ManiAgent: An Agentic Framework for General Robotic Manipulation
作者: Yi Yang, Kefan Gu, Yuqing Wen, Hebei Li, Yucheng Zhao, Tiancai Wang, Xudong Liu
分类: cs.RO, cs.AI
发布日期: 2025-10-13 (更新: 2025-10-14)
备注: 8 pages, 6 figures, conference
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
ManiAgent:一种用于通用机器人操作的Agent框架,解决复杂推理和长时程任务规划问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 多Agent系统 视觉-语言-动作模型 任务规划 环境感知
📋 核心要点
- 现有的视觉-语言-动作(VLA)模型在复杂推理和长时程任务规划方面受到数据稀缺和模型容量的限制。
- ManiAgent通过多Agent协作,实现环境感知、子任务分解和动作生成,从而有效处理复杂操作场景。
- 实验表明,ManiAgent在模拟和真实世界的任务中均取得了显著的成功率,并能高效收集数据以训练VLA模型。
📝 摘要(中文)
本文提出了一种名为ManiAgent的agent架构,用于通用操作任务,该架构实现了从任务描述和环境输入到机器人操作动作的端到端输出。在该框架中,多个agent通过agent间的通信来执行环境感知、子任务分解和动作生成,从而能够高效地处理复杂的操作场景。评估结果表明,ManiAgent在SimplerEnv基准测试中取得了86.8%的成功率,在真实世界的抓取放置任务中取得了95.8%的成功率,从而能够高效地收集数据,进而训练出性能与在人工标注数据集上训练的VLA模型相当的VLA模型。项目网页可在https://yi-yang929.github.io/ManiAgent/上找到。
🔬 方法详解
问题定义:现有VLA模型在机器人操作任务中,尤其是在涉及复杂推理和长时程规划的任务中,面临数据稀缺和模型容量的挑战。人工标注大量机器人操作数据成本高昂,限制了VLA模型性能的进一步提升。因此,如何利用有限的数据,提升VLA模型在复杂机器人操作任务中的性能是一个关键问题。
核心思路:ManiAgent的核心思路是将复杂的机器人操作任务分解为多个子任务,并由多个Agent协同完成。每个Agent负责不同的功能,例如环境感知、子任务分解和动作生成。Agent之间通过通信进行协作,从而实现对复杂任务的高效处理。这种Agentic架构能够更好地利用环境信息,进行更有效的任务规划和动作生成。
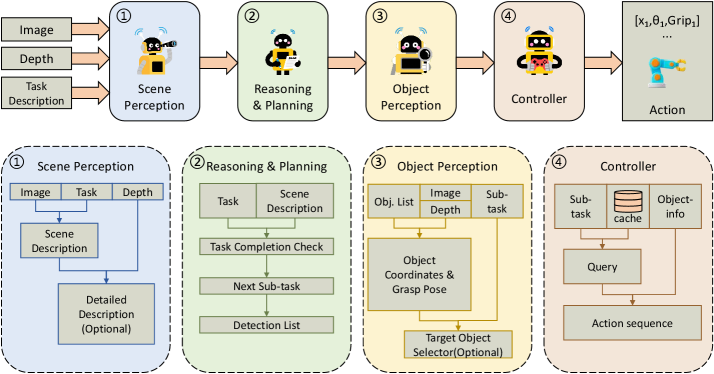
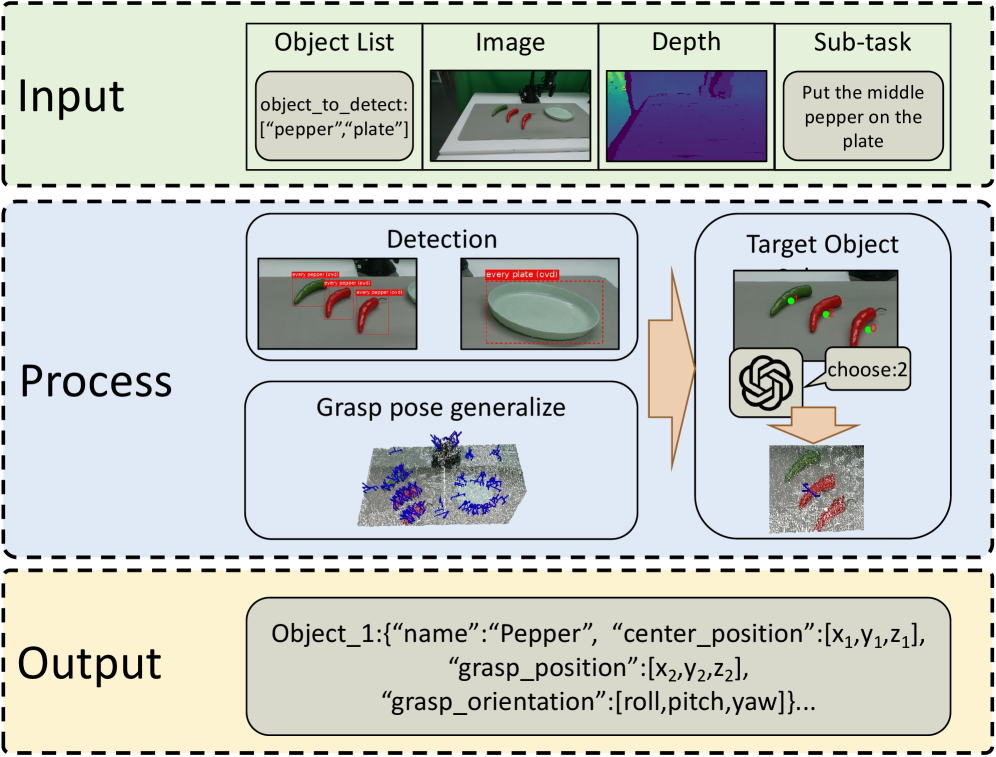
技术框架:ManiAgent的整体架构包含多个Agent,每个Agent负责特定的任务。主要模块包括:环境感知Agent,负责感知环境信息;任务分解Agent,负责将复杂任务分解为多个子任务;动作生成Agent,负责根据子任务生成具体的机器人动作。这些Agent通过通信模块进行信息交互,协同完成整个操作任务。整个流程是从任务描述和环境输入开始,经过各个Agent的处理,最终输出机器人操作动作。
