Pretraining in Actor-Critic Reinforcement Learning for Robot Locomotion
作者: Jiale Fan, Andrei Cramariuc, Tifanny Portela, Marco Hutter
分类: cs.RO, cs.LG
发布日期: 2025-10-14 (更新: 2025-12-08)
💡 一句话要点
提出基于逆动力学模型的预训练方法,提升机器人运动强化学习的样本效率和性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人运动 强化学习 预训练 逆动力学模型 Actor-Critic 样本效率 策略优化
📋 核心要点
- 机器人运动强化学习通常从头开始学习,忽略了任务间共享的通用知识,导致效率低下。
- 提出一种基于本体感受逆动力学模型(PIDM)的预训练方法,用于Actor-Critic算法的热启动。
- 实验表明,该方法在多个机器人运动任务中显著提高了样本效率和任务性能。
📝 摘要(中文)
近年来,预训练-微调范式极大地推动了人工智能研究的进步。然而,在机器人运动强化学习领域,尽管同一机器人的所有特定任务策略很可能共享一些可泛化的知识,但各个技能通常是从头开始学习的。本文旨在定义一种预训练神经网络模型的范式,该模型封装了这些知识,并可以作为经典Actor-Critic算法(如近端策略优化(PPO))中热启动强化学习过程的基础。我们首先使用与任务无关的基于探索的数据收集算法来收集多样化的动态转换数据,然后通过监督学习训练本体感受逆动力学模型(PIDM)。预训练的权重随后被加载到Actor和Critic网络中,以热启动实际任务的策略优化。我们使用包含3种不同机器人实体的9种不同的机器人运动强化学习环境系统地验证了我们提出的方法,表明了这种初始化策略的显著优势。与随机初始化相比,我们提出的方法平均提高了36.9%的样本效率和7.3%的任务性能。我们进一步提出了关键的消融研究和经验分析,阐明了该方法有效性背后的机制。
🔬 方法详解
问题定义:机器人运动强化学习通常需要为每个新任务从头开始训练策略,忽略了不同任务之间可能存在的通用知识。这种从头开始学习的方式导致样本效率低下,训练时间长,难以适应复杂环境。现有方法缺乏一种有效的利用通用运动知识的预训练机制。
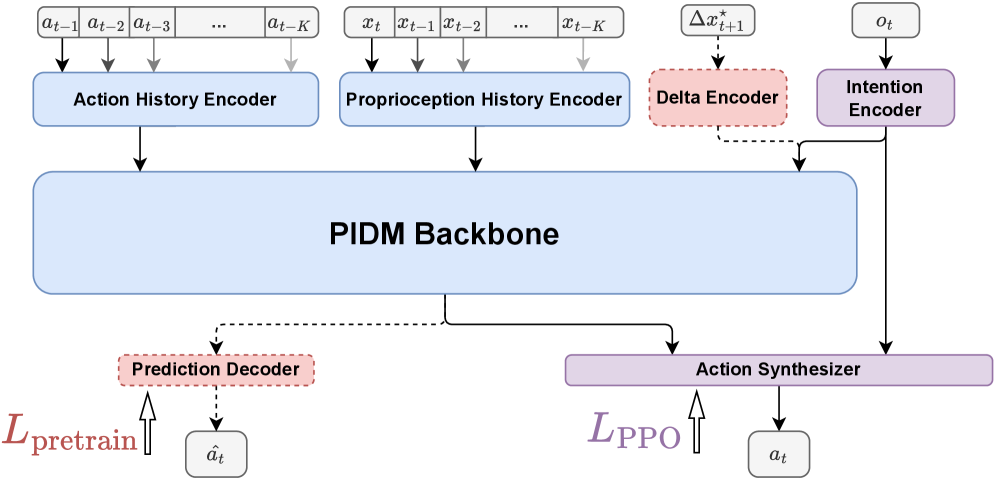
核心思路:本文的核心思路是利用预训练的本体感受逆动力学模型(PIDM)来捕获机器人运动的通用知识。PIDM学习从机器人的状态和下一个状态预测所需的动作,从而学习到机器人运动的基本动力学规律。通过将PIDM的权重作为Actor和Critic网络的初始值,可以加速强化学习过程,提高样本效率。
