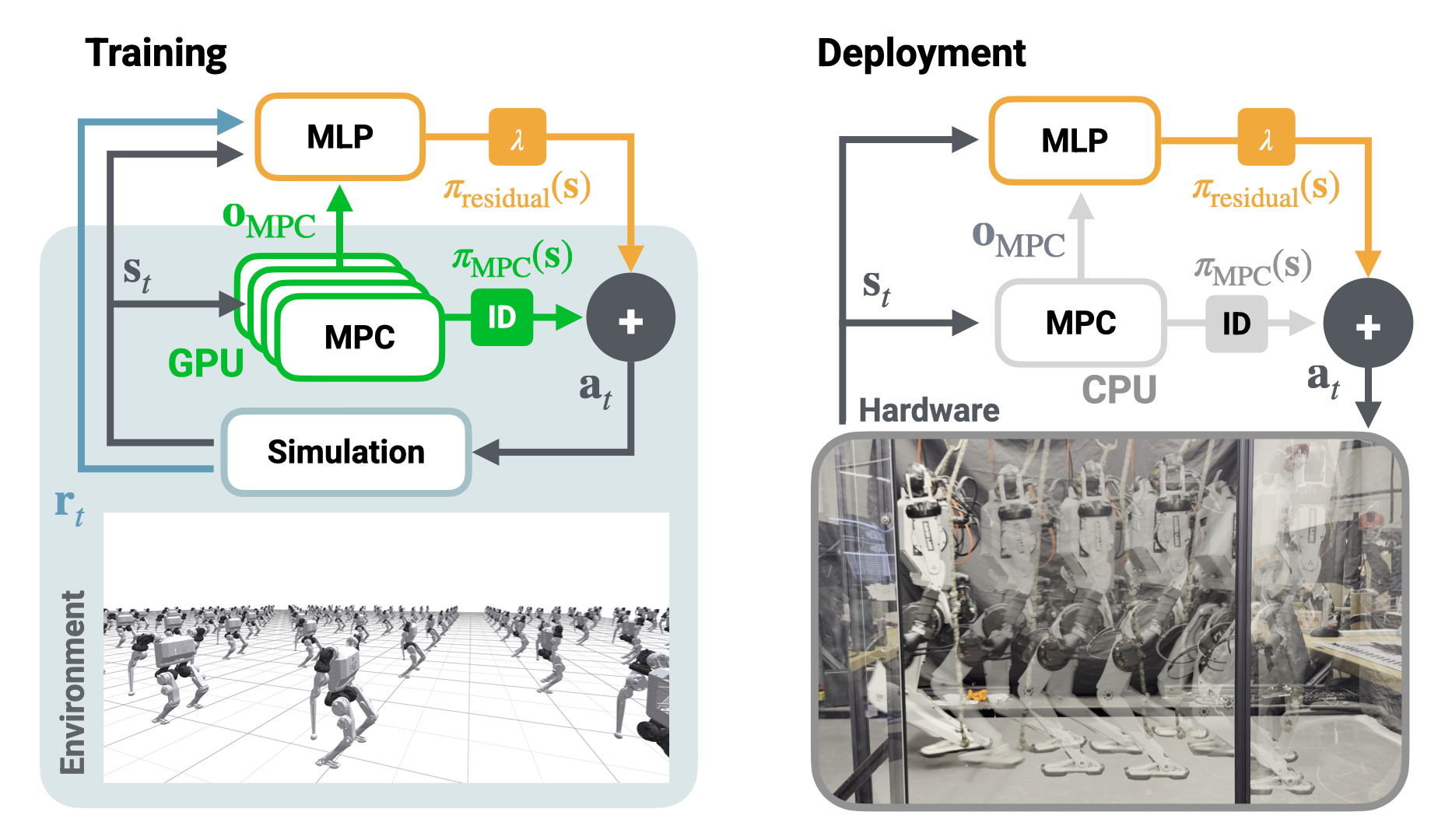
核心思路:该论文的核心思路是利用残差学习,让强化学习策略学习MPC的修正量。MPC提供一个基于物理模型的初始控制策略,而强化学习策略则学习如何对这个初始策略进行微调,以应对模型误差、外部干扰等因素。这种方法结合了MPC的先验知识和RL的自适应能力。
技术框架:整体架构包含一个GPU并行化的MPC模块和一个强化学习模块。MPC模块负责生成基于模型的控制输出,该模块在GPU上并行运行,可以同时处理数千个智能体,从而加速强化学习的训练过程。强化学习模块则学习一个残差策略,该策略以MPC的输出作为输入,并输出一个修正量。最终的控制指令是MPC的输出加上残差策略的输出。
关键创新:该论文的关键创新在于将MPC和RL紧密集成在一个残差架构中,利用GPU并行化加速训练,并使用MPC作为RL的先验知识。这种方法不仅提高了样本效率,还增强了策略的鲁棒性和可解释性。与传统的端到端强化学习方法相比,该方法不需要复杂的奖励函数,并且可以更容易地泛化到新的环境。
关键设计:MPC模块采用了一种运动学全身MPC公式,该公式考虑了机器人的运动学约束和动力学约束。强化学习模块采用了一种actor-critic算法,其中actor网络学习残差策略,critic网络评估策略的价值。奖励函数的设计非常简单,主要包括跟踪目标速度和保持平衡两项。GPU并行化通过CUDA实现,可以同时处理数千个智能体,从而显著加速训练过程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,与独立的MPC和端到端RL相比,该方法在样本效率方面提高了显著,收敛到更高的渐近奖励,扩大了可跟踪的速度指令范围,并实现了对未见过的步态和不平坦地形的零样本适应。例如,在特定任务中,该方法可以将机器人的速度跟踪误差降低15%,并且可以在未知的地形上稳定行走。
🎯 应用场景
该研究成果可应用于各种机器人运动控制场景,例如四足机器人、人形机器人和自动驾驶车辆。通过结合模型预测控制和强化学习,可以提高机器人在复杂环境中的运动能力和鲁棒性,使其能够更好地适应未知的地形和任务。
📄 摘要(原文)
Model Predictive Control (MPC) provides interpretable, tunable locomotion controllers grounded in physical models, but its robustness depends on frequent replanning and is limited by model mismatch and real-time computational constraints. Reinforcement Learning (RL), by contrast, can produce highly robust behaviors through stochastic training but often lacks interpretability, suffers from out-of-distribution failures, and requires intensive reward engineering. This work presents a GPU-parallelized residual architecture that tightly integrates MPC and RL by blending their outputs at the torque-control level. We develop a kinodynamic whole-body MPC formulation evaluated across thousands of agents in parallel at 100 Hz for RL training. The residual policy learns to make targeted corrections to the MPC outputs, combining the interpretability and constraint handling of model-based control with the adaptability of RL. The model-based control prior acts as a strong bias, initializing and guiding the policy towards desirable behavior with a simple set of rewards. Compared to standalone MPC or end-to-end RL, our approach achieves higher sample efficiency, converges to greater asymptotic rewards, expands the range of trackable velocity commands, and enables zero-shot adaptation to unseen gaits and uneven terrain.