Population-Coded Spiking Neural Networks for High-Dimensional Robotic Control
作者: Kanishkha Jaisankar, Xiaoyang Jiang, Feifan Liao, Jeethu Sreenivas Amuthan
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-12
💡 一句话要点
提出基于Population-coded SNN的DRL框架,用于高维机器人控制中的节能问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 脉冲神经网络 深度强化学习 机器人控制 节能计算 群体编码
📋 核心要点
- 深度强化学习在机器人控制中表现出色,但其高计算需求和能耗限制了在资源受限环境中的部署。
- 论文提出Population-coded Spiking Actor Network (PopSAN),结合SNN的节能特性和DRL的策略优化能力。
- 实验表明,该方法在保持控制性能的同时,相比传统ANN,能耗降低高达96.10%。
📝 摘要(中文)
本文提出了一种新颖的框架,将Population-coded Spiking Neural Networks (SNNs) 与深度强化学习 (DRL) 相结合,旨在解决机器人技术中高维连续控制任务的能效问题。该方法利用SNNs的事件驱动和异步计算特性,以及DRL的策略优化能力,在能效和控制性能之间取得平衡。核心是Population-coded Spiking Actor Network (PopSAN),它将高维观测编码为神经元群体活动,并通过基于梯度的更新实现策略学习。在Isaac Gym平台上,使用PixMC基准对Franka机械臂进行了评估,结果表明,与传统人工神经网络 (ANNs) 相比,该方法可节省高达 96.10% 的能源,同时保持相当的控制性能。训练后的SNN策略在手指位置跟踪和目标高度维持方面表现出鲁棒性。该研究表明,population-coded SNNs 有望成为资源受限应用中节能、高性能机器人控制的解决方案。
🔬 方法详解
