XGrasp: Gripper-Aware Grasp Detection with Multi-Gripper Data Generation
作者: Yeonseo Lee, Jungwook Mun, Hyosup Shin, Guebin Hwang, Junhee Nam, Taeyeop Lee, Sungho Jo
分类: cs.RO, cs.AI
发布日期: 2025-10-13
💡 一句话要点
XGrasp:提出一种支持多夹爪的实时、gripper感知的抓取检测框架。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人抓取 gripper感知 多夹爪 对比学习 零样本学习
📋 核心要点
- 现有机器人抓取方法通常只针对单一夹爪类型设计,限制了其在需要多样化末端执行器的实际场景中的应用。
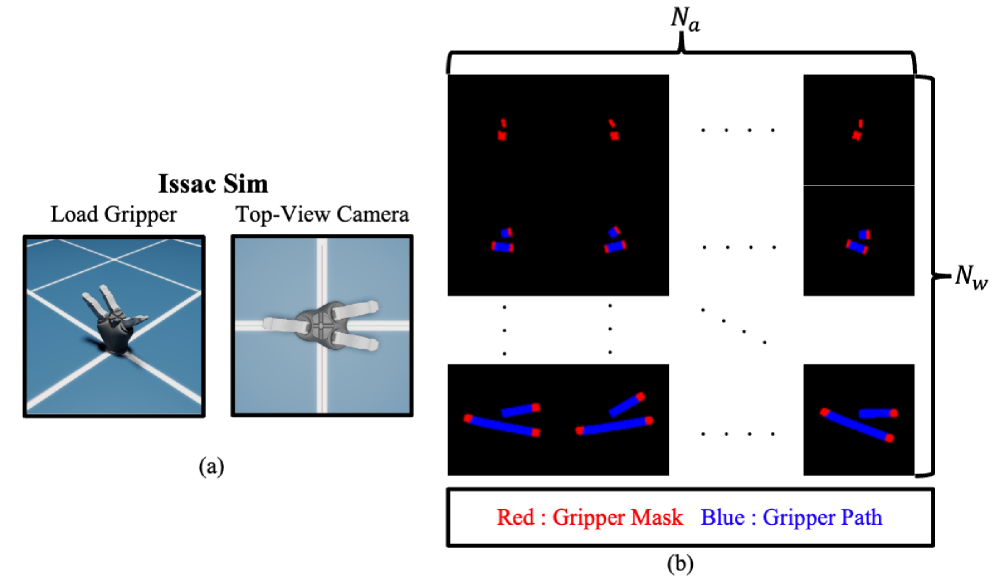
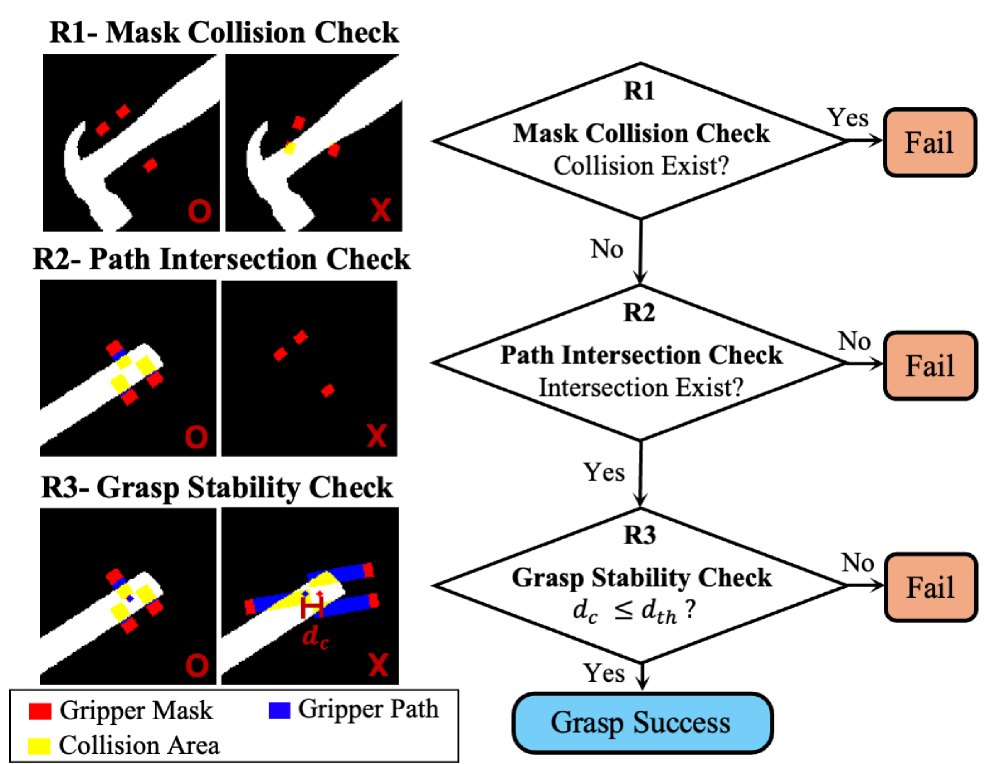
- XGrasp通过系统地使用多夹爪标注增强现有数据集,并采用分层两阶段架构,实现gripper感知的抓取检测。
- 实验结果表明,XGrasp在多种夹爪类型上实现了具有竞争力的抓取成功率,并显著提高了推理速度。
📝 摘要(中文)
本文提出了一种名为XGrasp的实时、gripper感知的抓取检测框架,旨在有效处理多种夹爪配置,解决现有机器人抓取方法通常只针对单一夹爪类型设计的局限性。该方法通过系统地使用多夹爪标注增强现有数据集,从而解决数据稀缺问题。XGrasp采用分层两阶段架构:第一阶段,抓取点预测器(GPP)利用全局场景信息和夹爪规格识别最佳位置;第二阶段,角度-宽度预测器(AWP)使用局部特征细化抓取角度和宽度。AWP模块中的对比学习通过学习基本的抓取特征,实现了对未见过的夹爪的零样本泛化。该模块化框架可与视觉基础模型无缝集成,为未来的视觉-语言能力提供途径。实验结果表明,该方法在各种夹爪类型上都具有竞争力的抓取成功率,并且与现有的gripper感知方法相比,推理速度有了显著提高。
🔬 方法详解
问题定义:现有机器人抓取方法通常针对特定类型的夹爪进行设计,缺乏对不同夹爪的通用性。在实际应用中,需要根据不同的物体和任务选择合适的夹爪,因此需要一种能够处理多种夹爪的抓取检测方法。现有的gripper感知方法推理速度较慢,难以满足实时性要求。
核心思路:XGrasp的核心思路是利用一个分层的两阶段框架,首先预测抓取点,然后细化抓取角度和宽度。通过对比学习,使模型能够学习到通用的抓取特征,从而实现对未见过的夹爪的零样本泛化。通过模块化设计,可以方便地与视觉基础模型集成。
技术框架:XGrasp采用两阶段架构。第一阶段是抓取点预测器(GPP),它使用全局场景信息和夹爪规格来预测最佳抓取位置。第二阶段是角度-宽度预测器(AWP),它使用局部特征来细化抓取角度和宽度。AWP模块使用对比学习来学习通用的抓取特征。整个框架可以与视觉基础模型集成,实现更强大的抓取能力。
关键创新:XGrasp的关键创新在于:1) 提出了一个gripper感知的抓取检测框架,可以处理多种夹爪;2) 使用对比学习来实现对未见过的夹爪的零样本泛化;3) 提出了一个分层的两阶段架构,可以有效地预测抓取点、角度和宽度。4) 通过数据增强策略,有效解决了多夹爪数据稀缺的问题。
关键设计:GPP使用全局场景信息和夹爪规格作为输入,预测抓取点的置信度图。AWP使用局部特征作为输入,预测抓取角度和宽度。对比学习的目标是使相似的抓取配置在特征空间中更接近,不相似的抓取配置更远离。数据增强策略包括随机旋转、缩放和平移等。损失函数包括抓取点预测损失、角度预测损失和宽度预测损失。
