RoVer: Robot Reward Model as Test-Time Verifier for Vision-Language-Action Model
作者: Mingtong Dai, Lingbo Liu, Yongjie Bai, Yang Liu, Zhouxia Wang, Rui SU, Chunjie Chen, Liang Lin, Xinyu Wu
分类: cs.RO
发布日期: 2025-10-13 (更新: 2025-10-14)
💡 一句话要点
RoVer:利用机器人奖励模型作为测试时验证器,提升视觉-语言-动作模型的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视觉-语言-动作模型 机器人奖励模型 测试时验证 动作规划 机器人学习 模型优化 方向引导采样
📋 核心要点
- 现有VLA模型依赖大规模数据和模型尺寸提升性能,但机器人数据收集成本高昂,限制了模型发展。
- RoVer利用机器人过程奖励模型(PRM)作为测试时验证器,无需修改模型结构即可提升VLA模型性能。
- RoVer通过缓存感知特征,在相同计算预算下评估更多候选动作,实现测试时扩展并提升决策质量。
📝 摘要(中文)
视觉-语言-动作(VLA)模型已成为具身智能的重要范式,但进一步的性能提升通常依赖于扩大训练数据和模型规模,这对于机器人技术来说成本高昂,并且从根本上受到数据收集成本的限制。我们提出了RoVer,一个具身的测试时扩展框架,它使用机器人过程奖励模型(PRM)作为测试时验证器,以增强现有VLA模型的能力,而无需修改它们的架构或权重。具体来说,RoVer (i)分配基于标量的过程奖励来评估候选动作的可靠性,以及(ii)预测动作空间方向以进行候选扩展/细化。在推理过程中,RoVer从基本策略并发生成多个候选动作,沿着PRM预测的方向扩展它们,然后使用PRM对所有候选动作进行评分,以选择最佳执行动作。值得注意的是,通过缓存共享的感知特征,它可以分摊感知成本,并在相同的测试时计算预算下评估更多的候选动作。本质上,我们的方法有效地将可用的计算资源转化为更好的动作决策,实现了测试时扩展的优势,而无需额外的训练开销。我们的贡献有三方面:(1)一个通用的、即插即用的VLA测试时扩展框架;(2)一个PRM,它联合提供标量过程奖励和一个动作空间方向来指导探索;(3)一种高效的方向引导采样策略,它利用共享的感知缓存,从而在推理过程中实现可扩展的候选生成和选择。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在具身智能任务中表现出色,但进一步提升性能通常需要增加训练数据量和模型规模。然而,在机器人领域,数据收集成本非常高昂,这限制了VLA模型的进一步发展。因此,如何在不增加训练成本的前提下,提升现有VLA模型的性能,是一个亟待解决的问题。
核心思路:RoVer的核心思路是在测试时对VLA模型的输出进行验证和优化。它利用一个机器人过程奖励模型(PRM)来评估候选动作的可靠性,并预测动作空间方向以进行候选扩展/细化。通过生成多个候选动作,并使用PRM进行评分和选择,RoVer能够有效地提升动作决策的质量。这种方法的核心在于将计算资源用于更好的动作决策,而不是用于训练更大的模型。
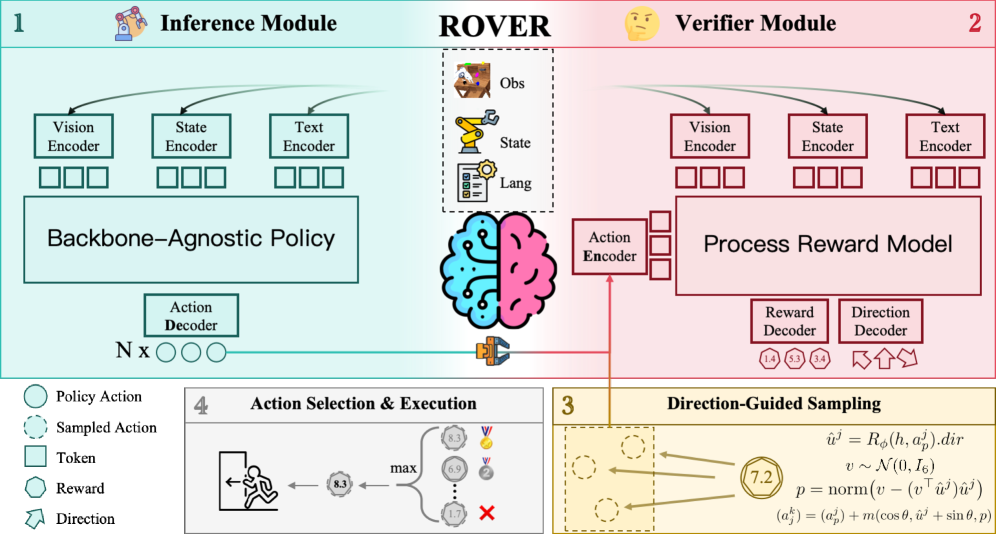
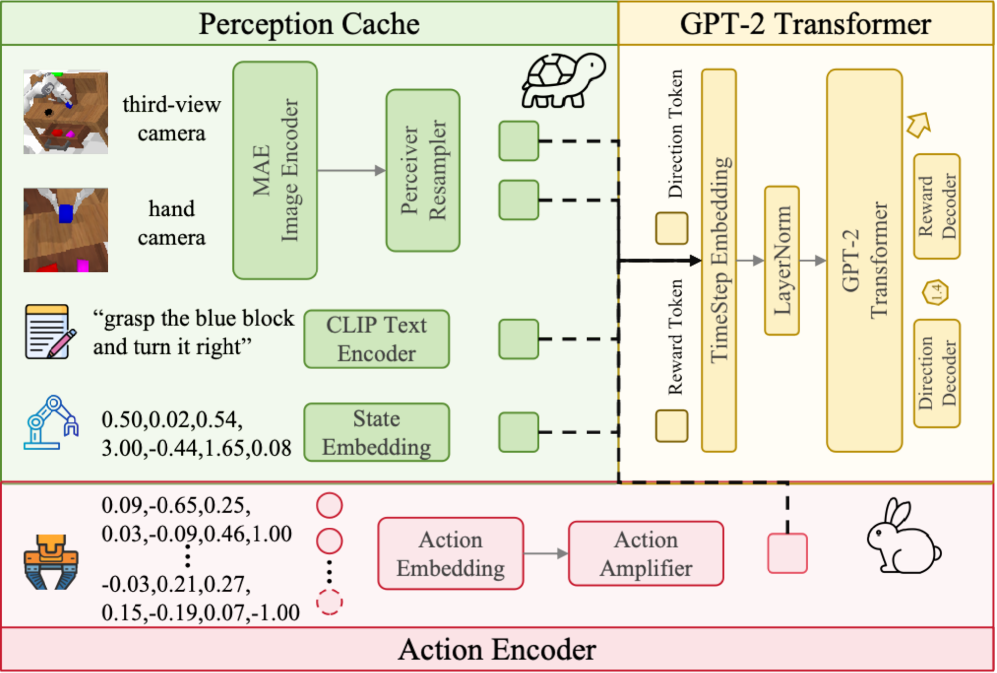
技术框架:RoVer的整体框架包含以下几个主要模块:1) VLA模型:作为基础策略,生成初始的候选动作。2) 机器人过程奖励模型(PRM):用于评估候选动作的可靠性,并预测动作空间方向。3) 候选动作生成模块:基于VLA模型的输出和PRM的预测,生成多个候选动作。4) 动作选择模块:使用PRM对所有候选动作进行评分,并选择最佳的动作执行。5) 共享感知缓存:用于缓存共享的感知特征,以降低计算成本。整个流程是,VLA模型给出初步动作,PRM评估并指导生成更多候选动作,最后PRM选出最优动作。
关键创新:RoVer的关键创新在于提出了一个基于机器人过程奖励模型(PRM)的测试时验证框架。与传统的VLA模型相比,RoVer不需要额外的训练数据或模型参数,而是通过在测试时对候选动作进行评估和优化,来提升模型的性能。此外,RoVer还提出了一种高效的方向引导采样策略,利用共享的感知缓存,从而在推理过程中实现可扩展的候选生成和选择。
关键设计:PRM的设计是关键。它不仅要给出标量奖励,还要预测动作空间的方向,指导候选动作的生成。具体实现细节(如PRM的网络结构、损失函数等)论文中可能有所描述,但摘要中未明确提及。共享感知缓存的设计也至关重要,它需要高效地存储和检索感知特征,以降低计算成本。具体缓存策略和实现细节也需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
