Towards Dynamic Quadrupedal Gaits: A Symmetry-Guided RL Hierarchy Enables Free Gait Transitions at Varying Speeds
作者: Jiayu Ding, Xulin Chen, Garrett E. Katz, Zhenyu Gan
分类: cs.RO, eess.SY
发布日期: 2025-10-12
💡 一句话要点
提出一种对称性引导的强化学习框架,实现四足机器人不同速度下的自由步态转换。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 步态生成 强化学习 对称性 动态运动
📋 核心要点
- 传统四足机器人步态生成依赖专家手动调整大量参数,如触地和离地事件、运动学约束等,过程繁琐且泛化性差。
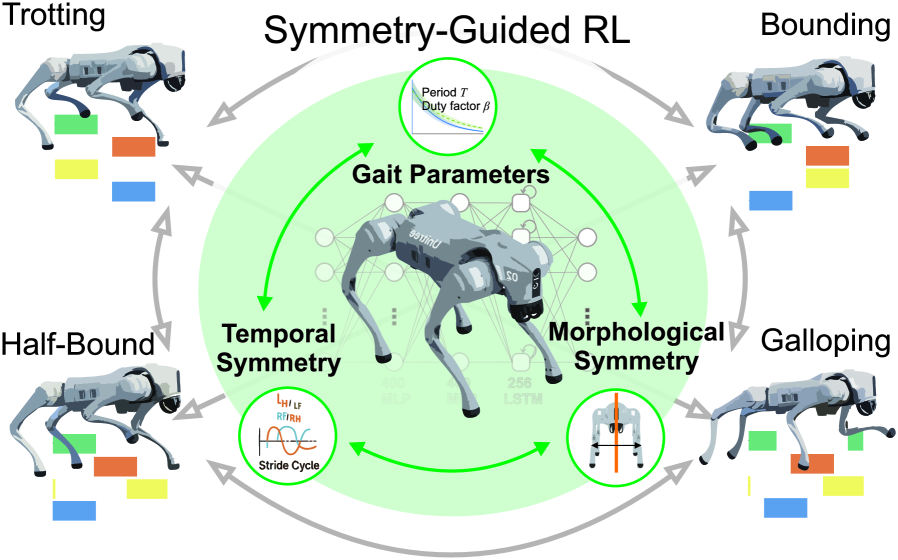
- 论文提出一种对称性引导的强化学习方法,利用时间、形态和时间反转对称性设计奖励函数,无需预定义轨迹,实现多种步态间的平滑过渡。
- 在Unitree Go2机器人上的实验表明,该方法在不同速度下表现出鲁棒性,显著提高了步态适应性,无需大量奖励调整或显式足端控制。
📝 摘要(中文)
本文提出了一种统一的强化学习框架,通过利用动态腿式系统的内在对称性和速度-周期关系,生成通用的四足机器人步态。该方法设计了一种对称性引导的奖励函数,其中融合了时间对称性、形态对称性和时间反转对称性。通过关注保持的对称性和自然动力学,该方法无需预定义的轨迹,从而能够实现诸如小跑、跳跃、半跳跃和疾驰等多种运动模式之间的平滑过渡。在Unitree Go2机器人上的实验表明,该方法在模拟和硬件测试中均表现出强大的性能,显著提高了步态的适应性,而无需进行大量的奖励调整或显式的足端位置控制。这项工作为动态运动策略提供了见解,并强调了对称性在机器人步态设计中的关键作用。
🔬 方法详解
问题定义:现有四足机器人步态生成方法通常需要人工设计复杂的控制策略和轨迹,依赖于大量的专家经验,并且难以在不同速度和地形下实现平滑的步态转换。这些方法通常需要针对每种步态进行单独的调整,缺乏通用性和适应性。因此,如何设计一种能够自动生成多种步态并实现平滑转换的通用框架是一个关键问题。
核心思路:论文的核心思路是利用动态腿式系统的内在对称性来简化步态生成过程。通过在奖励函数中引入时间对称性、形态对称性和时间反转对称性,引导强化学习智能体学习符合自然动力学的步态。这种方法避免了对特定步态的预定义轨迹的依赖,从而能够实现多种步态之间的平滑过渡。
技术框架:该方法采用分层强化学习框架。底层控制器负责执行由高层策略生成的动作,例如关节力矩。高层策略则负责根据当前状态和目标速度,选择合适的动作,并根据对称性引导的奖励函数进行训练。整个框架通过强化学习算法进行端到端训练,无需人工设计复杂的控制规则。
关键创新:该论文的关键创新在于对称性引导的奖励函数设计。通过将时间对称性、形态对称性和时间反转对称性融入奖励函数,引导智能体学习符合自然动力学的步态,从而避免了对特定步态的预定义轨迹的依赖。这种方法不仅简化了步态生成过程,还提高了步态的适应性和泛化能力。
关键设计:奖励函数的设计是该方法的核心。具体来说,奖励函数包括以下几个部分:1) 速度跟踪奖励,鼓励机器人达到目标速度;2) 对称性奖励,鼓励机器人保持时间对称性、形态对称性和时间反转对称性;3) 稳定性奖励,鼓励机器人保持平衡;4) 能量消耗惩罚,鼓励机器人以更节能的方式运动。这些奖励项通过加权求和的方式组合在一起,并通过实验调整权重。
🖼️ 关键图片

