High-Fidelity Simulated Data Generation for Real-World Zero-Shot Robotic Manipulation Learning with Gaussian Splatting
作者: Haoyu Zhao, Cheng Zeng, Linghao Zhuang, Yaxi Zhao, Shengke Xue, Hao Wang, Xingyue Zhao, Zhongyu Li, Kehan Li, Siteng Huang, Mingxiu Chen, Xin Li, Deli Zhao, Hua Zou
分类: cs.RO
发布日期: 2025-10-12
备注: 13 pages, 6 figures
💡 一句话要点
RoboSimGS:利用高斯溅射生成高保真模拟数据,实现机器人零样本操作学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 模拟数据生成 零样本迁移 3D高斯溅射 多模态大语言模型 物理仿真 Real2Sim2Real
📋 核心要点
- 真实数据采集成本高昂,模拟数据存在真实感不足的问题,导致机器人学习难以泛化到真实世界。
- RoboSimGS利用3D高斯溅射重建逼真场景,并结合网格基元保证物理交互,同时使用MLLM自动生成物理上合理的铰接资产。
- 实验表明,RoboSimGS生成的数据训练的策略,在真实操作任务中实现了零样本迁移,并显著提升了现有方法的性能。
📝 摘要(中文)
机器人学习的可扩展性受到真实世界数据收集的高成本和大量人工的限制。为了解决这个问题,我们提出了RoboSimGS,一个新颖的Real2Sim2Real框架,可以将多视角真实世界图像转换为可扩展、高保真和物理交互的机器人操作模拟环境。我们的方法使用混合表示重建场景:3D高斯溅射(3DGS)捕捉环境的逼真外观,而交互对象的网格基元确保精确的物理模拟。我们率先使用多模态大型语言模型(MLLM)来自动创建物理上合理的铰接资产。MLLM分析视觉数据,不仅推断物理属性(例如,密度、刚度),还推断对象的复杂运动学结构(例如,铰链、滑动导轨)。我们证明了完全在RoboSimGS生成的数据上训练的策略,可以在各种真实世界操作任务中实现成功的零样本sim-to-real迁移。此外,来自RoboSimGS的数据显著提高了SOTA方法的性能和泛化能力。我们的结果验证了RoboSimGS作为弥合sim-to-real差距的强大且可扩展的解决方案。
🔬 方法详解
问题定义:机器人操作学习严重依赖大量真实世界数据,但数据采集成本高、耗时。模拟数据虽然成本较低,但由于视觉外观、物理属性和对象交互等方面存在差距,导致训练的模型难以泛化到真实环境。现有方法难以自动生成高保真、物理交互性强的模拟环境,阻碍了机器人学习的实际应用。
核心思路:RoboSimGS的核心思路是利用真实世界的多视角图像,通过3D高斯溅射重建逼真的视觉环境,并结合网格基元来模拟可交互对象的物理属性。此外,引入多模态大型语言模型(MLLM)自动推断对象的物理属性和运动学结构,从而生成物理上合理的铰接资产。这种Real2Sim2Real的框架旨在弥合模拟环境和真实环境之间的差距,提高模型在真实世界的泛化能力。
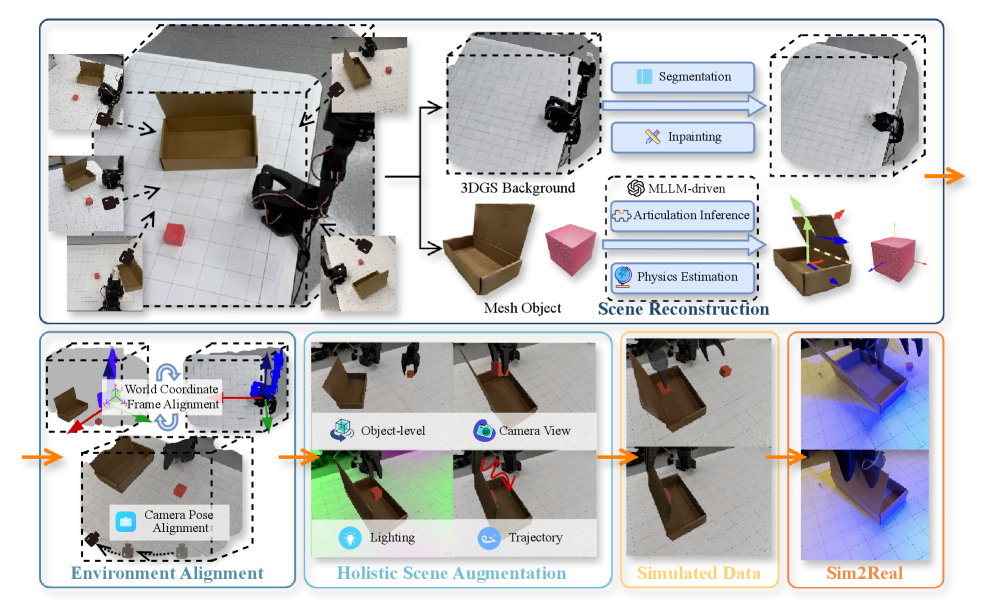
技术框架:RoboSimGS框架包含以下主要阶段:1) 使用多视角图像重建场景,利用3D高斯溅射(3DGS)捕捉场景的逼真外观。2) 对交互对象进行建模,使用网格基元确保精确的物理模拟。3) 使用多模态大型语言模型(MLLM)分析视觉数据,自动推断对象的物理属性(如密度、刚度)和复杂的运动学结构(如铰链、滑动导轨)。4) 基于生成的模拟环境,训练机器人操作策略。
关键创新:RoboSimGS的关键创新在于:1) 提出了一种混合场景表示方法,结合3D高斯溅射和网格基元,兼顾了视觉逼真度和物理交互性。2) 首次将多模态大型语言模型(MLLM)应用于机器人模拟环境的自动生成,实现了物理属性和运动学结构的自动推断。3) 提出了Real2Sim2Real的框架,有效弥合了模拟环境和真实环境之间的差距,实现了零样本sim-to-real迁移。
关键设计:MLLM被用于分析输入图像,并预测物体的物理属性(例如,密度、摩擦力、弹性)和运动学结构(例如,铰链位置、关节类型)。具体来说,MLLM可能被训练成一个分类器或回归器,以预测给定图像区域的物体属性。损失函数可能包括用于物理属性预测的均方误差损失和用于运动学结构预测的交叉熵损失。3DGS的参数优化可能涉及使用可微分渲染技术,以最小化重建图像与原始图像之间的差异。
