Reflection-Based Task Adaptation for Self-Improving VLA
作者: Baicheng Li, Dong Wu, Zike Yan, Xinchen Liu, Zecui Zeng, Lusong Li, Hongbin Zha
分类: cs.RO
发布日期: 2025-10-14 (更新: 2026-01-17)
💡 一句话要点
提出基于反射的自适应框架,用于视觉-语言-动作模型的自提升VLA任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 强化学习 任务适应 机器人操作 自提升学习
📋 核心要点
- 现有VLA模型在特定任务上的适应性差,强化学习方法效率低,难以快速掌握任务。
- 提出反射性自适应框架,通过失败分析和成功模仿的双路径学习,实现快速自主的任务适应。
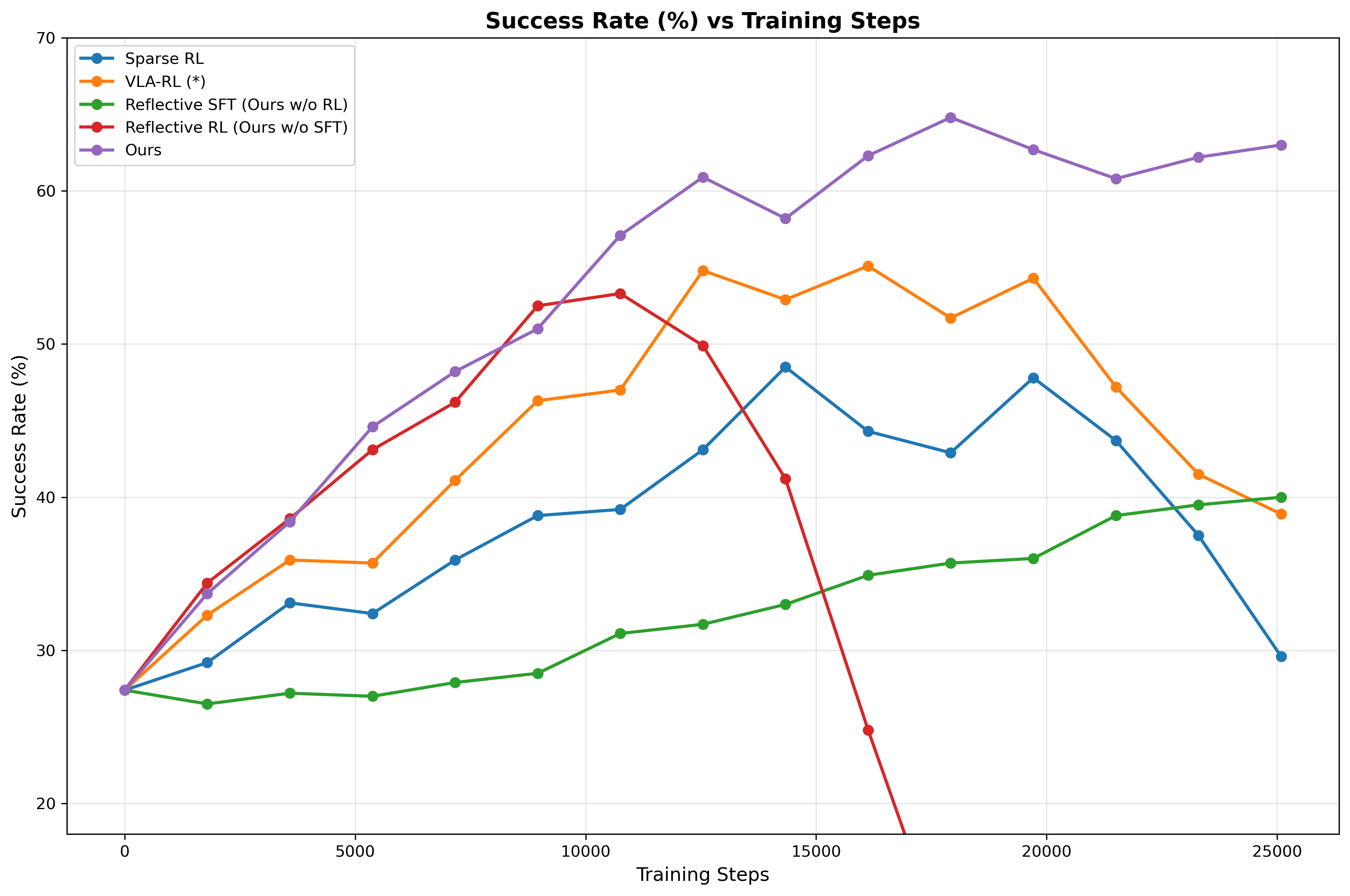
- 实验表明,该框架在操作任务中比现有方法收敛更快,并能达到更高的成功率。
📝 摘要(中文)
预训练的视觉-语言-动作(VLA)模型代表了通用机器人领域的一大进步,然而,如何有效地将它们适应于新的、特定的任务仍然是一个重要的挑战。强化学习(RL)是这种适应的一个有希望的途径,但该过程通常效率低下,阻碍了快速掌握任务。我们引入了反射性自适应,这是一个用于快速、自主任务适应的框架,无需人工干预。我们的框架建立了一个自提升循环,其中智能体从自身的经验中学习,以提高策略和执行能力。该框架的核心是一个双路径架构,它解决了完整的适应生命周期。首先,一个失败驱动的反射性RL路径通过使用VLM的因果推理从失败分析中自动合成一个有针对性的、密集的奖励函数来实现快速学习。这提供了一个集中的学习信号,显著加速了策略探索。然而,优化这种代理奖励会带来“奖励破解”的潜在风险,即智能体掌握了奖励函数但未能完成实际任务。为了抵消这一点,我们的第二条路径,即成功驱动的质量引导SFT,将策略建立在整体成功的基础上。它识别并选择性地模仿高质量的成功轨迹,确保智能体与最终任务目标保持一致。该路径通过条件课程机制得到加强,以帮助初始探索。我们在具有挑战性的操作任务中进行了实验。结果表明,与代表性的基线相比,我们的框架实现了更快的收敛速度和更高的最终成功率。我们的工作为创建能够有效且可靠地适应新环境的自提升智能体提供了一个强大的解决方案。
🔬 方法详解
问题定义:论文旨在解决预训练的视觉-语言-动作(VLA)模型在面对新的、特定的机器人操作任务时,难以快速有效地进行适应的问题。现有的强化学习方法虽然可以用于任务适应,但通常存在样本效率低、收敛速度慢等问题,导致机器人难以在短时间内掌握新任务。此外,单纯依赖奖励函数进行学习容易导致“奖励破解”,即智能体学会了最大化奖励,但实际表现却偏离了任务目标。
核心思路:论文的核心思路是构建一个自提升的学习循环,让智能体能够从自身的经验中学习,并不断改进策略和执行能力。该循环包含两个关键路径:失败驱动的反射性强化学习(Failure-Driven Reflective RL)和成功驱动的质量引导监督微调(Success-Driven Quality-Guided SFT)。前者利用失败经验快速探索策略空间,后者则通过模仿高质量的成功轨迹来保证策略的可靠性和任务目标的对齐。
