Spatial Forcing: Implicit Spatial Representation Alignment for Vision-language-action Model
作者: Fuhao Li, Wenxuan Song, Han Zhao, Jingbo Wang, Pengxiang Ding, Donglin Wang, Long Zeng, Haoang Li
分类: cs.RO
发布日期: 2025-10-14 (更新: 2025-10-17)
💡 一句话要点
提出Spatial Forcing,解决VLA模型在3D空间感知上的不足
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人控制 空间感知 3D表示学习 隐式对齐
📋 核心要点
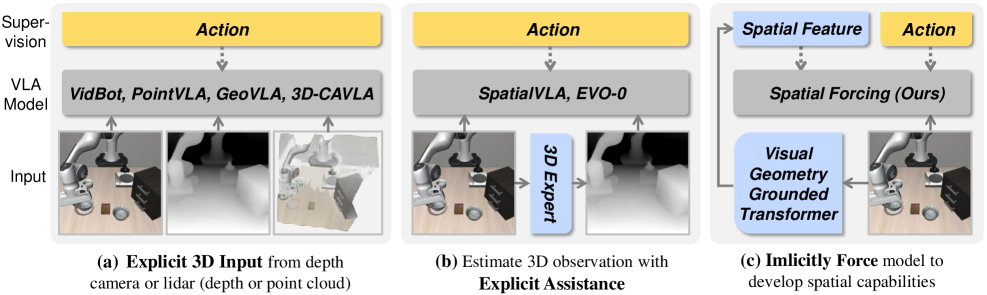
- 现有VLA模型依赖2D预训练,缺乏3D空间感知能力,难以在真实物理世界中精确执行动作。
- Spatial Forcing通过对齐VLA模型中间视觉嵌入与3D基础模型的几何表示,隐式地增强空间理解。
- 实验表明,Spatial Forcing在模拟和真实环境中均优于现有方法,并显著提升训练速度和数据效率。
📝 摘要(中文)
视觉-语言-动作(VLA)模型最近在使机器人遵循语言指令和执行精确动作方面显示出强大的潜力。然而,大多数VLA模型都建立在仅在2D数据上预训练的视觉-语言模型之上,这些模型缺乏准确的空间感知能力,阻碍了它们在3D物理世界中操作的能力。现有的解决方案试图结合显式的3D传感器输入,如深度图或点云,但这些方法面临传感器噪声、硬件异构性和现有数据集中不完整的深度覆盖等挑战。从2D图像估计3D线索的替代方法也受到深度估计器性能的限制。我们提出了Spatial Forcing (SF),这是一种简单而有效的对齐策略,它隐式地强制VLA模型发展空间理解能力,而无需依赖显式的3D输入或深度估计器。SF将VLA模型的中间视觉嵌入与预训练的3D基础模型生成的几何表示对齐。通过在中间层强制对齐,SF引导VLA模型编码更丰富的空间表示,从而提高动作精度。在模拟和真实环境中的大量实验表明,SF实现了最先进的结果,超过了基于2D和3D的VLA模型。SF进一步加速了高达3.8倍的训练速度,并提高了各种机器人任务中的数据效率。
🔬 方法详解
问题定义:VLA模型在机器人控制任务中表现出潜力,但现有模型主要基于2D图像训练,缺乏对3D空间的准确理解,导致动作执行精度不足。直接使用3D传感器数据(如深度图)受限于传感器噪声、硬件差异以及数据集覆盖不全等问题。利用2D图像估计深度信息的方法则受到深度估计器性能的限制。
核心思路:Spatial Forcing (SF) 的核心思想是,通过隐式地将VLA模型的视觉特征与3D空间信息对齐,来增强模型对3D环境的理解能力,而无需显式地使用3D传感器数据或深度估计器。这种隐式对齐能够让VLA模型学习到更丰富的空间表示,从而提高动作的精确性。
技术框架:SF方法主要包含以下几个阶段:1) 使用VLA模型处理视觉输入,提取中间视觉嵌入;2) 使用预训练的3D基础模型(例如,在3D数据上训练的几何表示模型)生成对应的几何表示;3) 通过损失函数,强制VLA模型的中间视觉嵌入与3D基础模型的几何表示对齐。这个对齐过程在VLA模型的训练过程中进行,从而引导模型学习到更丰富的空间信息。
关键创新:SF的关键创新在于其隐式空间表示对齐策略。与直接使用3D数据或深度估计器不同,SF利用预训练的3D基础模型作为空间信息的先验知识,通过对齐中间视觉特征,将这种先验知识迁移到VLA模型中。这种方法避免了对显式3D信息的依赖,从而提高了模型的鲁棒性和泛化能力。
关键设计:SF的关键设计包括:1) 中间层特征的选择:选择VLA模型中合适的中间层特征进行对齐,以平衡特征的抽象程度和空间信息的保留;2) 对齐损失函数的选择:使用合适的损失函数(例如,余弦相似度损失或均方误差损失)来衡量VLA模型特征与3D基础模型特征之间的相似度;3) 3D基础模型的选择:选择在相关3D数据集上预训练的、具有良好几何表示能力的模型。
🖼️ 关键图片


📊 实验亮点
Spatial Forcing在模拟和真实环境的机器人控制任务中取得了显著的性能提升,超越了基于2D和3D的VLA模型。实验结果表明,SF能够加速训练过程高达3.8倍,并提高数据效率。具体而言,SF在多个机器人任务上实现了state-of-the-art的性能,证明了其有效性和泛化能力。
🎯 应用场景
该研究成果可广泛应用于机器人控制领域,例如家庭服务机器人、工业自动化机器人、自动驾驶等。通过提升机器人对3D环境的理解能力,可以使其更安全、更高效地完成各种复杂任务。此外,该方法还可以推广到其他视觉-语言任务中,例如图像描述、视觉问答等,提升模型对场景的理解能力。
📄 摘要(原文)
Vision-language-action (VLA) models have recently shown strong potential in enabling robots to follow language instructions and execute precise actions. However, most VLAs are built upon vision-language models pretrained solely on 2D data, which lack accurate spatial awareness and hinder their ability to operate in the 3D physical world. Existing solutions attempt to incorporate explicit 3D sensor inputs such as depth maps or point clouds, but these approaches face challenges due to sensor noise, hardware heterogeneity, and incomplete depth coverage in existing datasets. Alternative methods that estimate 3D cues from 2D images also suffer from the limited performance of depth estimators. We propose Spatial Forcing (SF), a simple yet effective alignment strategy that implicitly forces VLA models to develop spatial comprehension capabilities without relying on explicit 3D inputs or depth estimators. SF aligns intermediate visual embeddings of VLAs with geometric representations produced by pretrained 3D foundation models. By enforcing alignment at intermediate layers, SF guides VLAs to encode richer spatial representations that enhance action precision. Extensive experiments in simulation and real-world environments demonstrate that SF achieves state-of-the-art results, surpassing both 2D- and 3D-based VLAs. SF further accelerates training by up to 3.8x and improves data efficiency across diverse robotic tasks. Project page is at https://spatial-forcing.github.io/