关键创新:ManiAgent的关键创新在于其Agentic架构,它将复杂的机器人操作任务分解为多个子任务,并由多个Agent协同完成。这种架构能够更好地利用环境信息,进行更有效的任务规划和动作生成。与传统的端到端VLA模型相比,ManiAgent具有更好的可扩展性和鲁棒性,能够更好地适应复杂的操作场景。
关键设计:ManiAgent的具体实现细节未在摘要中详细说明,例如Agent之间的通信机制、各个Agent的网络结构、损失函数的设计等。这些细节对于ManiAgent的性能至关重要,但需要参考论文全文才能进行更深入的分析。摘要中提到,ManiAgent能够高效地收集数据,这暗示着可能采用了某种主动学习或强化学习策略,以提高数据利用率。
🖼️ 关键图片

📊 实验亮点
ManiAgent在SimplerEnv基准测试中取得了86.8%的成功率,在真实世界的抓取放置任务中取得了95.8%的成功率。此外,ManiAgent能够高效地收集数据,使得训练出的VLA模型性能与在人工标注数据集上训练的模型相当,这表明ManiAgent具有很强的数据效率。
🎯 应用场景
ManiAgent具有广泛的应用前景,可应用于工业自动化、家庭服务机器人、医疗机器人等领域。通过多Agent协作,ManiAgent能够处理更复杂的机器人操作任务,提高机器人的智能化水平和工作效率。该研究有助于推动机器人技术的发展,并为实现通用机器人操作奠定基础。
📄 摘要(原文)
While Vision-Language-Action (VLA) models have demonstrated impressive capabilities in robotic manipulation, their performance in complex reasoning and long-horizon task planning is limited by data scarcity and model capacity. To address this, we introduce ManiAgent, an agentic architecture for general manipulation tasks that achieves end-to-end output from task descriptions and environmental inputs to robotic manipulation actions. In this framework, multiple agents involve inter-agent communication to perform environmental perception, sub-task decomposition and action generation, enabling efficient handling of complex manipulation scenarios. Evaluations show ManiAgent achieves an 86.8% success rate on the SimplerEnv benchmark and 95.8% on real-world pick-and-place tasks, enabling efficient data collection that yields VLA models with performance comparable to those trained on human-annotated datasets. The project webpage is available at https://yi-yang929.github.io/ManiAgent/.