Gain Tuning Is Not What You Need: Reward Gain Adaptation for Constrained Locomotion Learning
作者: Arthicha Srisuchinnawong, Poramate Manoonpong
分类: cs.RO
发布日期: 2025-10-12
备注: RSS 2025
DOI: 10.15607/RSS.2025.XXI.123
💡 一句话要点
提出ROGER:通过在线奖励增益自适应实现约束下的机器人运动学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人运动学习 强化学习 奖励函数设计 约束满足 在线自适应 四足机器人 具身智能
📋 核心要点
- 现有机器人运动学习方法依赖离线奖励权重调整,难以保证训练过程中的约束满足。
- ROGER通过具身交互过程中的惩罚,在线自适应调整奖励权重增益,平衡性能与约束。
- 实验表明,ROGER在四足机器人和MuJoCo基准测试中,性能提升显著,约束违反更少。
📝 摘要(中文)
现有的机器人运动学习技术严重依赖于离线选择合适的奖励权重增益,并且无法保证训练期间满足约束条件(即避免违反约束)。为了解决这两个问题,本文提出了一种名为ROGER(Reward-Oriented Gains via Embodied Regulation)的方法,该方法基于具身交互过程中收到的惩罚在线调整奖励权重增益。当学习接近约束阈值时,正向奖励(主要奖励)和负向奖励(惩罚)增益之间的比率会自动降低,以避免违反约束。相反,当学习处于安全状态时,该比率会增加,以优先考虑性能。在60公斤的四足机器人上,ROGER在多个学习试验中实现了接近零的约束违反。与最先进的同类技术相比,它还实现了高达50%的主要奖励提升。在MuJoCo连续运动基准测试中,包括单腿跳跃机器人,ROGER表现出与默认奖励函数训练的模型相当或高达100%的更高性能,以及60%的更低扭矩使用和方向偏差。最后,仅用一小时就从头实现了物理四足机器人的真实世界运动学习,且没有发生任何跌倒。因此,这项工作有助于约束满足的真实世界持续机器人运动学习,并简化了奖励权重增益调整,从而可能促进物理机器人和在真实世界中学习的机器人的开发。
🔬 方法详解
问题定义:现有机器人运动学习方法在设计奖励函数时,需要手动调整正向奖励和惩罚项的权重,这非常耗时且难以保证学习过程中满足约束条件,例如避免关节力矩超出限制或机器人跌倒。这些方法通常无法在真实环境中直接应用,需要大量的离线调试。
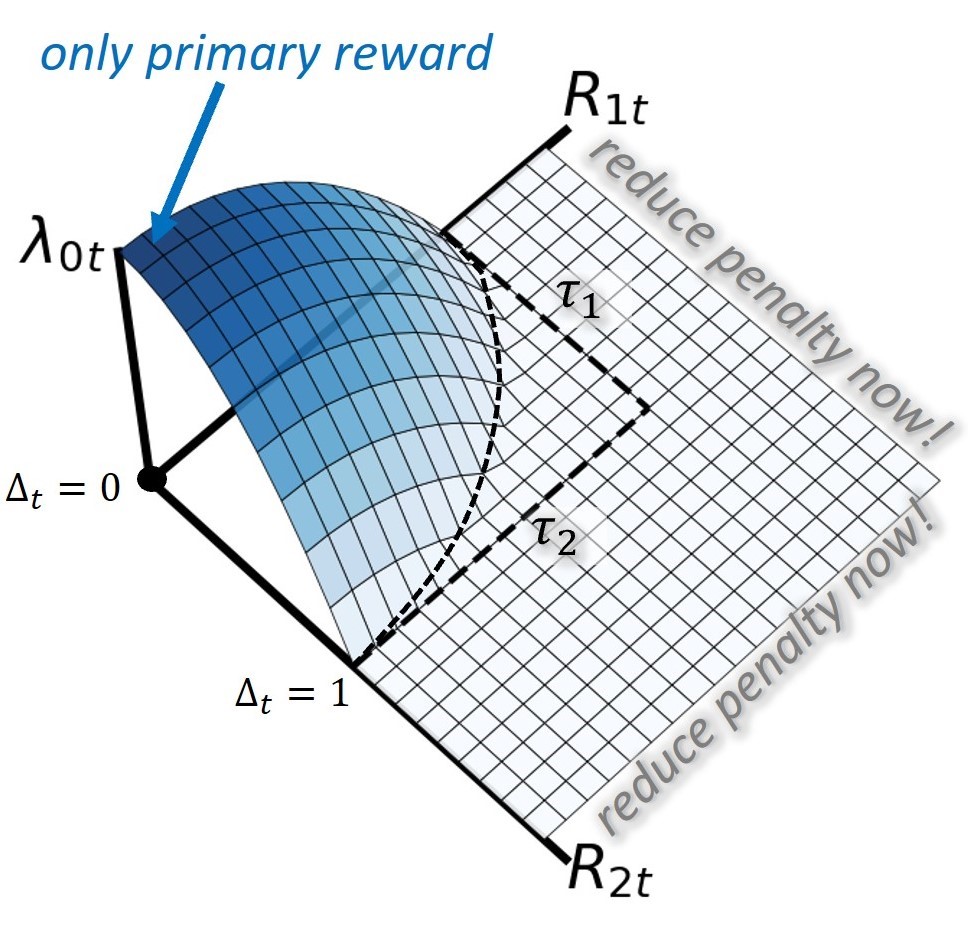
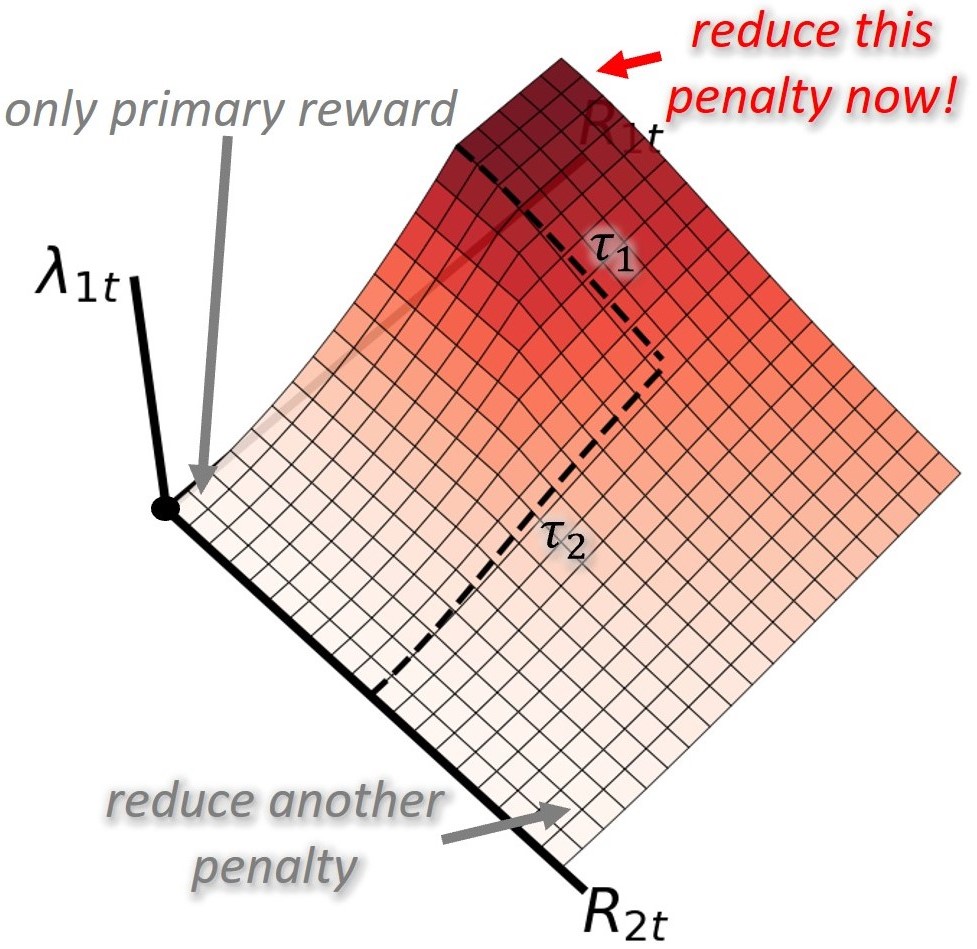