📊 实验亮点
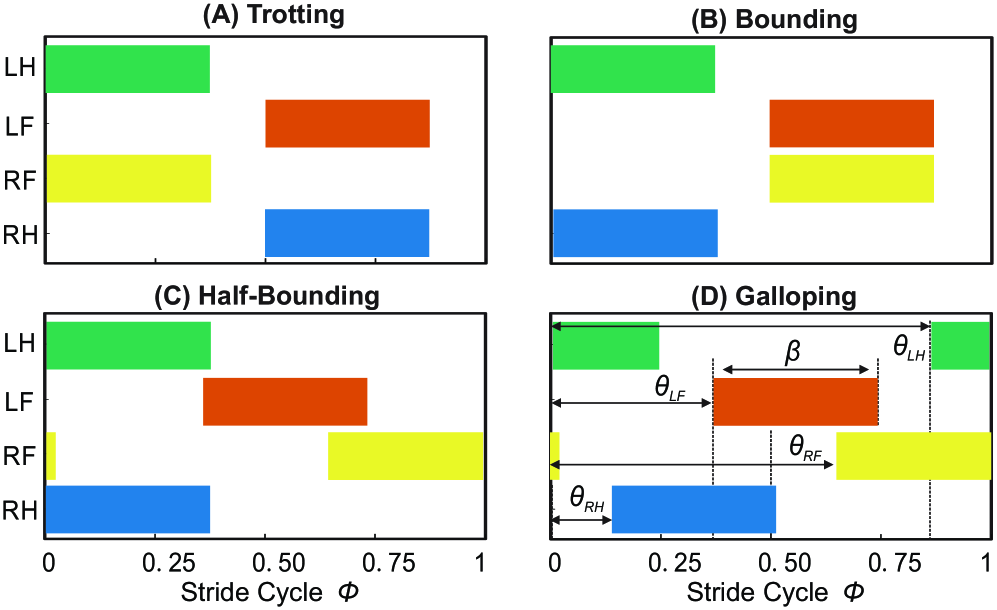
该方法在Unitree Go2机器人上进行了仿真和硬件实验。实验结果表明,该方法能够生成包括小跑、跳跃、半跳跃和疾驰等多种步态,并实现这些步态之间的平滑过渡。与传统的基于轨迹规划的方法相比,该方法无需人工设计复杂的控制规则,显著提高了步态的适应性和泛化能力。在不同速度下的实验表明,该方法具有良好的鲁棒性。
🎯 应用场景
该研究成果可应用于各种四足机器人平台,提升其在复杂环境下的运动能力和适应性。例如,在搜索救援、物流运输、巡检等领域,四足机器人需要具备在不同地形和速度下灵活运动的能力。该方法能够帮助四足机器人自动生成适应不同任务需求的步态,提高其工作效率和可靠性,并降低人工干预的需求。
📄 摘要(原文)
Quadrupedal robots exhibit a wide range of viable gaits, but generating specific footfall sequences often requires laborious expert tuning of numerous variables, such as touch-down and lift-off events and holonomic constraints for each leg. This paper presents a unified reinforcement learning framework for generating versatile quadrupedal gaits by leveraging the intrinsic symmetries and velocity-period relationship of dynamic legged systems. We propose a symmetry-guided reward function design that incorporates temporal, morphological, and time-reversal symmetries. By focusing on preserved symmetries and natural dynamics, our approach eliminates the need for predefined trajectories, enabling smooth transitions between diverse locomotion patterns such as trotting, bounding, half-bounding, and galloping. Implemented on the Unitree Go2 robot, our method demonstrates robust performance across a range of speeds in both simulations and hardware tests, significantly improving gait adaptability without extensive reward tuning or explicit foot placement control. This work provides insights into dynamic locomotion strategies and underscores the crucial role of symmetries in robotic gait design.