Real2USD: Scene Representations in Universal Scene Description Language
作者: Christopher D. Hsu, Pratik Chaudhari
分类: cs.RO
发布日期: 2025-10-12
备注: 8 pages, 10 figures, 1 table
🔗 代码/项目: GITHUB
💡 一句话要点
提出Real2USD系统,利用通用场景描述语言USD增强LLM在机器人任务中的场景理解与规划能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 通用场景描述 大型语言模型 机器人 场景理解 环境表示 三维重建 语义分割
📋 核心要点
- 现有机器人环境表示方法通常针对特定任务定制,缺乏通用性和可扩展性,难以支持复杂推理和规划。
- 提出Real2USD系统,利用USD语言作为机器人环境的通用表示,该语言具有丰富的几何、光度和语义信息。
- 通过真实机器人实验和模拟环境验证了Real2USD系统的有效性,展示了其在场景理解、复杂推理和规划方面的能力。
📝 摘要(中文)
大型语言模型(LLM)能够帮助机器人推理抽象的任务规范。这需要用基于自然语言的先验知识来增强机器人使用的经典环境表示。目前已有一些方法,但它们是为特定任务定制的,例如用于导航的视觉-语言模型,用于映射的语言引导神经辐射场等。本文认为,通用场景描述(USD)语言是基于LLM的机器人任务中环境的几何、光度和语义信息的有效且通用的表示。我们的论点很简单:USD是一种基于XML的场景图,LLM和人类都可以读取,并且足够丰富以支持几乎任何任务——皮克斯开发了这种语言来存储资产、场景甚至电影。我们展示了一个“Real to USD”系统,该系统使用配备激光雷达和RGB相机的宇树Go2四足机器人,该系统(i)构建了具有各种对象和具有大量玻璃的挑战性设置的室内环境的显式USD表示,以及(ii)使用谷歌的Gemini解析USD以演示场景理解、复杂推理和规划。我们还在使用Nvidia的Issac Sim的模拟仓库和医院环境中研究了该系统的不同方面。代码可在https://github.com/grasp-lyrl/Real2USD 获取。
🔬 方法详解
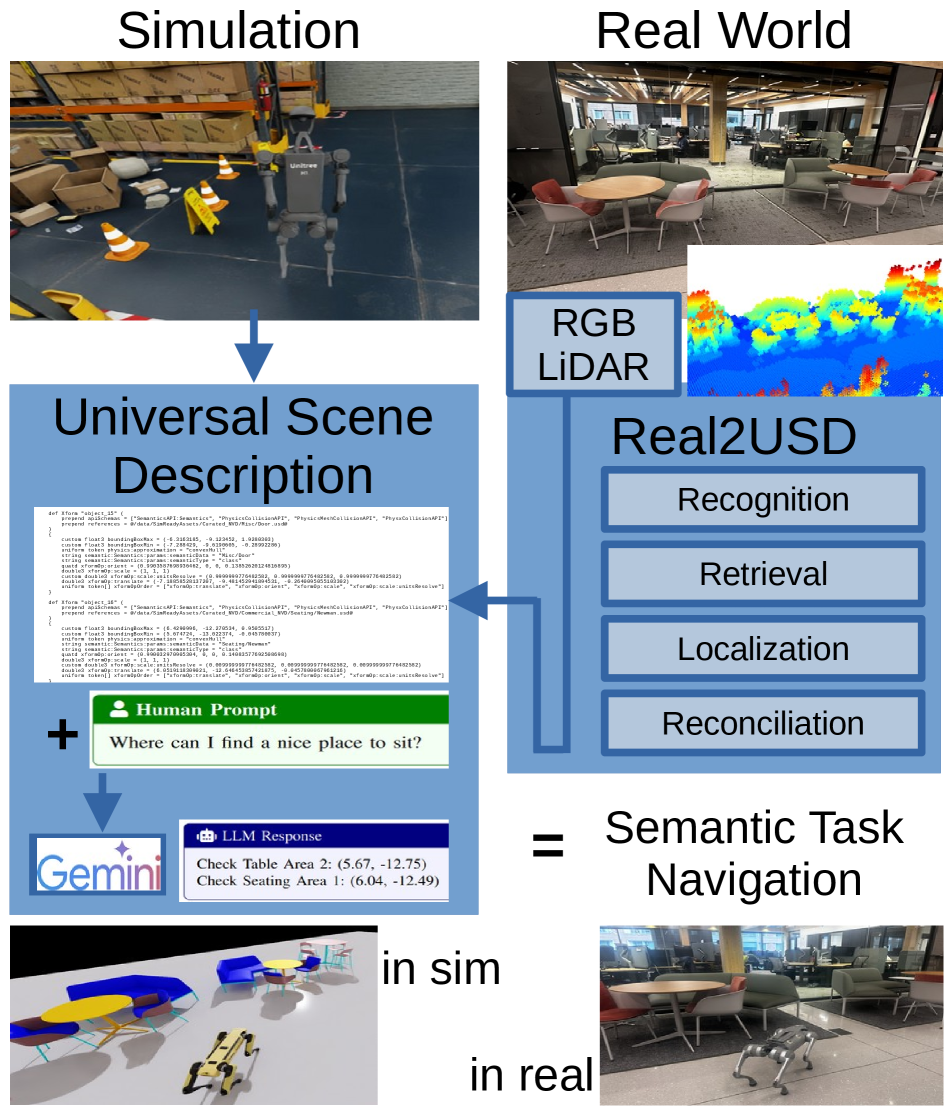
问题定义:现有机器人环境表示方法,如视觉-语言模型和神经辐射场,通常针对特定任务设计,缺乏通用性,难以支持LLM进行复杂的场景理解和推理。这些方法在处理复杂环境,例如包含大量玻璃的场景时,也存在局限性。因此,需要一种通用的、可扩展的、易于LLM理解的环境表示方法。
核心思路:利用通用场景描述(USD)语言作为机器人环境的统一表示。USD是一种基于XML的场景图,可以同时被LLM和人类读取,并且能够存储丰富的几何、光度和语义信息。通过将真实世界的场景转换为USD格式,可以使LLM能够更好地理解环境,从而支持更高级的机器人任务。
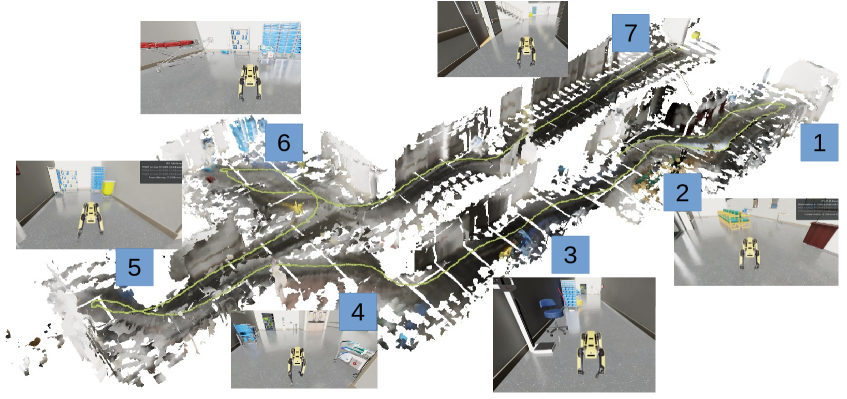
技术框架:Real2USD系统主要包含两个阶段:(1) 场景重建:使用配备激光雷达和RGB相机的宇树Go2四足机器人扫描室内环境,并将其转换为USD格式。该阶段涉及点云处理、三维重建、语义分割等技术。(2) 场景理解与规划:使用Google的Gemini等LLM解析USD场景图,进行场景理解、复杂推理和规划。LLM可以根据USD中的信息,例如物体的位置、大小、材质等,来执行各种任务,例如导航、物体操作等。
关键创新:该论文的关键创新在于将USD语言引入机器人领域,并将其作为LLM进行场景理解和规划的通用表示。与现有的方法相比,USD具有更强的通用性和可扩展性,可以支持更广泛的机器人任务。此外,该论文还提出了一个Real2USD系统,实现了从真实世界到USD场景的自动转换。
关键设计:Real2USD系统的关键设计包括:(1) 使用激光雷达和RGB相机进行场景重建,以获取精确的几何和纹理信息。(2) 使用语义分割算法对场景中的物体进行分类,并将语义信息添加到USD场景图中。(3) 使用Google的Gemini等LLM解析USD场景图,并根据场景信息进行推理和规划。(4) 在模拟环境中使用Nvidia的Issac Sim进行系统验证和性能评估。