问题定义:论文旨在解决高维机器人控制中,现有深度强化学习方法计算量大、能耗高,难以在资源受限的机器人平台上部署的问题。传统人工神经网络(ANNs)虽然在控制性能上表现良好,但其持续的计算需求导致较高的能量消耗,不适用于需要长时间运行或电池供电的机器人应用。
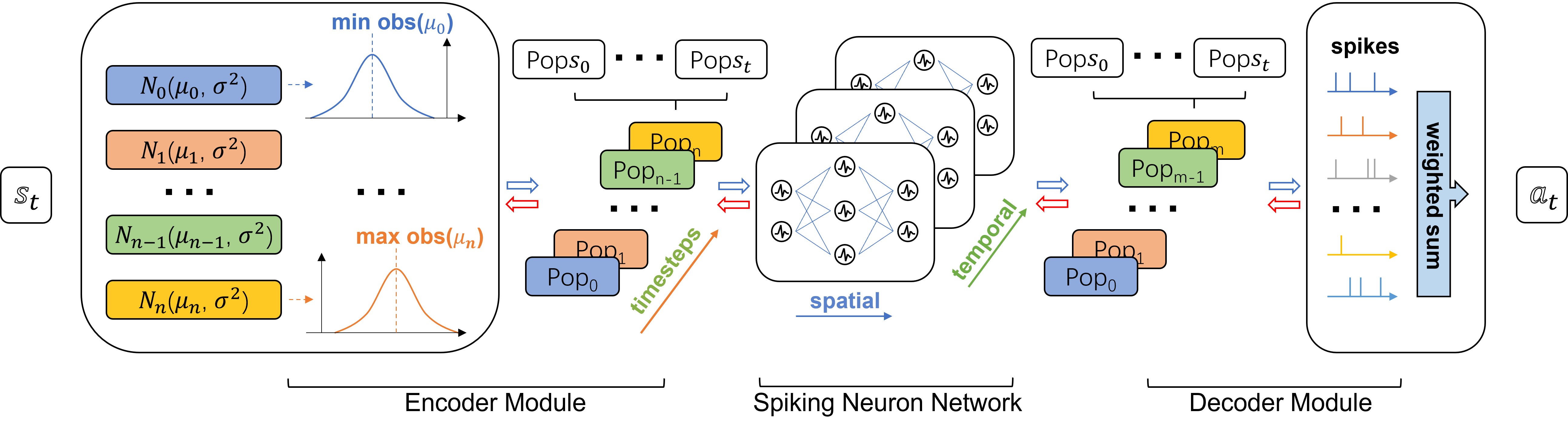
核心思路:论文的核心思路是利用脉冲神经网络(SNNs)的事件驱动和稀疏计算特性,降低计算能耗。通过将高维观测编码为神经元群体活动,并结合深度强化学习的策略优化能力,实现节能高效的机器人控制。Population coding 是一种有效的表示高维信息的方式,可以充分利用 SNN 的并行计算能力。
技术框架:整体框架包含一个Population-coded Spiking Actor Network (PopSAN) 和一个深度强化学习算法(具体算法未明确说明,但暗示是基于梯度的)。PopSAN 接收高维观测作为输入,将其编码为神经元群体活动,然后通过SNN进行处理,输出控制动作。DRL算法根据环境反馈(奖励)更新 PopSAN 的参数,优化控制策略。整个过程通过 Isaac Gym 平台进行仿真和评估。
关键创新:最关键的创新点在于将 Population coding 引入到 Spiking Actor Network 中,构建了 PopSAN。这种结构能够有效地处理高维输入,并利用 SNN 的节能特性。与传统的基于 ANN 的 Actor 网络相比,PopSAN 在保持控制性能的同时,显著降低了能耗。
关键设计:论文中未详细描述 PopSAN 的具体网络结构和参数设置,但可以推断其包含以下关键设计:1) Population coding 的编码方式,例如如何将观测值映射到神经元的发放率;2) SNN 的神经元模型,例如 Leaky Integrate-and-Fire (LIF) 模型;3) SNN 的连接方式和权重初始化方法;4) 用于策略优化的损失函数和优化算法。这些细节需要在后续研究中进一步明确。
🖼️ 关键图片
📊 实验亮点
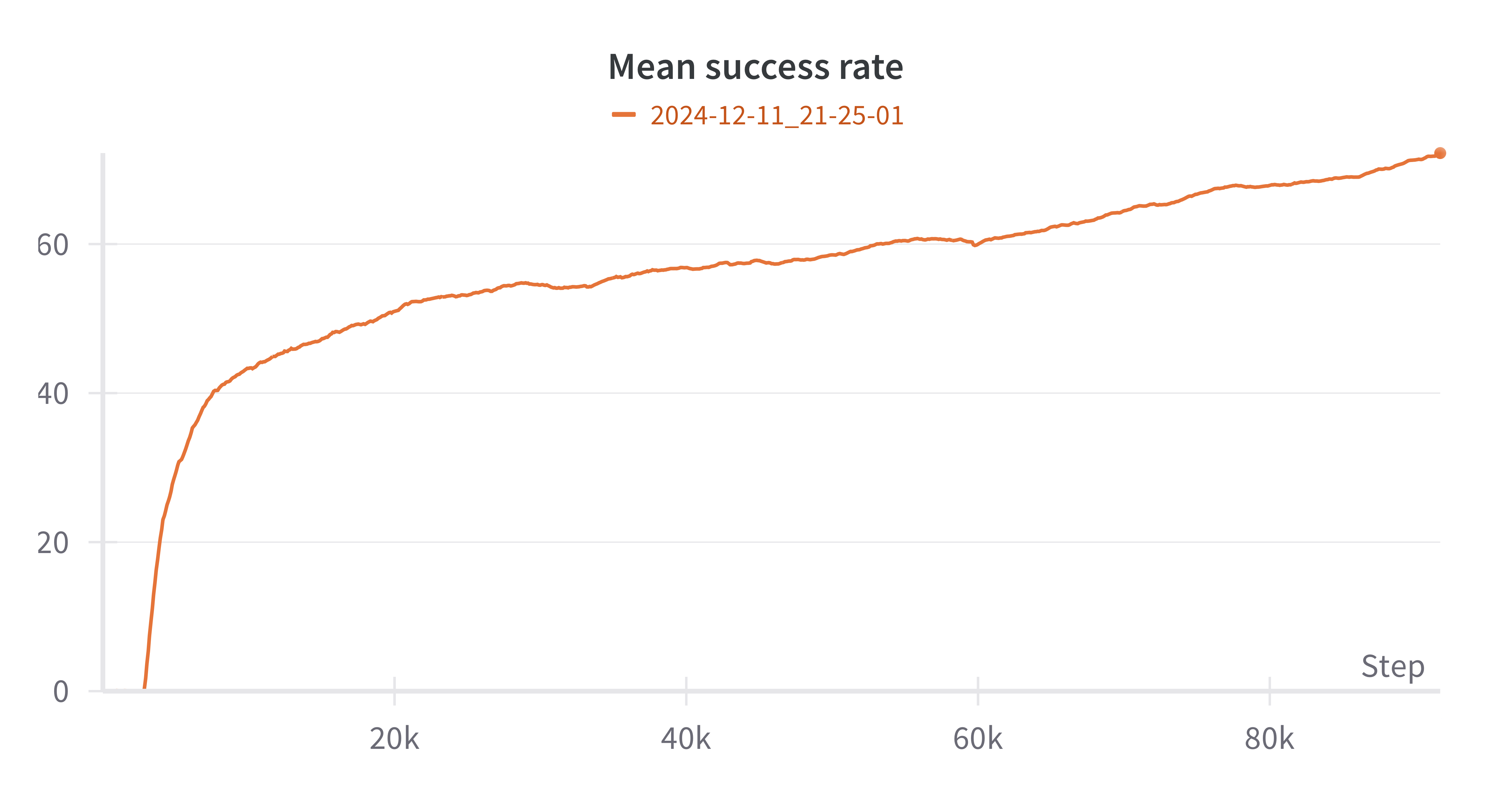
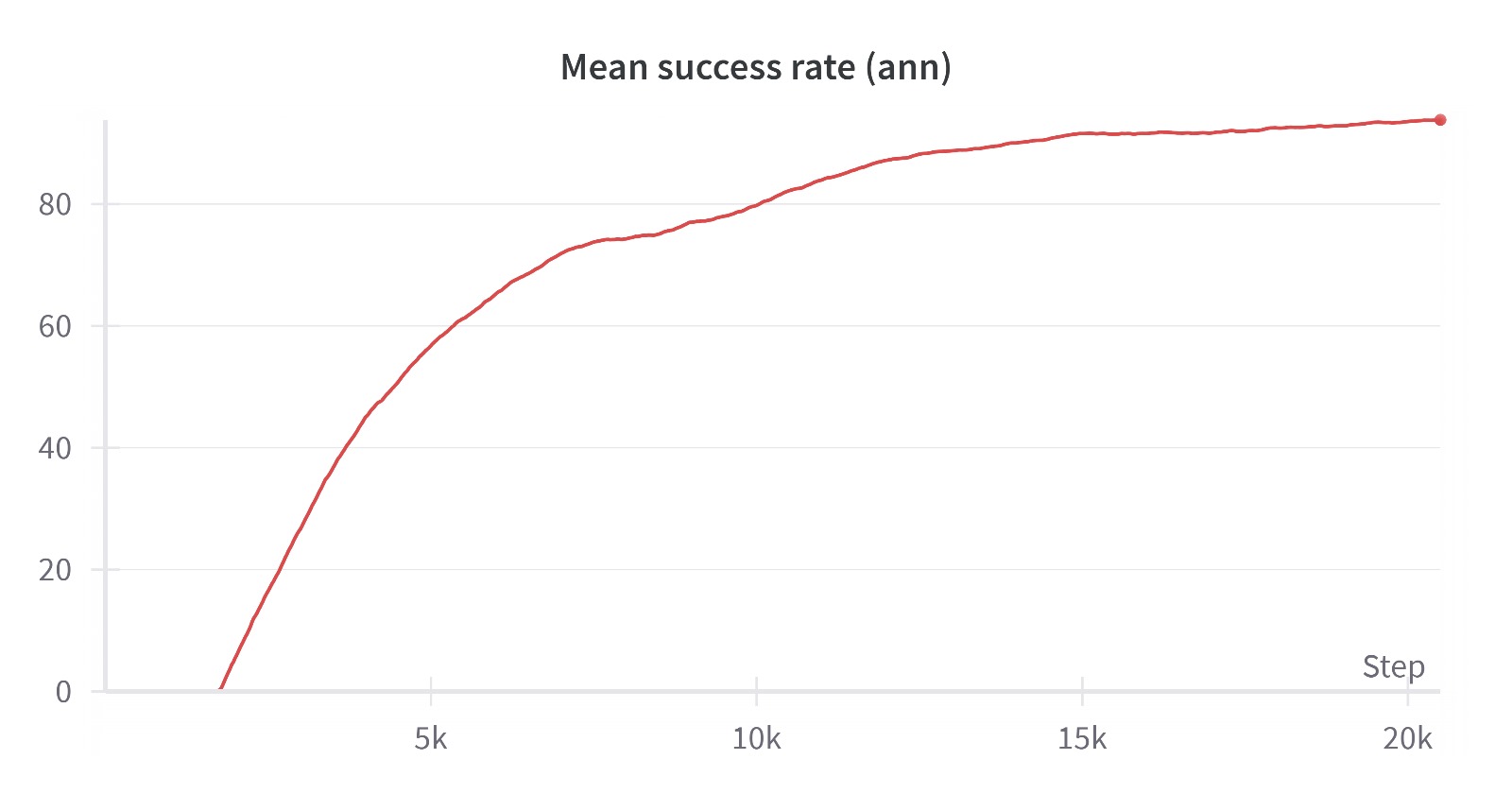