🖼️ 关键图片
📊 实验亮点
XGrasp在多种夹爪类型上实现了具有竞争力的抓取成功率,并且与现有的gripper感知方法相比,推理速度有了显著提高。通过对比学习,XGrasp实现了对未见过的夹爪的零样本泛化。项目主页提供了更多实验细节和可视化结果。
🎯 应用场景
XGrasp可应用于各种机器人抓取场景,例如工业自动化、物流分拣、家庭服务机器人等。该方法能够处理多种夹爪,可以根据不同的物体和任务选择合适的夹爪,提高抓取的灵活性和效率。未来,XGrasp可以与视觉-语言模型结合,实现更智能的抓取。
📄 摘要(原文)
Most robotic grasping methods are typically designed for single gripper types, which limits their applicability in real-world scenarios requiring diverse end-effectors. We propose XGrasp, a real-time gripper-aware grasp detection framework that efficiently handles multiple gripper configurations. The proposed method addresses data scarcity by systematically augmenting existing datasets with multi-gripper annotations. XGrasp employs a hierarchical two-stage architecture. In the first stage, a Grasp Point Predictor (GPP) identifies optimal locations using global scene information and gripper specifications. In the second stage, an Angle-Width Predictor (AWP) refines the grasp angle and width using local features. Contrastive learning in the AWP module enables zero-shot generalization to unseen grippers by learning fundamental grasping characteristics. The modular framework integrates seamlessly with vision foundation models, providing pathways for future vision-language capabilities. The experimental results demonstrate competitive grasp success rates across various gripper types, while achieving substantial improvements in inference speed compared to existing gripper-aware methods. Project page: https://sites.google.com/view/xgrasp