🖼️ 关键图片

📊 实验亮点
该论文通过真实机器人实验和模拟环境验证了Real2USD系统的有效性。在真实环境中,Real2USD系统能够成功构建室内环境的USD表示,并使用Gemini进行场景理解和规划。在模拟环境中,Real2USD系统在仓库和医院场景中表现出良好的性能,证明了其在复杂环境中的适应性。实验结果表明,使用USD作为环境表示可以显著提高LLM在机器人任务中的性能。
🎯 应用场景
Real2USD系统具有广泛的应用前景,例如:(1) 智能家居:机器人可以利用Real2USD系统理解家庭环境,并执行各种任务,例如清洁、物品整理等。(2) 仓储物流:机器人可以利用Real2USD系统进行货物识别、路径规划等。(3) 医疗保健:机器人可以利用Real2USD系统辅助医生进行手术、护理病人等。该研究为LLM在机器人领域的应用奠定了基础。
📄 摘要(原文)
Large Language Models (LLMs) can help robots reason about abstract task specifications. This requires augmenting classical representations of the environment used by robots with natural language-based priors. There are a number of existing approaches to doing so, but they are tailored to specific tasks, e.g., visual-language models for navigation, language-guided neural radiance fields for mapping, etc. This paper argues that the Universal Scene Description (USD) language is an effective and general representation of geometric, photometric and semantic information in the environment for LLM-based robotics tasks. Our argument is simple: a USD is an XML-based scene graph, readable by LLMs and humans alike, and rich enough to support essentially any task -- Pixar developed this language to store assets, scenes and even movies. We demonstrate a ``Real to USD'' system using a Unitree Go2 quadruped robot carrying LiDAR and a RGB camera that (i) builds an explicit USD representation of indoor environments with diverse objects and challenging settings with lots of glass, and (ii) parses the USD using Google's Gemini to demonstrate scene understanding, complex inferences, and planning. We also study different aspects of this system in simulated warehouse and hospital settings using Nvidia's Issac Sim. Code is available at https://github.com/grasp-lyrl/Real2USD .