X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
作者: Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, Ya-Qin Zhang, Jiangmiao Pang, Jingjing Liu, Tai Wang, Xianyuan Zhan
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-10-11
备注: preprint, technical report, 33 pages
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
X-VLA:基于软提示Transformer的可扩展跨具身视觉-语言-动作模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 跨具身学习 软提示学习 Transformer 机器人控制
📋 核心要点
- 现有VLA模型难以有效利用跨具身机器人数据的异构性,阻碍了通用机器人学习的发展。
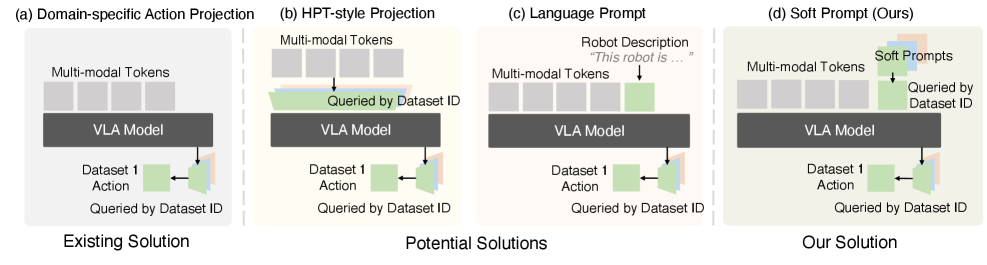
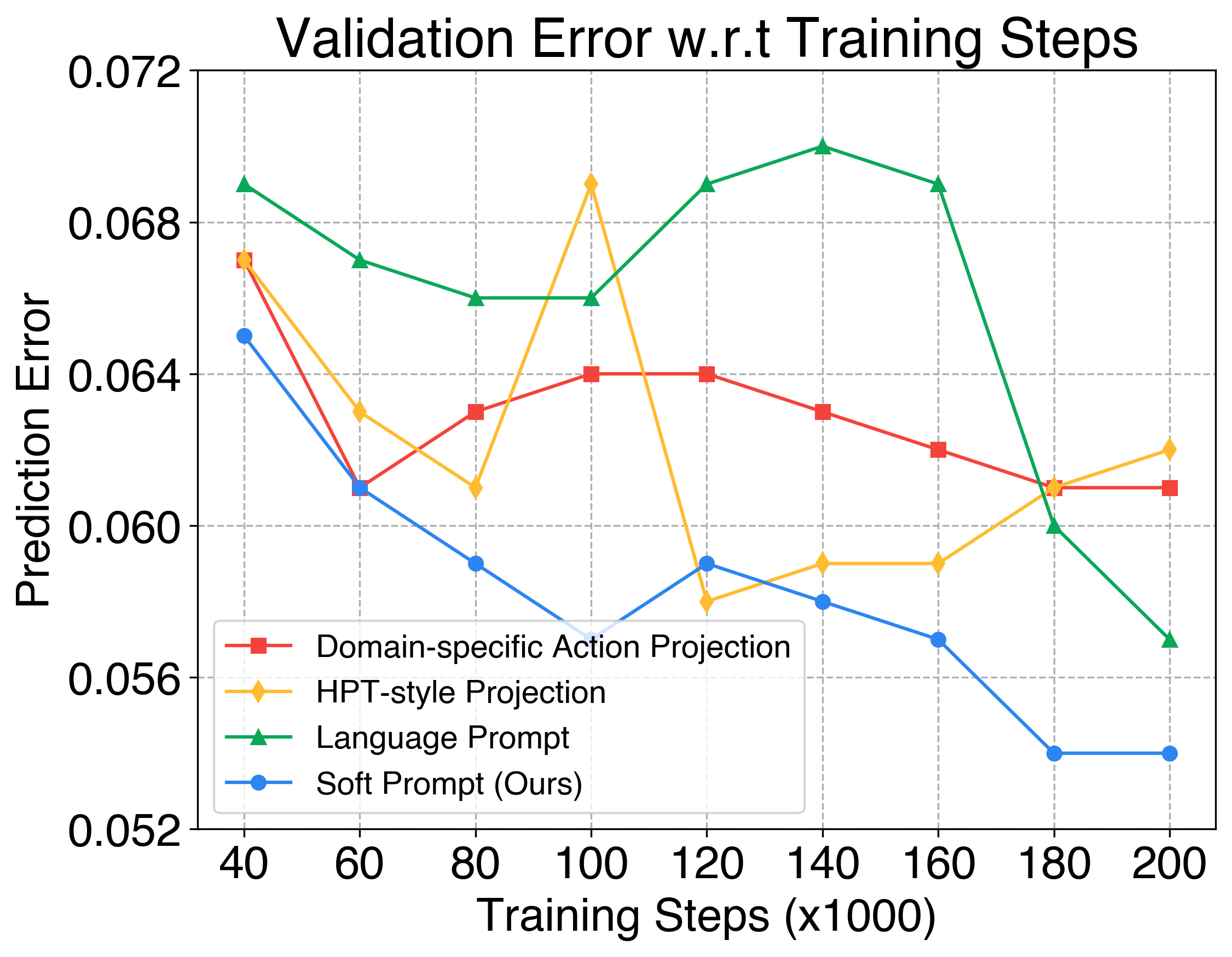
- 论文提出软提示方法,为每个数据源引入可学习嵌入,作为具身特定提示,提升模型对异构数据的利用。
- X-VLA在多个模拟和真实机器人任务中取得SOTA性能,验证了其在灵活性和快速适应性方面的优势。
📝 摘要(中文)
通用的视觉-语言-动作(VLA)模型依赖于跨多种机器人平台的大规模、跨具身、异构数据集上的有效训练。为了促进和利用丰富多样的机器人数据源中的异构性,我们提出了一种新的软提示方法,通过将提示学习的概念注入跨具身机器人学习中,并为每个不同的数据源引入单独的可学习嵌入集,从而以最小的参数添加来实现。这些嵌入作为特定于具身的提示,共同赋予VLA模型有效利用不同跨具身特征的能力。我们新的X-VLA,一个简洁的基于流匹配的VLA架构,完全依赖于软提示的标准Transformer编码器,兼具可扩展性和简单性。在6个模拟环境和3个真实世界机器人上的评估表明,我们的0.9B实例化-X-VLA-0.9B同时在多个基准测试中实现了SOTA性能,在灵活的灵巧性到跨具身、环境和任务的快速适应等广泛的能力轴上展示了卓越的结果。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在处理来自不同机器人平台和环境的异构数据时面临挑战。直接混合这些数据会导致模型性能下降,因为不同具身的数据分布存在差异。现有方法要么忽略这种差异,要么需要复杂的领域适应技术,增加了训练的复杂性。