论文提出的RoVer框架能够在不增加训练成本的前提下,显著提升VLA模型的性能。具体实验结果需要在论文中查找,但可以预期的是,RoVer在各种机器人任务中都能够取得明显的性能提升,例如更高的成功率、更短的完成时间等。与传统的VLA模型相比,RoVer的性能提升幅度将取决于PRM的质量和候选动作生成策略的有效性。
🎯 应用场景
RoVer框架具有广泛的应用前景,可以应用于各种机器人任务中,例如导航、操作、抓取等。通过提升VLA模型的性能,RoVer可以使机器人更加智能和自主,从而在工业自动化、家庭服务、医疗保健等领域发挥更大的作用。此外,RoVer的测试时扩展方法也可以推广到其他类型的AI模型中,例如自然语言处理模型和图像识别模型。
📄 摘要(原文)
Vision-Language-Action (VLA) models have become a prominent paradigm for embodied intelligence, yet further performance improvements typically rely on scaling up training data and model size -- an approach that is prohibitively expensive for robotics and fundamentally limited by data collection costs. We address this limitation with $\mathbf{RoVer}$, an embodied test-time scaling framework that uses a $\mathbf{Ro}$bot Process Reward Model (PRM) as a Test-Time $\mathbf{Ver}$ifier to enhance the capabilities of existing VLA models without modifying their architectures or weights. Specifically, RoVer (i) assigns scalar-based process rewards to evaluate the reliability of candidate actions, and (ii) predicts an action-space direction for candidate expansion/refinement. During inference, RoVer generates multiple candidate actions concurrently from the base policy, expands them along PRM-predicted directions, and then scores all candidates with PRM to select the optimal action for execution. Notably, by caching shared perception features, it can amortize perception cost and evaluate more candidates under the same test-time computational budget. Essentially, our approach effectively transforms available computing resources into better action decision-making, realizing the benefits of test-time scaling without extra training overhead. Our contributions are threefold: (1) a general, plug-and-play test-time scaling framework for VLAs; (2) a PRM that jointly provides scalar process rewards and an action-space direction to guide exploration; and (3) an efficient direction-guided sampling strategy that leverages a shared perception cache to enable scalable candidate generation and selection during inference.