Improving Generative Behavior Cloning via Self-Guidance and Adaptive Chunking
作者: Junhyuk So, Chiwoong Lee, Shinyoung Lee, Jungseul Ok, Eunhyeok Park
分类: cs.RO, cs.LG
发布日期: 2025-10-14
备注: Accepted at NeurIPS25
🔗 代码/项目: GITHUB
💡 一句话要点
提出自指导和自适应分块方法,提升生成行为克隆在机器人控制中的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 生成行为克隆 机器人控制 扩散策略 自指导 自适应分块
📋 核心要点
- 开环控制的生成行为克隆方法虽有优势,但其随机性和延迟响应会在复杂环境中导致任务失败。
- 论文提出自指导机制,利用历史观测提升动作保真度,并引入自适应分块策略,权衡反应性和一致性。
- 实验结果表明,该方法在模拟和真实机器人操作任务中,显著提升了生成行为克隆的性能。
📝 摘要(中文)
生成行为克隆(GBC)是一种简单而有效的机器人学习框架,尤其适用于多任务场景。最近的GBC方法通常采用带有开环(OL)控制的扩散策略,通过扩散过程生成动作,并在没有重新规划的情况下以多步块的形式执行。虽然这种方法在成功率和泛化方面表现出色,但其固有的随机性可能导致错误的动作采样,偶尔会导致意外的任务失败。此外,OL控制存在响应延迟的问题,这会降低在嘈杂或动态环境中的性能。为了解决这些限制,我们提出了两种新技术来增强扩散策略的一致性和反应性:(1)自指导,通过利用过去的观察结果并隐式地促进未来感知行为来提高动作的保真度;(2)自适应分块,当反应性的好处超过时间一致性的需求时,有选择地更新动作序列。大量的实验表明,我们的方法在各种模拟和真实世界的机器人操作任务中显著提高了GBC性能。我们的代码可在https://github.com/junhyukso/SGAC 获取。
🔬 方法详解
问题定义:论文旨在解决生成行为克隆(GBC)方法中,基于开环控制的扩散策略在机器人控制任务中存在的两个主要问题:一是扩散过程的随机性导致动作采样错误,进而引起任务失败;二是开环控制的延迟响应,使得系统难以适应动态或噪声环境。现有方法难以兼顾动作生成的一致性和对环境变化的快速响应。