核心思路:论文的核心思路是利用软提示学习,为每个具身(embodiment)的数据引入一个可学习的提示向量。这些提示向量能够捕捉特定具身的数据特征,从而帮助模型更好地理解和利用异构数据。通过这种方式,模型可以在统一的框架下处理来自不同具身的数据,而无需进行复杂的领域适应。
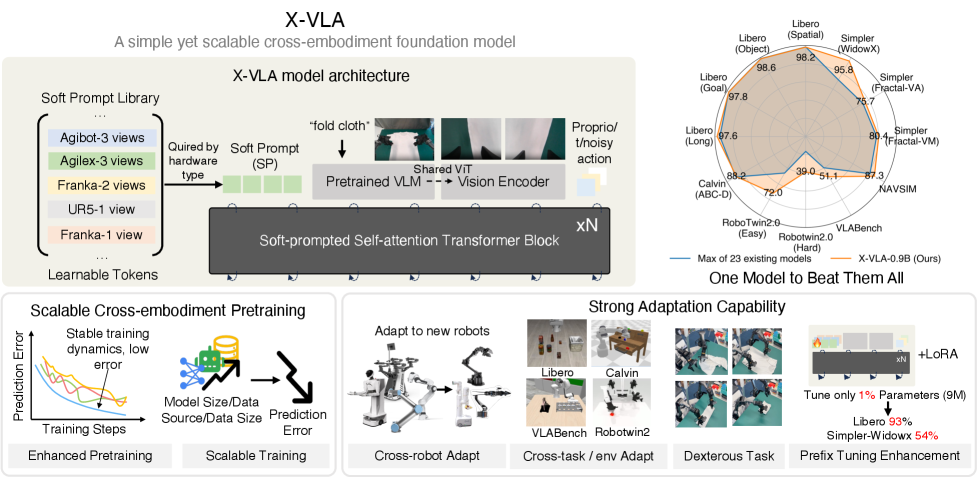
技术框架:X-VLA架构基于Transformer编码器,并引入了软提示模块。整体流程如下:首先,对输入图像和文本进行编码,得到视觉和语言特征。然后,将这些特征与对应具身的软提示向量拼接,作为Transformer编码器的输入。编码器输出融合后的特征,用于预测动作。X-VLA采用基于流匹配的训练方法,旨在提高模型的稳定性和泛化能力。
关键创新:关键创新在于软提示模块的设计。与传统的硬提示不同,软提示是可学习的嵌入向量,可以根据数据进行调整。这种设计使得模型能够更好地捕捉特定具身的数据特征,从而提高性能。此外,X-VLA架构简洁,仅依赖于标准的Transformer编码器,易于扩展和部署。
关键设计:每个具身对应一个独立的软提示向量,这些向量在训练过程中进行学习。论文采用了基于流匹配的损失函数,旨在提高模型的训练稳定性和泛化能力。Transformer编码器的层数和隐藏层维度等超参数根据模型大小进行调整。具体而言,X-VLA-0.9B模型包含多层Transformer编码器,并使用AdamW优化器进行训练。
🖼️ 关键图片
📊 实验亮点
X-VLA-0.9B在6个模拟环境和3个真实世界机器人上的实验结果表明,其在多个基准测试中取得了SOTA性能。例如,在Dexterity任务中,X-VLA的成功率显著高于现有方法。此外,X-VLA还展现了良好的跨具身适应能力,能够在不同机器人平台上快速适应新任务。
🎯 应用场景
该研究成果可应用于通用机器人控制、机器人辅助、自动化生产等领域。通过学习不同机器人的数据,X-VLA能够实现跨平台、跨任务的机器人控制,降低机器人部署和维护成本。未来,该技术有望推动机器人智能化发展,使其更好地服务于人类社会。
📄 摘要(原文)
Successful generalist Vision-Language-Action (VLA) models rely on effective training across diverse robotic platforms with large-scale, cross-embodiment, heterogeneous datasets. To facilitate and leverage the heterogeneity in rich, diverse robotic data sources, we propose a novel Soft Prompt approach with minimally added parameters, by infusing prompt learning concepts into cross-embodiment robot learning and introducing separate sets of learnable embeddings for each distinct data source. These embeddings serve as embodiment-specific prompts, which in unity empower VLA models with effective exploitation of varying cross-embodiment features. Our new X-VLA, a neat flow-matching-based VLA architecture, relies exclusively on soft-prompted standard Transformer encoders, enjoying both scalability and simplicity. Evaluated across 6 simulations as well as 3 real-world robots, our 0.9B instantiation-X-VLA-0.9B simultaneously achieves SOTA performance over a sweep of benchmarks, demonstrating superior results on a wide axes of capabilities, from flexible dexterity to quick adaptation across embodiments, environments, and tasks. Website: https://thu-air-dream.github.io/X-VLA/