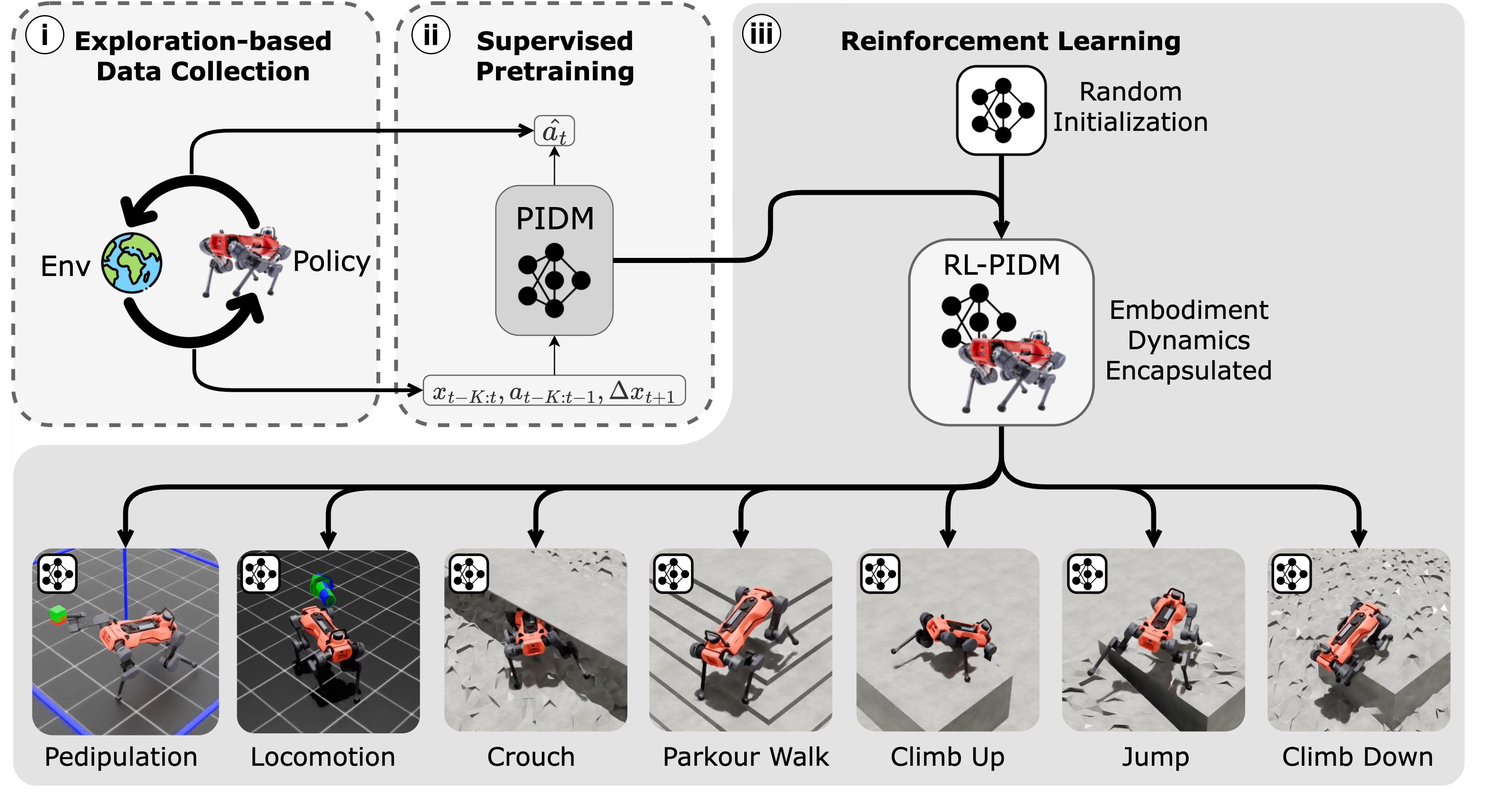
技术框架:该方法包含两个主要阶段:预训练阶段和微调阶段。在预训练阶段,首先使用与任务无关的探索策略收集机器人运动数据。然后,使用这些数据训练PIDM,PIDM的输入是当前状态和下一个状态,输出是所需的动作。在微调阶段,将PIDM的权重加载到Actor和Critic网络中,并使用PPO等Actor-Critic算法进行策略优化,以完成特定的机器人运动任务。
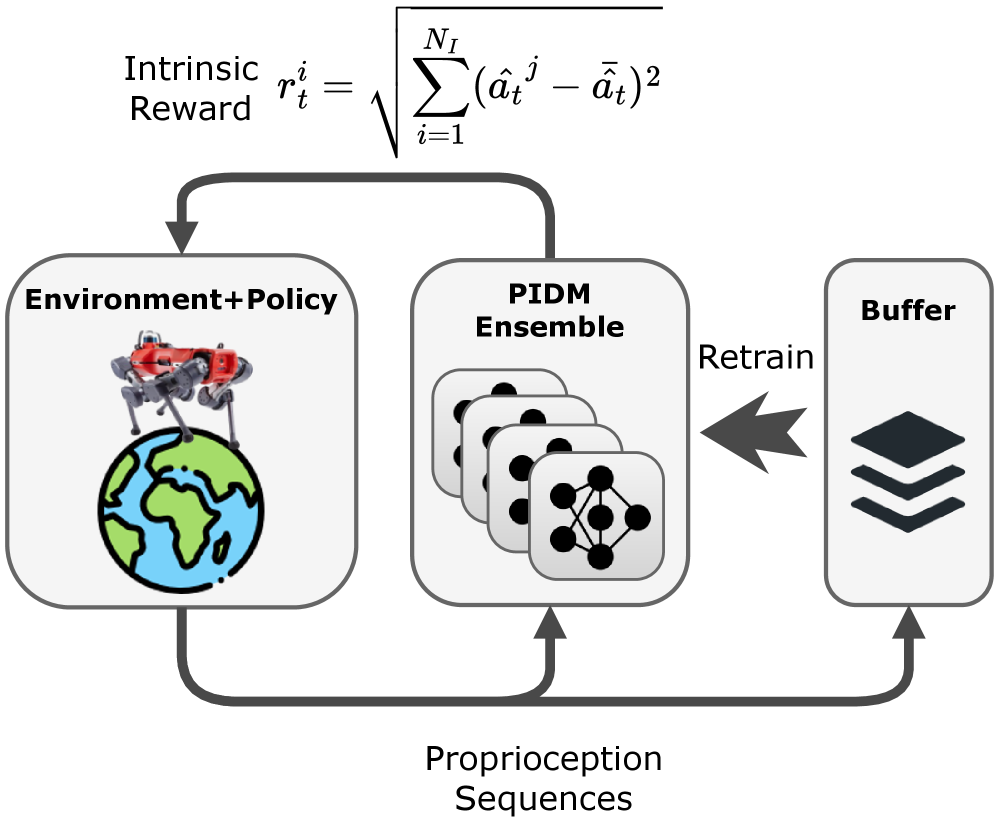
关键创新:该方法的关键创新在于利用本体感受逆动力学模型(PIDM)进行预训练,从而捕获机器人运动的通用知识。与传统的随机初始化相比,PIDM预训练能够提供更好的初始策略和价值函数估计,加速强化学习过程。此外,该方法采用与任务无关的探索策略收集数据,保证了预训练数据的多样性。
关键设计:PIDM的网络结构可以根据具体机器人进行调整,通常采用多层感知机(MLP)。损失函数采用均方误差(MSE),用于衡量预测动作与实际动作之间的差异。探索策略可以采用随机策略或基于好奇心的探索策略。在微调阶段,PPO算法的超参数需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,与随机初始化相比,该方法在9个不同的机器人运动强化学习环境中平均提高了36.9%的样本效率和7.3%的任务性能。消融研究表明,PIDM预训练对于提高性能至关重要。此外,实验还分析了预训练数据量和探索策略对性能的影响。
🎯 应用场景
该研究成果可广泛应用于各种机器人运动控制任务,例如四足机器人、机械臂和人形机器人的运动规划和控制。通过预训练,可以显著减少机器人学习新任务所需的时间和资源,提高机器人在复杂环境中的适应性和鲁棒性。该方法还有助于实现机器人的自主学习和终身学习能力。
📄 摘要(原文)
The pretraining-finetuning paradigm has facilitated numerous transformative advancements in artificial intelligence research in recent years. However, in the domain of reinforcement learning (RL) for robot locomotion, individual skills are often learned from scratch despite the high likelihood that some generalizable knowledge is shared across all task-specific policies belonging to the same robot embodiment. This work aims to define a paradigm for pretraining neural network models that encapsulate such knowledge and can subsequently serve as a basis for warm-starting the RL process in classic actor-critic algorithms, such as Proximal Policy Optimization (PPO). We begin with a task-agnostic exploration-based data collection algorithm to gather diverse, dynamic transition data, which is then used to train a Proprioceptive Inverse Dynamics Model (PIDM) through supervised learning. The pretrained weights are then loaded into both the actor and critic networks to warm-start the policy optimization of actual tasks. We systematically validated our proposed method with 9 distinct robot locomotion RL environments comprising 3 different robot embodiments, showing significant benefits of this initialization strategy. Our proposed approach on average improves sample efficiency by 36.9% and task performance by 7.3% compared to random initialization. We further present key ablation studies and empirical analyses that shed light on the mechanisms behind the effectiveness of this method.