Ctrl-World: A Controllable Generative World Model for Robot Manipulation
作者: Yanjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, Chelsea Finn
分类: cs.RO, cs.AI
发布日期: 2025-10-11 (更新: 2025-10-15)
备注: 17 pages
💡 一句话要点
提出Ctrl-World,用于机器人操作的可控生成世界模型,提升策略学习。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 世界模型 机器人操作 策略学习 多视角预测 长时程一致性
📋 核心要点
- 现有通用机器人策略评估和改进困难,真实世界实验成本高昂,专家标注数据难以获取。
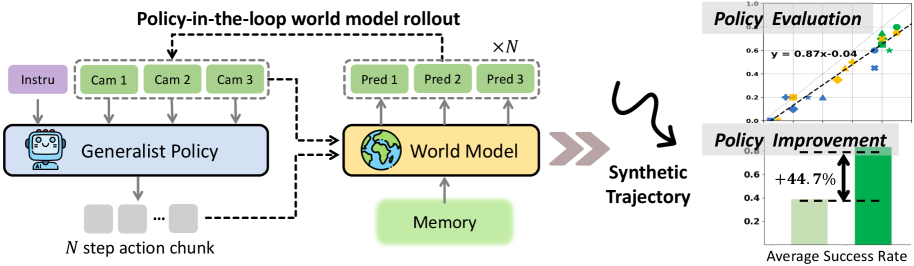
- 提出Ctrl-World,一个可控的多视角世界模型,通过姿态条件记忆检索和帧级动作条件化,实现长时程一致性和精确动作控制。
- 实验表明,该模型能准确评估策略性能,并通过合成轨迹微调,显著提升策略成功率达44.7%。
📝 摘要(中文)
通用机器人策略现在可以执行各种操作技能,但评估和改进它们处理不熟悉物体和指令的能力仍然是一个重大挑战。严格的评估需要大量的真实世界实验,而系统的改进需要额外的专家标注数据。这两个过程都缓慢、昂贵且难以扩展。世界模型提供了一种有前景且可扩展的替代方案,使策略能够在想象空间中展开。然而,一个关键挑战是构建一个可控的世界模型,该模型可以处理与通用机器人策略的多步交互。这需要一个与现代通用策略兼容的世界模型,支持多视角预测、精细的动作控制和一致的长时程交互,而先前的工作未能实现这一点。在本文中,我们向前迈进了一步,引入了一个可控的多视角世界模型,可用于评估和提高通用机器人策略的指令跟随能力。我们的模型通过姿态条件记忆检索机制保持长时程一致性,并通过帧级动作条件化实现精确的动作控制。在DROID数据集(9.5万条轨迹,564个场景)上训练后,我们的模型可以在新的场景和新的相机位置下生成超过20秒的空间和时间上一致的轨迹。我们表明,我们的方法可以在没有真实世界机器人实验的情况下准确地对策略性能进行排序。此外,通过在想象中合成成功的轨迹并将其用于监督微调,我们的方法可以将策略成功率提高44.7%。
🔬 方法详解
问题定义:现有通用机器人策略的评估和改进依赖于大量的真实世界实验和专家标注数据,成本高昂且难以扩展。构建能够处理多步交互、支持多视角预测、精细动作控制和长时程一致性的可控世界模型是一个关键挑战。
核心思路:论文的核心思路是构建一个可控的生成世界模型,该模型能够模拟机器人在不同场景下的行为,并根据指令生成相应的轨迹。通过在想象空间中进行策略评估和改进,可以避免真实世界实验的成本和风险。
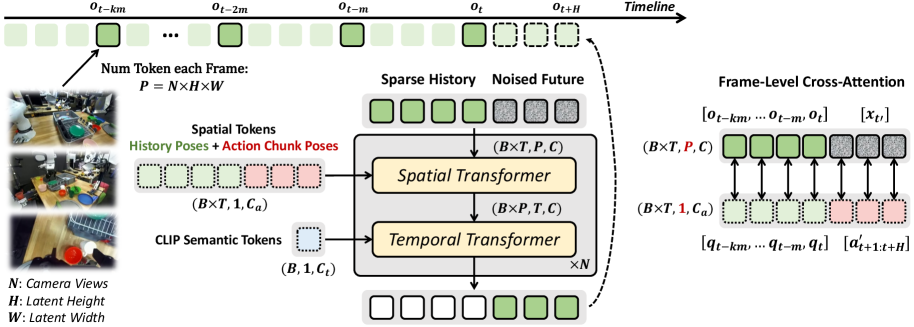
技术框架:Ctrl-World模型主要包含以下几个模块:1) 多视角图像编码器,用于提取场景的视觉特征;2) 姿态条件记忆检索模块,用于保持长时程一致性;3) 帧级动作条件化模块,用于实现精确的动作控制;4) 世界模型解码器,用于生成下一帧的图像。整体流程是:给定当前状态(多视角图像和机器人姿态)和动作指令,模型预测下一帧的图像,并更新记忆。
关键创新:该论文的关键创新在于提出了姿态条件记忆检索机制和帧级动作条件化方法。姿态条件记忆检索机制通过检索与当前姿态相似的历史状态,来保持长时程一致性。帧级动作条件化方法通过在每一帧都对动作进行条件化,来实现精确的动作控制。
关键设计:模型使用Transformer架构进行记忆检索和图像生成。损失函数包括图像重建损失、姿态预测损失和动作预测损失。训练数据来自DROID数据集,包含9.5万条轨迹和564个场景。模型使用Adam优化器进行训练,学习率设置为1e-4。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Ctrl-World模型可以在新的场景和相机位置下生成超过20秒的空间和时间上一致的轨迹。该模型能够准确地对策略性能进行排序,无需真实世界的机器人实验。通过在想象中合成成功的轨迹并将其用于监督微调,策略成功率提高了44.7%。
🎯 应用场景
该研究成果可应用于机器人操作的策略学习、强化学习和仿真环境构建等领域。通过在虚拟环境中训练和评估机器人策略,可以降低开发成本和风险,加速机器人技术的应用。此外,该模型还可以用于生成机器人操作的演示数据,辅助人类进行任务规划和控制。
📄 摘要(原文)
Generalist robot policies can now perform a wide range of manipulation skills, but evaluating and improving their ability with unfamiliar objects and instructions remains a significant challenge. Rigorous evaluation requires a large number of real-world rollouts, while systematic improvement demands additional corrective data with expert labels. Both of these processes are slow, costly, and difficult to scale. World models offer a promising, scalable alternative by enabling policies to rollout within imagination space. However, a key challenge is building a controllable world model that can handle multi-step interactions with generalist robot policies. This requires a world model compatible with modern generalist policies by supporting multi-view prediction, fine-grained action control, and consistent long-horizon interactions, which is not achieved by previous works. In this paper, we make a step forward by introducing a controllable multi-view world model that can be used to evaluate and improve the instruction-following ability of generalist robot policies. Our model maintains long-horizon consistency with a pose-conditioned memory retrieval mechanism and achieves precise action control through frame-level action conditioning. Trained on the DROID dataset (95k trajectories, 564 scenes), our model generates spatially and temporally consistent trajectories under novel scenarios and new camera placements for over 20 seconds. We show that our method can accurately rank policy performance without real-world robot rollouts. Moreover, by synthesizing successful trajectories in imagination and using them for supervised fine-tuning, our approach can improve policy success by 44.7\%.