实验结果表明,在Franka机械臂的控制任务中,基于Population-coded SNN的DRL框架相比传统ANN,能耗降低高达96.10%,同时保持了相当的控制性能。该方法在手指位置跟踪和目标高度维持方面表现出鲁棒性,验证了其在高维机器人控制中的有效性和节能潜力。
🎯 应用场景
该研究成果可应用于各种资源受限的机器人应用场景,例如无人机、移动机器人、可穿戴设备和植入式医疗设备。通过降低机器人控制的能耗,可以延长电池续航时间,提高机器人的自主性和可靠性,并降低运行成本。此外,该方法还有潜力应用于其他需要节能计算的领域,例如边缘计算和物联网。
📄 摘要(原文)
Energy-efficient and high-performance motor control remains a critical challenge in robotics, particularly for high-dimensional continuous control tasks with limited onboard resources. While Deep Reinforcement Learning (DRL) has achieved remarkable results, its computational demands and energy consumption limit deployment in resource-constrained environments. This paper introduces a novel framework combining population-coded Spiking Neural Networks (SNNs) with DRL to address these challenges. Our approach leverages the event-driven, asynchronous computation of SNNs alongside the robust policy optimization capabilities of DRL, achieving a balance between energy efficiency and control performance. Central to this framework is the Population-coded Spiking Actor Network (PopSAN), which encodes high-dimensional observations into neuronal population activities and enables optimal policy learning through gradient-based updates. We evaluate our method on the Isaac Gym platform using the PixMC benchmark with complex robotic manipulation tasks. Experimental results on the Franka robotic arm demonstrate that our approach achieves energy savings of up to 96.10% compared to traditional Artificial Neural Networks (ANNs) while maintaining comparable control performance. The trained SNN policies exhibit robust finger position tracking with minimal deviation from commanded trajectories and stable target height maintenance during pick-and-place operations. These results position population-coded SNNs as a promising solution for energy-efficient, high-performance robotic control in resource-constrained applications, paving the way for scalable deployment in real-world robotics systems.