UniCoD: Enhancing Robot Policy via Unified Continuous and Discrete Representation Learning
作者: Jianke Zhang, Yucheng Hu, Yanjiang Guo, Xiaoyu Chen, Yichen Liu, Wenna Chen, Chaochao Lu, Jianyu Chen
分类: cs.RO, cs.AI
发布日期: 2025-10-12 (更新: 2025-11-04)
💡 一句话要点
UniCoD:通过统一连续和离散表示学习增强机器人策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人策略学习 视觉-语言理解 视觉生成 统一表示学习 大规模预训练
📋 核心要点
- 现有通用机器人策略依赖视觉-语言或生成模型,但忽略了语义理解与视觉动态建模的结合。
- UniCoD通过大规模教学视频预训练,学习动态建模高维视觉特征,并微调以适应机器人动作。
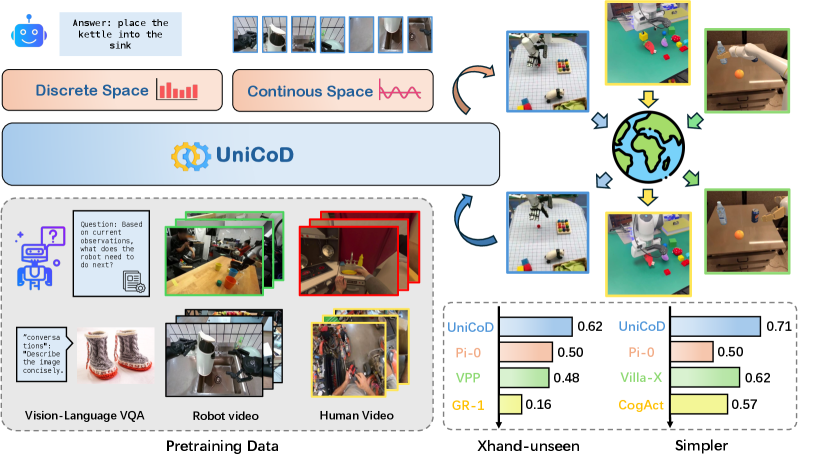
- 实验表明,UniCoD在模拟和真实环境中均优于现有方法,性能分别提升9%和12%。
📝 摘要(中文)
构建能够处理开放环境中多样化任务的通用机器人策略是机器人领域的核心挑战。为了利用大规模预训练的知识,先前的工作通常基于视觉-语言理解模型或生成模型构建通用策略。然而,来自视觉-语言预训练的语义理解和来自视觉生成预训练的视觉动态建模对于具身机器人至关重要。最近的生成和理解的统一模型已经证明了通过大规模预训练在理解和生成方面的强大能力。我们认为,机器人策略学习同样可以受益于理解、规划和连续未来表示学习的结合优势。基于这一洞察,我们引入了UniCoD,它通过在超过100万个互联网规模的教学操作视频上进行预训练,获得了动态建模高维视觉特征的能力。随后,UniCoD在从机器人embodiment收集的数据上进行微调,从而能够学习从预测表示到动作token的映射。大量的实验表明,我们的方法在模拟环境和真实世界分布外任务中始终优于基线方法,分别提高了9%和12%。
🔬 方法详解
问题定义:现有机器人策略学习方法通常依赖于视觉-语言模型或生成模型,但前者缺乏对视觉动态的建模能力,后者则忽略了语义理解。因此,如何同时利用语义理解和视觉动态建模的优势,构建更强大的通用机器人策略是一个关键问题。
核心思路:UniCoD的核心思路是利用统一的连续和离散表示学习框架,结合视觉-语言理解和视觉生成的能力。通过大规模预训练,模型能够学习到丰富的视觉语义信息和动态变化规律,从而更好地理解任务指令并规划执行动作。
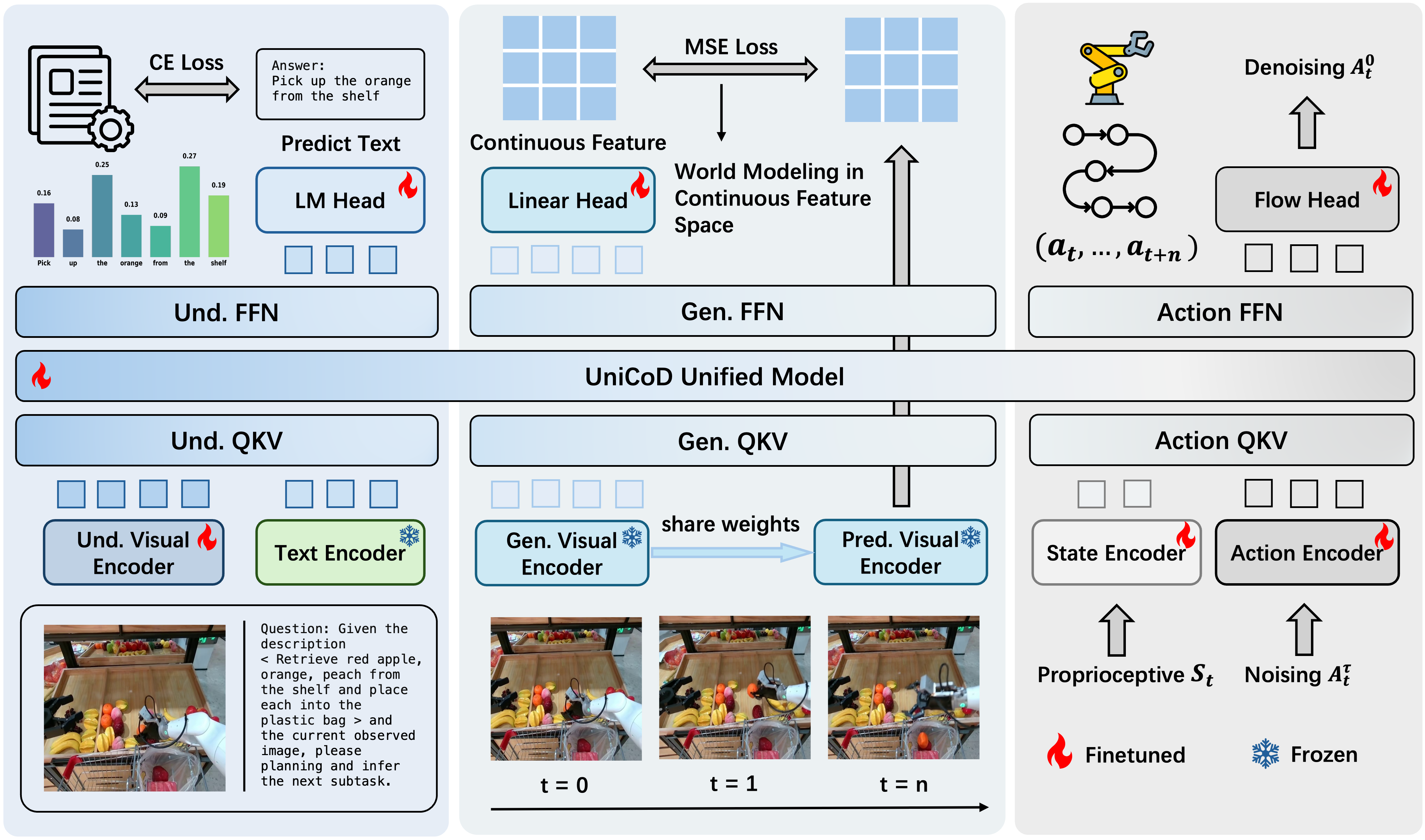
技术框架:UniCoD的整体框架包含两个主要阶段:预训练阶段和微调阶段。在预训练阶段,模型在大规模互联网教学视频上进行训练,学习视觉特征的动态建模能力。在微调阶段,模型在机器人收集的数据上进行微调,学习从预测的视觉表示到动作token的映射。模型架构基于Transformer,并采用统一的连续和离散表示方法,将视觉特征编码为连续向量,并将动作表示为离散token。
关键创新:UniCoD的关键创新在于其统一的连续和离散表示学习框架,该框架能够同时利用视觉-语言理解和视觉生成的能力。此外,UniCoD还采用了大规模预训练策略,从而能够学习到更丰富的视觉语义信息和动态变化规律。与现有方法相比,UniCoD能够更好地理解任务指令并规划执行动作,从而实现更强大的通用机器人策略。
