Ego-Vision World Model for Humanoid Contact Planning
作者: Hang Liu, Yuman Gao, Sangli Teng, Yufeng Chi, Yakun Sophia Shao, Zhongyu Li, Maani Ghaffari, Koushil Sreenath
分类: cs.RO, cs.AI, eess.SY
发布日期: 2025-10-13
💡 一句话要点
提出基于自中心视觉世界模型的类人机器人接触规划方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion)
关键词: 类人机器人 接触规划 世界模型 模型预测控制 自中心视觉
📋 核心要点
- 传统基于优化的规划器难以处理复杂的接触问题,而在线强化学习存在样本效率低和多任务能力有限的缺点。
- 论文核心在于结合学习的世界模型与基于采样的MPC,利用离线数据学习潜在空间中的预测模型,并使用替代价值函数解决稀疏奖励和噪声问题。
- 实验表明,该方法在接触感知任务中表现出色,包括墙壁支撑、物体阻挡和穿越拱门等,并在真实类人机器人上实现了实时部署。
📝 摘要(中文)
为了使类人机器人在非结构化环境中能够利用物理接触而非简单地避免碰撞,本文提出了一种框架,该框架结合了学习到的世界模型与基于采样的模型预测控制(MPC),并在无需演示的离线数据集上进行训练,以预测压缩潜在空间中的未来结果。为了解决稀疏接触奖励和传感器噪声问题,MPC使用学习到的替代价值函数进行密集、鲁棒的规划。该模型支持接触感知任务,包括扰动后的墙壁支撑、阻挡来袭物体以及穿越高度受限的拱门,与在线强化学习相比,提高了数据效率和多任务能力。在物理类人机器人上的部署表明,该系统能够从本体感受和自中心深度图像中实现鲁棒的实时接触规划。
🔬 方法详解
问题定义:类人机器人在非结构化环境中进行接触规划,需要能够安全有效地利用与环境的物理接触来完成任务。现有基于优化的方法难以处理接触的复杂性,计算成本高昂。而在线强化学习方法虽然可以学习接触策略,但样本效率低,需要大量的试错,且泛化能力有限,难以适应多任务场景。
核心思路:论文的核心思路是利用离线数据学习一个世界模型,该模型能够预测在给定动作序列下,环境状态的变化。然后,使用基于采样的MPC在该世界模型中进行规划,选择能够最大化预期奖励的动作序列。为了解决稀疏奖励和传感器噪声问题,引入了学习到的替代价值函数,为MPC提供更密集的奖励信号。
技术框架:整体框架包含三个主要模块:1) 离线数据集的构建,包含各种接触交互数据;2) 世界模型的学习,使用变分自编码器(VAE)将高维传感器数据压缩到低维潜在空间,并学习潜在空间中的动态模型;3) 基于采样的MPC,利用学习到的世界模型和替代价值函数进行规划,选择最优动作序列。
关键创新:最重要的创新点在于将学习的世界模型与基于采样的MPC相结合,实现了高效的接触规划。与传统的基于优化的方法相比,该方法能够更好地处理接触的复杂性。与在线强化学习方法相比,该方法具有更高的样本效率和更好的泛化能力。此外,使用自中心视觉信息作为输入,使得机器人能够更好地感知周围环境。
关键设计:世界模型使用变分自编码器(VAE)进行训练,将高维图像数据压缩到低维潜在空间。动态模型使用循环神经网络(RNN)进行学习,预测潜在空间中的状态转移。替代价值函数使用神经网络进行训练,根据当前状态预测未来的奖励。MPC使用交叉熵方法(CEM)进行采样和优化,选择最优动作序列。
🖼️ 关键图片