核心思路:论文的核心思路是通过引入自指导机制和自适应分块策略,来提升GBC方法在机器人控制中的性能。自指导机制旨在提高动作的保真度,减少随机性带来的误差;自适应分块策略则旨在平衡时间一致性和对环境变化的反应速度,从而使机器人能够更好地适应复杂环境。
技术框架:整体框架基于生成行为克隆,主要包含以下模块:1) 扩散策略生成动作序列;2) 自指导模块,利用历史观测信息对生成的动作进行修正,提高动作的合理性;3) 自适应分块模块,根据环境变化动态调整动作序列的更新频率,实现快速响应;4) 机器人执行模块,执行经过修正和调整的动作序列。
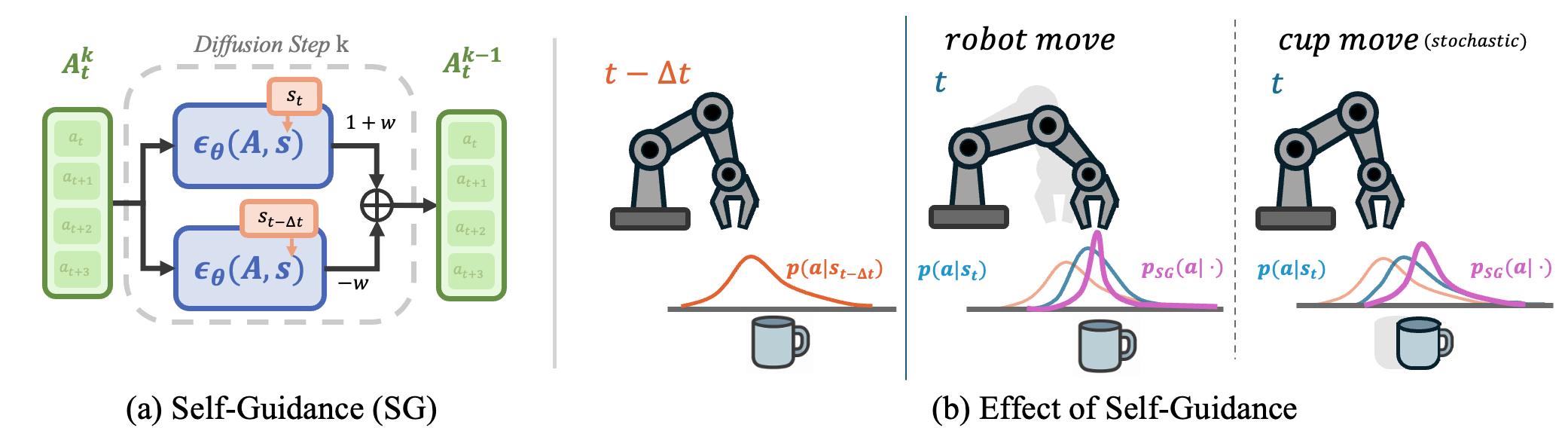
关键创新:论文的关键创新在于提出了自指导和自适应分块两种技术。自指导通过利用历史观测信息,隐式地学习未来感知的行为,从而提高动作的保真度。自适应分块则根据环境变化动态调整动作序列的更新频率,使得机器人能够在保持一定时间一致性的前提下,快速响应环境变化。这两种技术共同提升了GBC方法在复杂环境中的性能。
关键设计:自指导模块的具体实现方式未知,可能涉及到注意力机制或循环神经网络等技术,用于提取历史观测信息并指导动作生成。自适应分块策略可能基于某种环境变化检测机制,例如监测传感器数据的变化率,当变化率超过阈值时,触发动作序列的更新。具体的损失函数和网络结构等细节在摘要中未提及,需要参考论文全文。
🖼️ 关键图片
📊 实验亮点
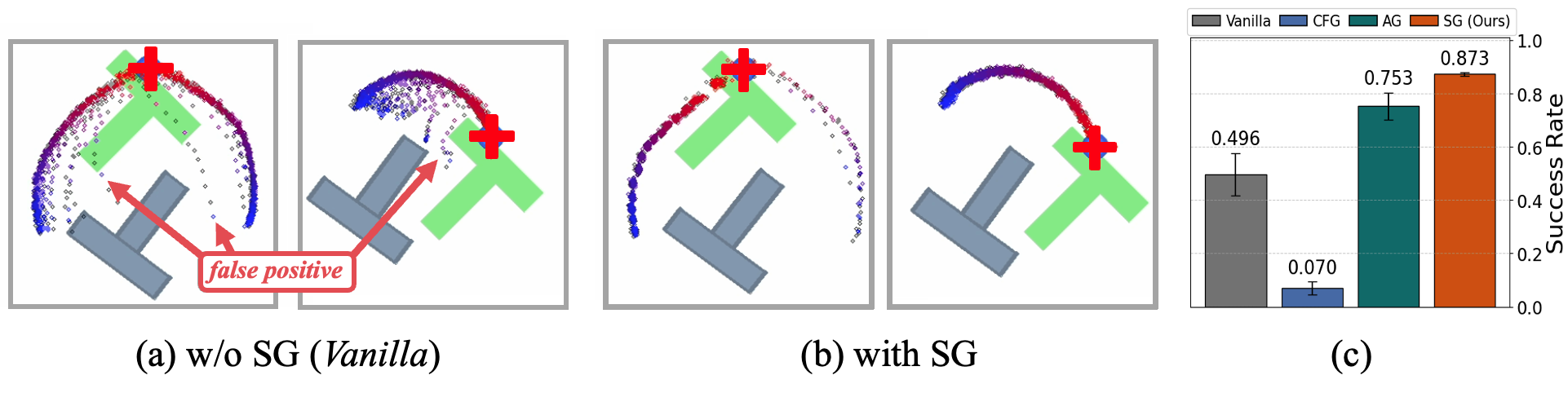
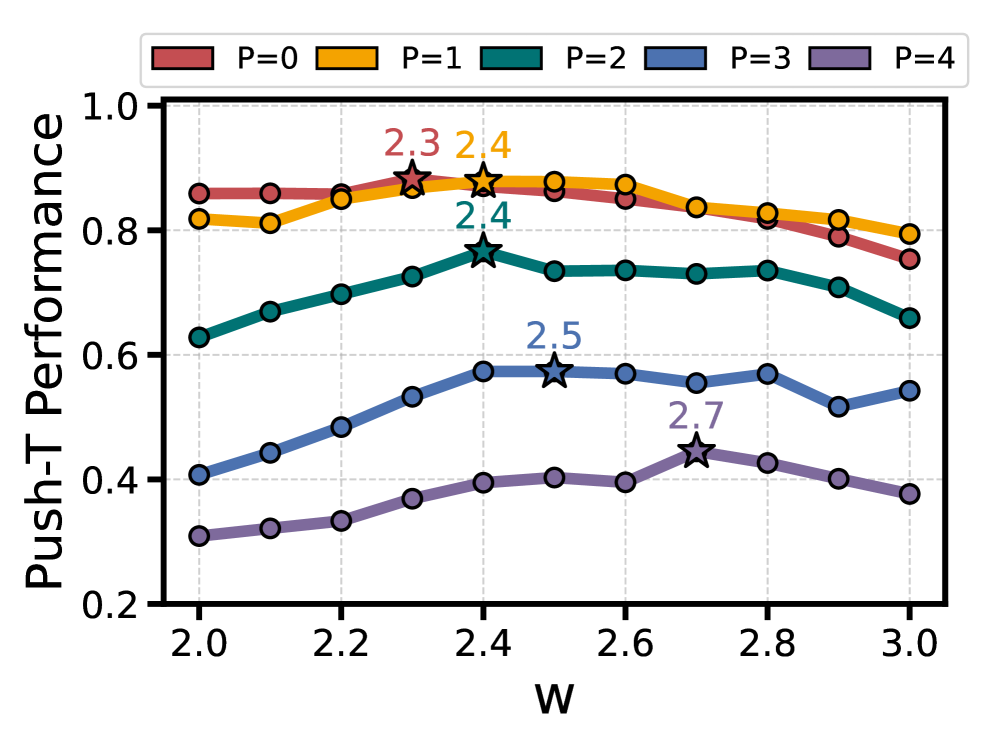
论文通过大量的模拟和真实世界的机器人操作任务验证了所提出方法的有效性。具体性能数据和对比基线在摘要中未提及,但强调了该方法在各种任务中显著提高了GBC的性能。具体的提升幅度需要参考论文全文。
🎯 应用场景
该研究成果可应用于各种机器人控制任务,尤其是在需要高精度和快速响应的复杂环境中,例如工业自动化、医疗机器人、服务机器人等。通过提高机器人动作的可靠性和适应性,可以提升机器人的工作效率和安全性,拓展其应用范围。
📄 摘要(原文)
Generative Behavior Cloning (GBC) is a simple yet effective framework for robot learning, particularly in multi-task settings. Recent GBC methods often employ diffusion policies with open-loop (OL) control, where actions are generated via a diffusion process and executed in multi-step chunks without replanning. While this approach has demonstrated strong success rates and generalization, its inherent stochasticity can result in erroneous action sampling, occasionally leading to unexpected task failures. Moreover, OL control suffers from delayed responses, which can degrade performance in noisy or dynamic environments. To address these limitations, we propose two novel techniques to enhance the consistency and reactivity of diffusion policies: (1) self-guidance, which improves action fidelity by leveraging past observations and implicitly promoting future-aware behavior; and (2) adaptive chunking, which selectively updates action sequences when the benefits of reactivity outweigh the need for temporal consistency. Extensive experiments show that our approach substantially improves GBC performance across a wide range of simulated and real-world robotic manipulation tasks. Our code is available at https://github.com/junhyukso/SGAC