关键设计:UniCoD的关键设计包括:1) 使用Transformer作为基础架构,以捕捉长程依赖关系;2) 采用对比学习损失函数,以提高视觉特征的表示能力;3) 使用离散动作token表示,以便于动作规划和执行;4) 在大规模互联网教学视频上进行预训练,以学习丰富的视觉语义信息和动态变化规律。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,UniCoD在模拟环境和真实世界分布外任务中均取得了显著的性能提升。在模拟环境中,UniCoD的性能比基线方法提高了9%。在真实世界分布外任务中,UniCoD的性能比基线方法提高了12%。这些结果表明,UniCoD能够有效地利用大规模预训练的知识,并将其迁移到新的任务和环境中。
🎯 应用场景
UniCoD具有广泛的应用前景,可用于各种机器人任务,如物体操作、导航、装配等。该研究的实际价值在于能够提高机器人的通用性和适应性,使其能够更好地处理复杂和动态的环境。未来,UniCoD有望应用于智能制造、家庭服务、医疗康复等领域,为人类提供更智能、更便捷的服务。
📄 摘要(原文)
Building generalist robot policies that can handle diverse tasks in open-ended environments is a central challenge in robotics. To leverage knowledge from large-scale pretraining, prior work (VLA) has typically built generalist policies either on top of vision-language understanding models (VLMs) or generative models. However, both semantic understanding from vision-language pretraining and visual dynamics modeling from visual-generation pretraining are crucial for embodied robots. Recent unified models of generation and understanding have demonstrated strong capabilities in both comprehension and generation through large-scale pretraining. We posit that robotic policy learning can likewise benefit from the combined strengths of understanding, planning, and continuous future representation learning. Building on this insight, we introduce UniCoD, which acquires the ability to dynamically model high-dimensional visual features through pretraining on over 1M internet-scale instructional manipulation videos. Subsequently, UniCoD is fine-tuned on data collected from the robot embodiment, enabling the learning of mappings from predictive representations to action tokens. Extensive experiments show our approach consistently outperforms baseline methods in terms of 9\% and 12\% across simulation environments and real-world out-of-distribution tasks.