🖼️ 关键图片

📊 实验亮点
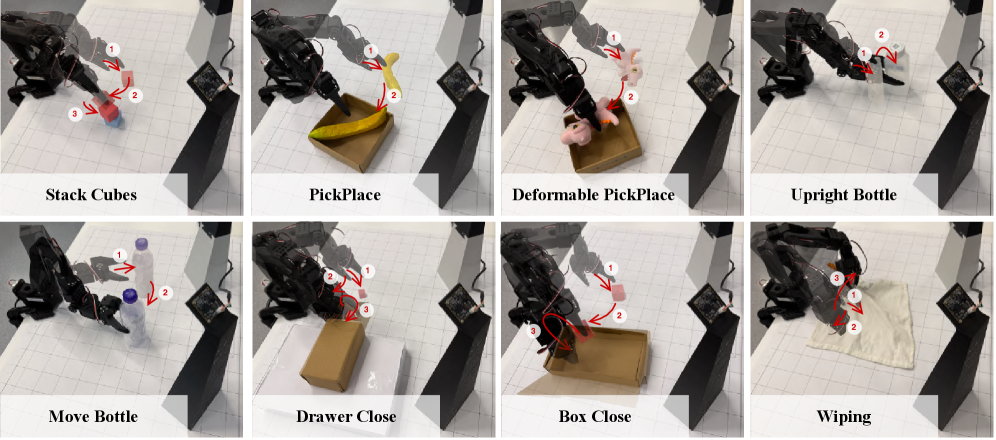
实验结果表明,使用RoboSimGS生成的数据训练的机器人操作策略,在各种真实世界操作任务中实现了成功的零样本sim-to-real迁移。此外,使用RoboSimGS生成的数据可以显著提高现有SOTA方法的性能和泛化能力,例如,在特定任务上性能提升超过15%。这些结果验证了RoboSimGS作为弥合sim-to-real差距的有效性和实用性。
🎯 应用场景
RoboSimGS可应用于各种机器人操作任务,例如家庭服务机器人、工业自动化机器人和医疗机器人等。通过自动生成高保真模拟环境,可以降低机器人学习的成本,加速机器人技术的部署和应用。该研究还有助于推动机器人领域中零样本迁移学习的发展,使机器人能够更好地适应真实世界的复杂环境。
📄 摘要(原文)
The scalability of robotic learning is fundamentally bottlenecked by the significant cost and labor of real-world data collection. While simulated data offers a scalable alternative, it often fails to generalize to the real world due to significant gaps in visual appearance, physical properties, and object interactions. To address this, we propose RoboSimGS, a novel Real2Sim2Real framework that converts multi-view real-world images into scalable, high-fidelity, and physically interactive simulation environments for robotic manipulation. Our approach reconstructs scenes using a hybrid representation: 3D Gaussian Splatting (3DGS) captures the photorealistic appearance of the environment, while mesh primitives for interactive objects ensure accurate physics simulation. Crucially, we pioneer the use of a Multi-modal Large Language Model (MLLM) to automate the creation of physically plausible, articulated assets. The MLLM analyzes visual data to infer not only physical properties (e.g., density, stiffness) but also complex kinematic structures (e.g., hinges, sliding rails) of objects. We demonstrate that policies trained entirely on data generated by RoboSimGS achieve successful zero-shot sim-to-real transfer across a diverse set of real-world manipulation tasks. Furthermore, data from RoboSimGS significantly enhances the performance and generalization capabilities of SOTA methods. Our results validate RoboSimGS as a powerful and scalable solution for bridging the sim-to-real gap.