Controlling Intent Expressiveness in Robot Motion with Diffusion Models
作者: Wenli Shi, Clemence Grislain, Olivier Sigaud, Mohamed Chetouani
分类: cs.RO
发布日期: 2025-10-14
备注: Using diffusion models trained on quality diversity datasets for generating robot motions with adjustable legibility levels
💡 一句话要点
提出基于扩散模型的可控机器人运动意图表达框架,实现人机交互中运动可读性的灵活调节。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 机器人运动规划 人机交互 运动可读性 扩散模型 信息势场
📋 核心要点
- 传统机器人轨迹生成方法注重效率,忽略了运动意图的清晰表达,导致人机交互困难。
- 论文提出基于信息势场的两阶段扩散模型,实现对机器人运动可读性的连续控制。
- 实验表明,该方法能生成不同可读性的运动,且性能与现有最佳方法相当。
📝 摘要(中文)
机器人运动的可读性在人机交互中至关重要,因为它使人类能够快速推断机器人的预期目标。传统的轨迹生成方法通常优先考虑效率,但往往未能清晰地表达机器人的意图。现有的可读运动方法通常只产生单一的“最可读”轨迹,忽略了在不同上下文中调节意图表达的需求。本文提出了一种新的运动生成框架,该框架能够在整个范围内实现可控的可读性,从高度可读的运动到高度模糊的运动。我们引入了一种基于信息势场的建模方法,为轨迹分配连续的可读性分数,并在此基础上构建了一个两阶段扩散框架,该框架首先生成指定可读性级别的路径,然后将其转换为可执行的机器人动作。在2D和3D到达任务中的实验表明,我们的方法能够产生具有不同可读性的多样且可控的运动,同时实现与SOTA相当的性能。
🔬 方法详解
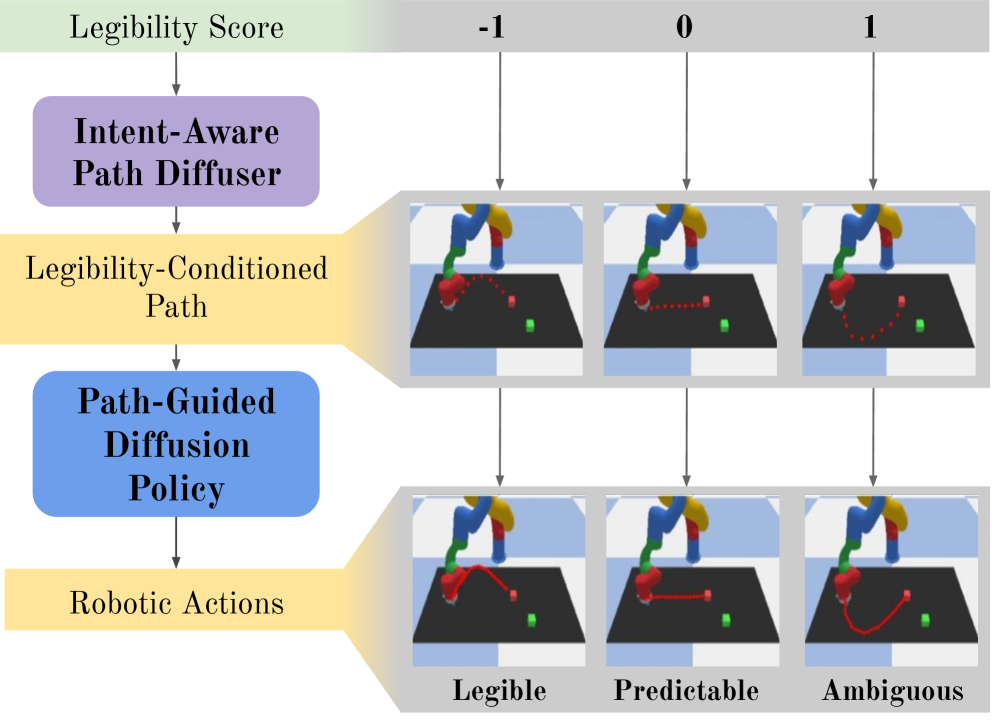
问题定义:现有机器人运动规划方法,要么只关注效率,忽略了运动的可读性,使得人类难以理解机器人的意图;要么只能生成单一“最可读”的轨迹,无法根据不同的交互场景灵活调整运动的意图表达程度。因此,需要一种能够控制机器人运动可读性的方法,使其在不同场景下能够表达清晰或模糊的意图。
核心思路:论文的核心思路是利用扩散模型生成具有不同可读性水平的机器人运动轨迹。通过引入信息势场来量化轨迹的可读性,并将其作为扩散模型的条件,从而控制生成轨迹的意图表达程度。这种方法允许在整个可读性范围内生成运动,而不仅仅是最可读的运动。
技术框架:该框架包含两个主要阶段:1) 基于信息势场的可读性建模:使用信息势场为轨迹分配连续的可读性分数。2) 两阶段扩散模型:第一阶段,生成具有指定可读性级别的路径;第二阶段,将生成的路径转换为可执行的机器人动作。整体流程是,首先根据期望的可读性水平,利用扩散模型生成轨迹,然后将轨迹转化为机器人可以执行的动作。
关键创新:最重要的技术创新点在于将扩散模型与信息势场相结合,实现了对机器人运动可读性的连续控制。与现有方法相比,该方法不仅可以生成可读的运动,还可以生成具有不同可读性水平的运动,从而更好地适应不同的交互场景。此外,两阶段的扩散框架也提高了生成运动的多样性和可控性。
关键设计:信息势场用于量化轨迹的可读性,其具体形式未知,但可以推测其与轨迹的几何形状、速度分布等因素有关。扩散模型采用两阶段结构,第一阶段生成路径,第二阶段将路径转化为动作,具体的网络结构和损失函数未知。可读性水平作为扩散模型的条件输入,控制生成轨迹的意图表达程度。
🖼️ 关键图片


📊 实验亮点
该方法在2D和3D到达任务中进行了验证,实验结果表明,该方法能够生成具有不同可读性的多样且可控的运动,同时实现与SOTA相当的性能。具体的性能数据和对比基线未知,但论文强调了该方法在可读性控制方面的优势。
🎯 应用场景
该研究成果可应用于各种人机协作场景,例如:在需要清晰表达意图的场景(如引导、教学)中,机器人可以生成高度可读的运动;在需要隐藏意图的场景(如安全巡逻、侦察)中,机器人可以生成模糊的运动。此外,该方法还可以用于评估机器人运动的可读性,从而优化运动规划算法。
📄 摘要(原文)
Legibility of robot motion is critical in human-robot interaction, as it allows humans to quickly infer a robot's intended goal. Although traditional trajectory generation methods typically prioritize efficiency, they often fail to make the robot's intentions clear to humans. Meanwhile, existing approaches to legible motion usually produce only a single "most legible" trajectory, overlooking the need to modulate intent expressiveness in different contexts. In this work, we propose a novel motion generation framework that enables controllable legibility across the full spectrum, from highly legible to highly ambiguous motions. We introduce a modeling approach based on an Information Potential Field to assign continuous legibility scores to trajectories, and build upon it with a two-stage diffusion framework that first generates paths at specified legibility levels and then translates them into executable robot actions. Experiments in both 2D and 3D reaching tasks demonstrate that our approach produces diverse and controllable motions with varying degrees of legibility, while achieving performance comparable to SOTA. Code and project page: https://legibility-modulator.github.io.