Taxonomy and Trends in Reinforcement Learning for Robotics and Control Systems: A Structured Review
作者: Kumater Ter, Ore-Ofe Ajayi, Daniel Udekwe
分类: cs.RO, cs.LG
发布日期: 2025-10-11 (更新: 2025-10-29)
💡 一句话要点
综述强化学习在机器人与控制系统中的应用:分类、趋势与结构化回顾
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 机器人控制 深度强化学习 综述 马尔可夫决策过程
📋 核心要点
- 现有机器人控制方法在动态和不确定环境中表现不足,难以适应复杂任务。
- 论文核心在于综述强化学习在机器人控制中的应用,并进行结构化分类和趋势分析。
- 通过对现有研究的综合分析,论文旨在弥合理论与实践之间的差距,促进RL在机器人领域的应用。
📝 摘要(中文)
强化学习(RL)已成为在动态和不确定环境中实现智能机器人行为的基础方法。本文深入回顾了强化学习原理、先进的深度强化学习(DRL)算法及其在机器人和控制系统中的集成。研究从马尔可夫决策过程(MDP)的形式化定义开始,概述了智能体-环境交互的基本要素,并探讨了包括Actor-Critic方法、基于价值的学习和策略梯度等核心算法策略。重点介绍了现代DRL技术,如DDPG、TD3、PPO和SAC,这些技术已在解决高维、连续控制任务中显示出潜力。引入了一个结构化的分类法,用于对强化学习在运动、操作、多智能体协调和人机交互等领域的应用进行分类,以及训练方法和部署准备程度。综述总结了最近的研究成果,强调了技术趋势、设计模式以及强化学习在现实世界机器人技术中日益成熟。总的来说,这项工作旨在将理论进步与实际应用联系起来,为强化学习在自主机器人系统中不断发展的作用提供一个综合的视角。
🔬 方法详解
问题定义:现有机器人控制方法难以适应动态、不确定的环境,尤其是在高维连续控制任务中。传统方法往往需要精确的模型,泛化能力有限。强化学习旨在通过与环境的交互学习最优策略,但其在机器人领域的应用仍面临诸多挑战,例如样本效率低、探索困难等。
核心思路:本文的核心思路是对强化学习在机器人和控制系统中的应用进行系统性的梳理和分类,总结现有方法的优缺点,并分析未来的发展趋势。通过构建一个结构化的分类体系,帮助研究人员更好地理解和应用强化学习算法。
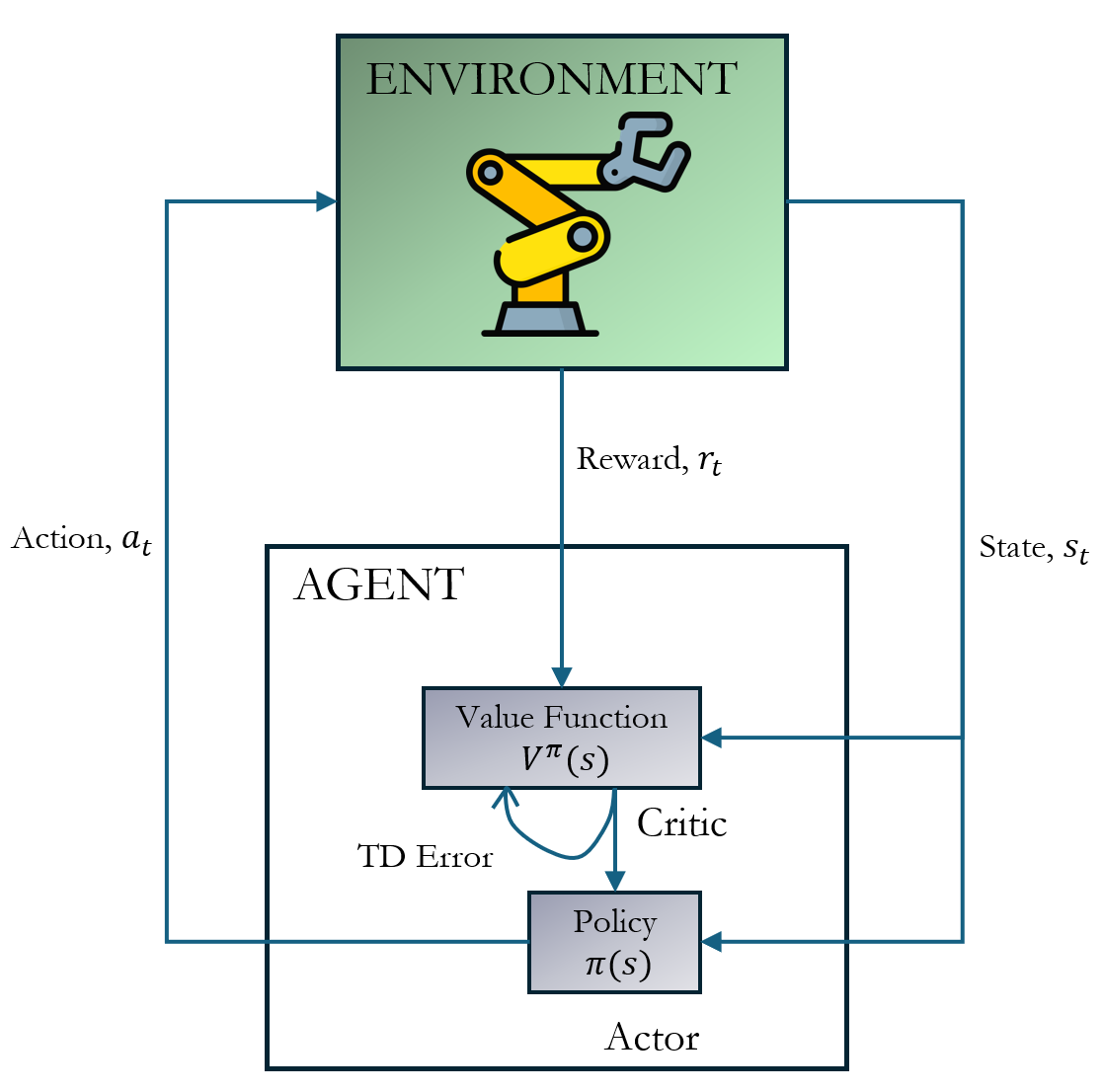
技术框架:该综述首先介绍了马尔可夫决策过程(MDP)的基本概念,然后概述了强化学习的核心算法,包括基于价值的学习、策略梯度方法和Actor-Critic方法。重点介绍了深度强化学习(DRL)算法,如DDPG、TD3、PPO和SAC。最后,对强化学习在机器人领域的应用进行了分类,包括运动、操作、多智能体协调和人机交互等。
关键创新:该综述的关键创新在于提出了一个结构化的分类体系,用于对强化学习在机器人领域的应用进行分类。该分类体系考虑了不同的应用领域、训练方法和部署准备程度,有助于研究人员更好地理解和比较不同的方法。
关键设计:该综述没有提出新的算法或模型,而是对现有研究进行了整理和分析。在分类体系的设计上,考虑了不同应用场景的特点,并对各种方法的优缺点进行了总结。此外,还对未来的发展趋势进行了展望,为研究人员提供了有价值的参考。
🖼️ 关键图片

📊 实验亮点