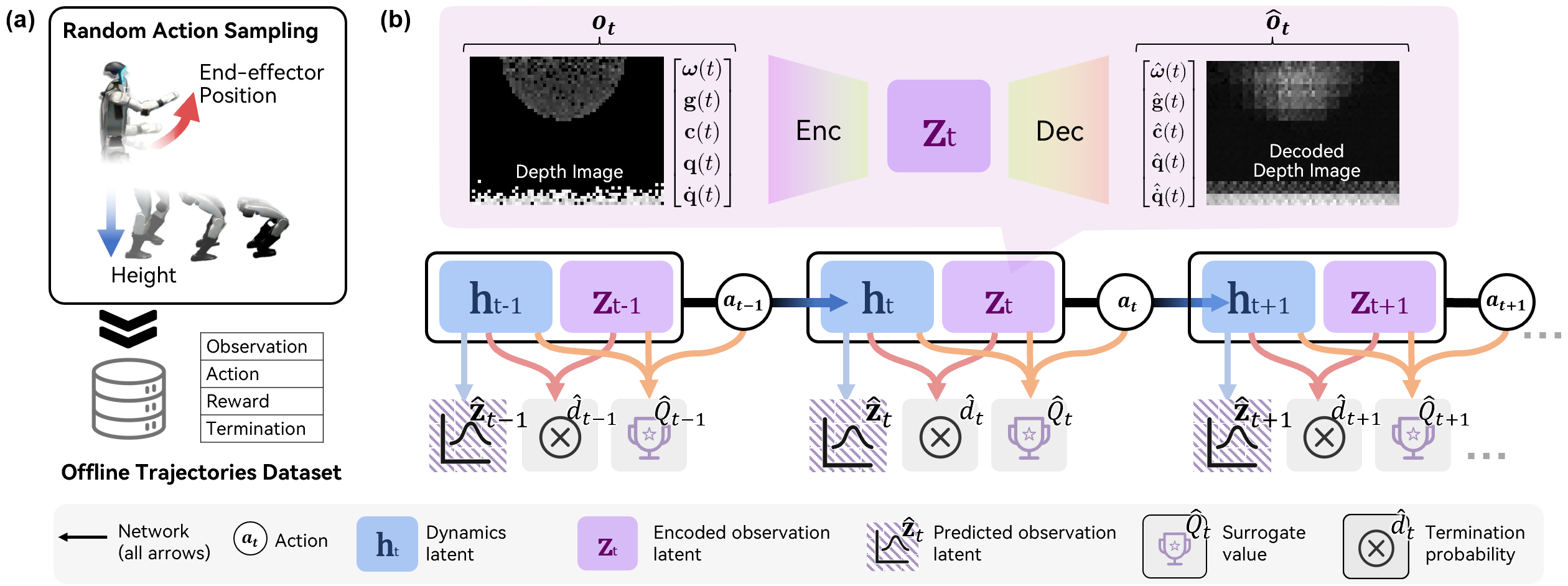
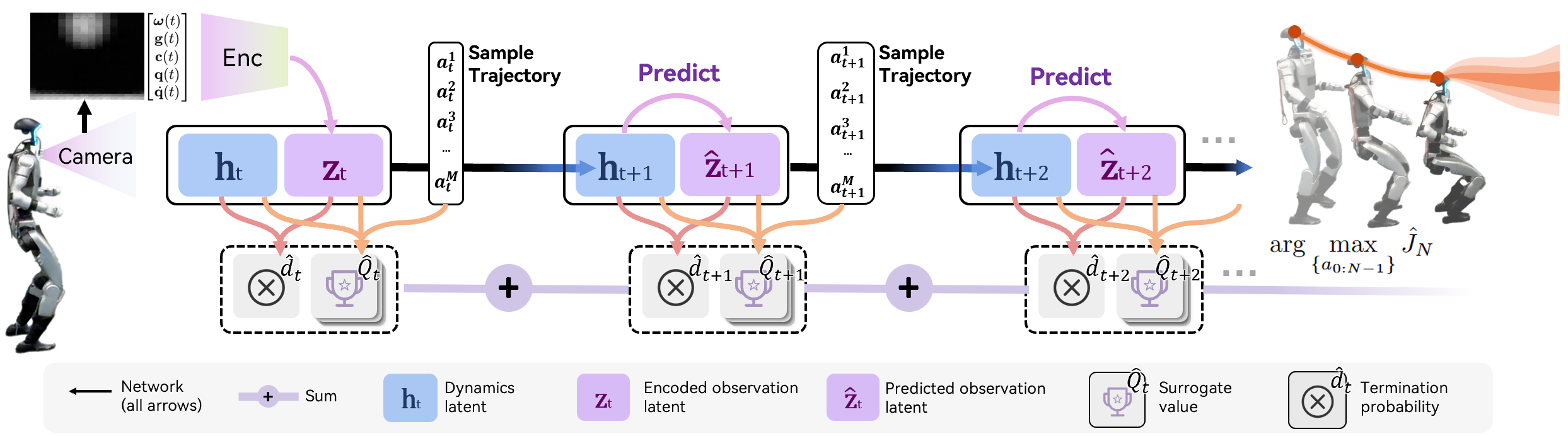
📊 实验亮点
实验结果表明,该方法在多个接触感知任务中取得了显著的性能提升。例如,在墙壁支撑任务中,机器人能够在受到扰动后保持平衡。在物体阻挡任务中,机器人能够成功阻挡来袭的物体。在穿越拱门任务中,机器人能够安全地通过高度受限的拱门。与在线强化学习方法相比,该方法的数据效率提高了数倍,并且具有更好的多任务能力。此外,该系统在真实的类人机器人上实现了实时部署,验证了其在实际应用中的可行性。
🎯 应用场景
该研究成果可应用于各种需要类人机器人与环境进行复杂物理交互的场景,例如:灾难救援、家庭服务、工业制造等。通过学习环境模型和优化接触策略,机器人可以更好地适应非结构化环境,完成各种复杂任务,例如:在狭窄空间中移动、搬运重物、进行精细操作等。未来,该技术有望推动类人机器人在实际生活中的广泛应用。
📄 摘要(原文)
Enabling humanoid robots to exploit physical contact, rather than simply avoid collisions, is crucial for autonomy in unstructured environments. Traditional optimization-based planners struggle with contact complexity, while on-policy reinforcement learning (RL) is sample-inefficient and has limited multi-task ability. We propose a framework combining a learned world model with sampling-based Model Predictive Control (MPC), trained on a demonstration-free offline dataset to predict future outcomes in a compressed latent space. To address sparse contact rewards and sensor noise, the MPC uses a learned surrogate value function for dense, robust planning. Our single, scalable model supports contact-aware tasks, including wall support after perturbation, blocking incoming objects, and traversing height-limited arches, with improved data efficiency and multi-task capability over on-policy RL. Deployed on a physical humanoid, our system achieves robust, real-time contact planning from proprioception and ego-centric depth images. Website: https://ego-vcp.github.io/