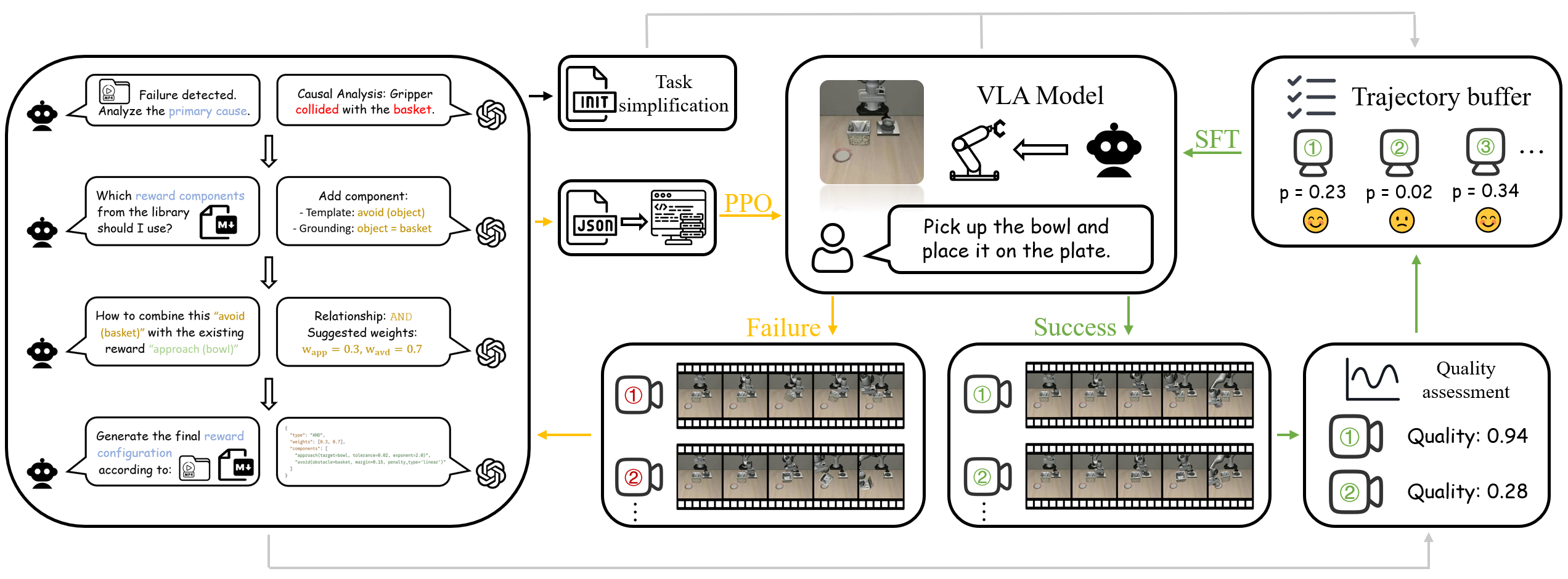
技术框架:整体框架包含两个主要模块:失败驱动的反射性强化学习(Failure-Driven Reflective RL)和成功驱动的质量引导监督微调(Success-Driven Quality-Guided SFT)。首先,智能体在环境中进行探索,如果失败,则利用VLM的因果推理能力,从失败的经验中自动生成一个有针对性的、密集的奖励函数。然后,智能体利用强化学习算法,优化策略以最大化该奖励函数。为了避免“奖励破解”,智能体还会选择性地模仿高质量的成功轨迹,通过监督学习的方式微调策略。此外,还引入了条件课程机制,以帮助智能体在初始阶段进行有效的探索。
关键创新:该论文的关键创新在于提出了一个双路径的自适应框架,将失败驱动的探索和成功驱动的模仿相结合。通过失败分析自动生成奖励函数,可以加速策略探索,提高学习效率。同时,通过模仿高质量的成功轨迹,可以避免“奖励破解”,保证策略的可靠性和任务目标的对齐。这种双路径学习的方式,能够让智能体在快速适应新任务的同时,保持良好的泛化能力。
关键设计:在失败驱动的反射性强化学习中,奖励函数的设计至关重要。论文利用VLM的因果推理能力,根据失败的原因自动生成奖励函数。例如,如果智能体因为抓取失败而导致任务失败,则奖励函数会鼓励智能体更精确地抓取目标物体。在成功驱动的质量引导监督微调中,需要选择高质量的成功轨迹进行模仿。论文采用了一种基于置信度的选择方法,选择那些智能体认为最成功的轨迹进行模仿。此外,条件课程机制也需要精心设计,以保证智能体在初始阶段能够进行有效的探索。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架在具有挑战性的操作任务中,与代表性的基线方法相比,实现了更快的收敛速度和更高的最终成功率。具体来说,该框架能够更快地找到有效的策略,并且能够达到更高的成功率,证明了其在任务适应方面的优越性。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如工业自动化、家庭服务机器人、医疗机器人等。通过该框架,机器人可以快速适应新的任务需求,提高工作效率和灵活性。此外,该研究也为开发更智能、更自主的机器人系统提供了新的思路,有助于推动机器人技术的发展。
📄 摘要(原文)
Pre-trained Vision-Language-Action (VLA) models represent a major leap towards general-purpose robots, yet efficiently adapting them to novel, specific tasks in-situ remains a significant hurdle. While reinforcement learning (RL) is a promising avenue for such adaptation, the process often suffers from low efficiency, hindering rapid task mastery. We introduce Reflective Self-Adaptation, a framework for rapid, autonomous task adaptation without human intervention. Our framework establishes a self-improving loop where the agent learns from its own experience to enhance both strategy and execution. The core of our framework is a dual-pathway architecture that addresses the full adaptation lifecycle. First, a Failure-Driven Reflective RL pathway enables rapid learning by using the VLM's causal reasoning to automatically synthesize a targeted, dense reward function from failure analysis. This provides a focused learning signal that significantly accelerates policy exploration. However, optimizing such proxy rewards introduces a potential risk of "reward hacking," where the agent masters the reward function but fails the actual task. To counteract this, our second pathway, Success-Driven Quality-Guided SFT, grounds the policy in holistic success. It identifies and selectively imitates high-quality successful trajectories, ensuring the agent remains aligned with the ultimate task goal. This pathway is strengthened by a conditional curriculum mechanism to aid initial exploration. We conduct experiments in challenging manipulation tasks. The results demonstrate that our framework achieves faster convergence and higher final success rates compared to representative baselines. Our work presents a robust solution for creating self-improving agents that can efficiently and reliably adapt to new environments.