该综述总结了近年来强化学习在机器人控制领域的重要进展,并对各种方法的性能进行了比较。特别强调了深度强化学习算法在解决高维连续控制任务中的潜力,并对未来的发展趋势进行了展望。该综述为研究人员提供了一个全面的视角,有助于他们更好地理解和应用强化学习技术。
🎯 应用场景
该研究对机器人、自动化和控制工程领域具有广泛的应用价值。通过对现有强化学习方法进行系统性的回顾和分类,可以帮助研究人员更好地选择和应用合适的算法,从而提高机器人系统的性能和鲁棒性。此外,该研究还可以促进强化学习在实际机器人系统中的部署,加速机器人技术的商业化进程。
📄 摘要(原文)
Reinforcement learning (RL) has become a foundational approach for enabling intelligent robotic behavior in dynamic and uncertain environments. This work presents an in-depth review of RL principles, advanced deep reinforcement learning (DRL) algorithms, and their integration into robotic and control systems. Beginning with the formalism of Markov Decision Processes (MDPs), the study outlines essential elements of the agent-environment interaction and explores core algorithmic strategies including actor-critic methods, value-based learning, and policy gradients. Emphasis is placed on modern DRL techniques such as DDPG, TD3, PPO, and SAC, which have shown promise in solving high-dimensional, continuous control tasks. A structured taxonomy is introduced to categorize RL applications across domains such as locomotion, manipulation, multi-agent coordination, and human-robot interaction, along with training methodologies and deployment readiness levels. The review synthesizes recent research efforts, highlighting technical trends, design patterns, and the growing maturity of RL in real-world robotics. Overall, this work aims to bridge theoretical advances with practical implementations, providing a consolidated perspective on the evolving role of RL in autonomous robotic systems.