Constraint-Aware Reinforcement Learning via Adaptive Action Scaling
作者: Murad Dawood, Usama Ahmed Siddiquie, Shahram Khorshidi, Maren Bennewitz
分类: cs.RO, cs.LG, eess.SY
发布日期: 2025-10-13
💡 一句话要点
提出基于自适应动作缩放的约束感知强化学习方法,提升安全性和性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 约束感知 动作缩放 成本感知调节器 Safety Gym 离线强化学习
📋 核心要点
- 现有安全强化学习方法在优化奖励和安全性时存在冲突,或依赖于需要先验知识的外部安全过滤器。
- 论文提出一种模块化的成本感知调节器,通过自适应缩放动作而非直接覆盖,来平衡探索和安全性。
- 实验表明,该方法在Safety Gym任务中显著降低了约束违反,并提高了回报,优于现有方法。
📝 摘要(中文)
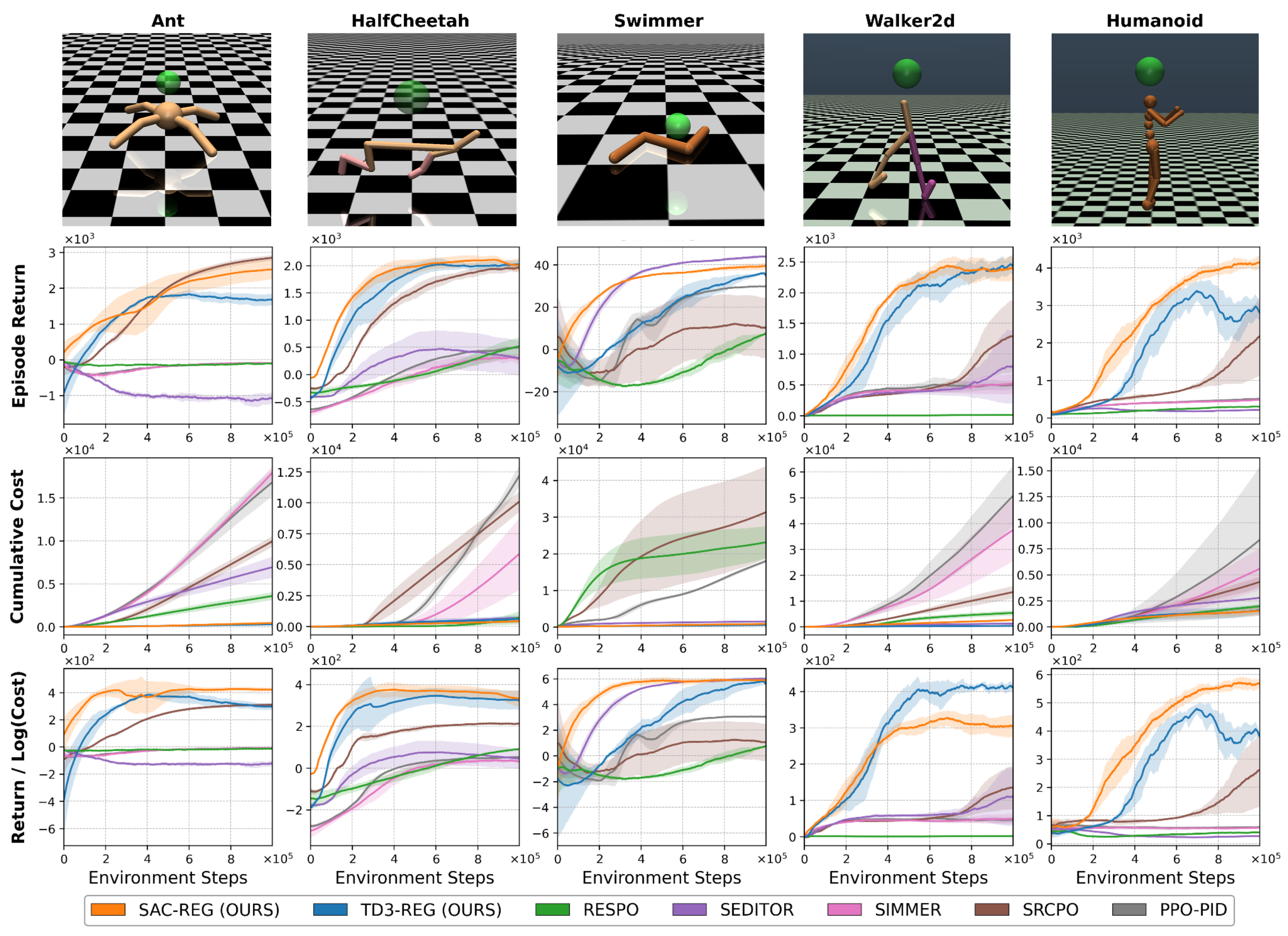
本研究提出了一种约束感知强化学习方法,旨在缓解训练过程中因探索而产生的非安全行为,通过减少约束违反同时保持任务性能。现有方法通常依赖于单一策略来联合优化奖励和安全性,这可能由于目标冲突而导致不稳定,或者使用外部安全过滤器来覆盖动作,这需要先验系统知识。本文提出了一种模块化的成本感知调节器,该调节器基于预测的约束违反来缩放智能体的动作,通过平滑的动作调制来保持探索,而不是覆盖策略。该调节器经过训练,可以最小化约束违反,同时避免对动作的退化抑制。我们的方法与SAC和TD3等离线强化学习方法无缝集成,并在具有稀疏成本的Safety Gym运动任务上实现了最先进的回报与成本比率,与先前方法相比,约束违反减少了高达126倍,同时回报增加了一个数量级以上。
🔬 方法详解
问题定义:安全强化学习旨在训练智能体在满足特定约束条件的同时最大化奖励。现有方法要么使用单一策略同时优化奖励和约束,导致优化困难;要么使用外部安全过滤器直接干预智能体的动作,但需要预先知道系统的安全约束,限制了其通用性。这些方法在探索过程中容易出现不安全行为,且难以在复杂环境中取得良好效果。