核心思路:ROGER的核心思路是根据机器人与环境的交互情况,动态调整正向奖励和惩罚项的权重。当机器人接近约束边界时,降低正向奖励的权重,提高惩罚项的权重,从而引导机器人远离危险区域。反之,当机器人处于安全区域时,提高正向奖励的权重,鼓励机器人追求更高的性能。
技术框架:ROGER方法主要包含以下几个阶段:1) 机器人与环境进行交互,执行动作并观察状态和奖励;2) 根据当前状态和动作,计算正向奖励和惩罚项;3) 根据历史惩罚情况,动态调整正向奖励和惩罚项的权重增益;4) 使用调整后的奖励信号训练强化学习策略;5) 重复以上步骤,直到策略收敛。
关键创新:ROGER的关键创新在于在线自适应调整奖励权重增益的机制。与传统的固定权重方法相比,ROGER能够根据机器人的实际表现动态调整奖励函数,从而更好地平衡性能和约束。这种自适应机制使得ROGER能够更容易地应用于真实世界的机器人学习任务中。
关键设计:ROGER的关键设计包括:1) 使用一个滑动窗口来记录历史惩罚情况;2) 根据滑动窗口中的惩罚值,计算一个调整因子,用于调整正向奖励和惩罚项的权重增益;3) 使用一个比例系数来控制调整因子的幅度;4) 采用合适的强化学习算法(例如PPO)来训练策略。
🖼️ 关键图片
📊 实验亮点
ROGER在60公斤四足机器人上实现了接近零的约束违反,并获得了比现有技术高50%的主要奖励。在MuJoCo基准测试中,ROGER的性能提升高达100%,扭矩使用和方向偏差降低了60%。最重要的是,ROGER仅用一小时就成功地从头训练了一个物理四足机器人,且没有发生任何跌倒,展示了其在真实世界机器人学习中的巨大潜力。
🎯 应用场景
ROGER方法可广泛应用于各种需要满足约束的机器人运动学习任务中,例如四足机器人、人形机器人、机械臂等。该方法能够简化奖励函数的设计过程,提高学习效率,并保证学习过程中的安全性。此外,ROGER还有潜力应用于其他强化学习领域,例如自动驾驶、资源调度等。
📄 摘要(原文)
Existing robot locomotion learning techniques rely heavily on the offline selection of proper reward weighting gains and cannot guarantee constraint satisfaction (i.e., constraint violation) during training. Thus, this work aims to address both issues by proposing Reward-Oriented Gains via Embodied Regulation (ROGER), which adapts reward-weighting gains online based on penalties received throughout the embodied interaction process. The ratio between the positive reward (primary reward) and negative reward (penalty) gains is automatically reduced as the learning approaches the constraint thresholds to avoid violation. Conversely, the ratio is increased when learning is in safe states to prioritize performance. With a 60-kg quadruped robot, ROGER achieved near-zero constraint violation throughout multiple learning trials. It also achieved up to 50% more primary reward than the equivalent state-of-the-art techniques. In MuJoCo continuous locomotion benchmarks, including a single-leg hopper, ROGER exhibited comparable or up to 100% higher performance and 60% less torque usage and orientation deviation compared to those trained with the default reward function. Finally, real-world locomotion learning of a physical quadruped robot was achieved from scratch within one hour without any falls. Therefore, this work contributes to constraint-satisfying real-world continual robot locomotion learning and simplifies reward weighting gain tuning, potentially facilitating the development of physical robots and those that learn in the real world.