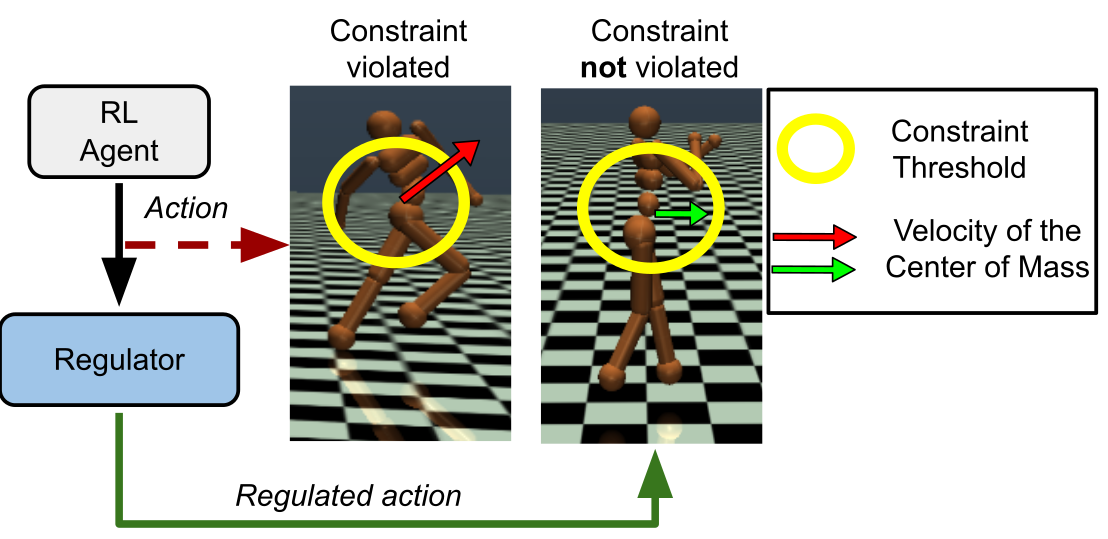
核心思路:论文的核心思路是引入一个独立的、可学习的成本感知调节器,该调节器不直接覆盖智能体的动作,而是根据预测的约束违反程度,自适应地缩放智能体的动作。这种方法允许智能体在探索过程中进行更细粒度的控制,避免了对策略的硬性干预,从而更好地平衡探索和安全性。调节器的目标是最小化约束违反,同时避免过度抑制动作。
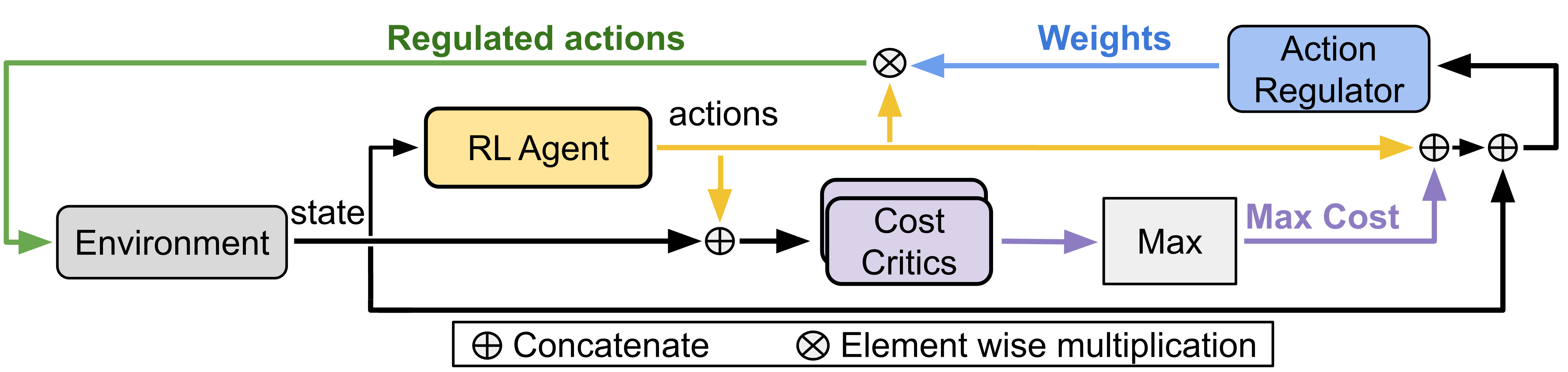
技术框架:整体框架包含一个标准的强化学习智能体(例如,基于SAC或TD3),以及一个独立的成本感知调节器。智能体根据环境状态输出一个动作,调节器接收该动作和环境状态,预测约束违反程度,并根据预测结果对动作进行缩放。缩放后的动作被发送到环境中执行,环境返回奖励和新的状态。调节器通过最小化约束违反和避免动作抑制进行训练。
关键创新:最重要的创新点在于使用自适应动作缩放来代替传统的动作覆盖或硬约束。这种方法允许智能体在探索过程中进行更灵活的调整,避免了对策略的过度干预,从而更好地平衡探索和安全性。此外,独立的调节器设计使得该方法可以很容易地集成到现有的强化学习算法中。
关键设计:调节器通常使用神经网络来实现,输入是环境状态和智能体输出的动作,输出是动作的缩放因子。损失函数包含两部分:一部分是约束违反损失,用于惩罚违反约束的行为;另一部分是动作抑制损失,用于避免过度抑制动作。具体参数设置包括神经网络的结构、学习率、损失函数的权重等。这些参数需要根据具体的任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在Safety Gym的运动任务中取得了显著的性能提升。与现有方法相比,约束违反减少了高达126倍,同时回报增加了一个数量级以上。这表明该方法能够有效地平衡探索和安全性,在保证任务性能的同时,显著降低了违反约束的风险。
🎯 应用场景
该研究成果可应用于各种需要安全保障的强化学习任务,例如自动驾驶、机器人控制、资源管理等。在这些场景中,智能体需要在复杂的环境中进行决策,同时避免违反安全约束。通过使用该方法,可以显著提高智能体的安全性和可靠性,降低事故发生的风险,具有重要的实际应用价值。
📄 摘要(原文)
Safe reinforcement learning (RL) seeks to mitigate unsafe behaviors that arise from exploration during training by reducing constraint violations while maintaining task performance. Existing approaches typically rely on a single policy to jointly optimize reward and safety, which can cause instability due to conflicting objectives, or they use external safety filters that override actions and require prior system knowledge. In this paper, we propose a modular cost-aware regulator that scales the agent's actions based on predicted constraint violations, preserving exploration through smooth action modulation rather than overriding the policy. The regulator is trained to minimize constraint violations while avoiding degenerate suppression of actions. Our approach integrates seamlessly with off-policy RL methods such as SAC and TD3, and achieves state-of-the-art return-to-cost ratios on Safety Gym locomotion tasks with sparse costs, reducing constraint violations by up to 126 times while increasing returns by over an order of magnitude compared to prior methods.