ATRos: Learning Energy-Efficient Agile Locomotion for Wheeled-legged Robots
作者: Jingyuan Sun, Hongyu Ji, Zihan Qu, Chaoran Wang, Mingyu Zhang
分类: cs.RO
发布日期: 2025-10-11
备注: 4 pages, 2 figures, submitted to IROS 2025 wheeled-legged workshop
💡 一句话要点
ATRos:一种基于强化学习的轮腿机器人高效敏捷混合运动控制框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 轮腿机器人 混合运动 强化学习 机器人控制 地形适应性
📋 核心要点
- 轮腿机器人的混合运动结合了腿式运动的敏捷性和轮式运动的效率,但其全身控制极具挑战。
- ATRos利用强化学习,无需预定义步态,智能协调轮和腿的运动,提升地形适应性和能效。
- 仿真和真实环境实验验证了ATRos在多种地形下的可行性和泛化能力,展现了其鲁棒性。
📝 摘要(中文)
本文提出ATRos,一个基于强化学习(RL)的混合运动框架,旨在实现轮腿机器人的混合行走-驱动运动。该框架不依赖预定义的步态模式,而是智能地协调车轮和腿部的同步运动,从而提高地形适应性和能量效率。该方法基于强化学习技术,构建了一个预测策略网络,该网络可以从本体感受感官信息中估计外部环境状态,然后将输出馈送到Actor-Critic网络以生成最佳关节命令。通过仿真和真实世界的实验,在包括平地、楼梯和草地在内的各种地形上验证了所提出框架的可行性。混合运动框架在各种未见过的地形上表现出强大的性能,突出了其泛化能力。
🔬 方法详解
问题定义:轮腿机器人的混合运动控制旨在结合轮式和腿式运动的优点,但现有方法通常依赖于预定义的步态模式,难以适应复杂地形,且能量效率不高。因此,需要一种能够智能协调轮腿运动,提高地形适应性和能量效率的控制方法。
核心思路:ATRos的核心思路是利用强化学习,让机器人自主学习最优的混合运动策略,无需人工设计步态。通过奖励函数引导机器人学习在不同地形下如何协调轮和腿的运动,从而实现高效、敏捷的运动。
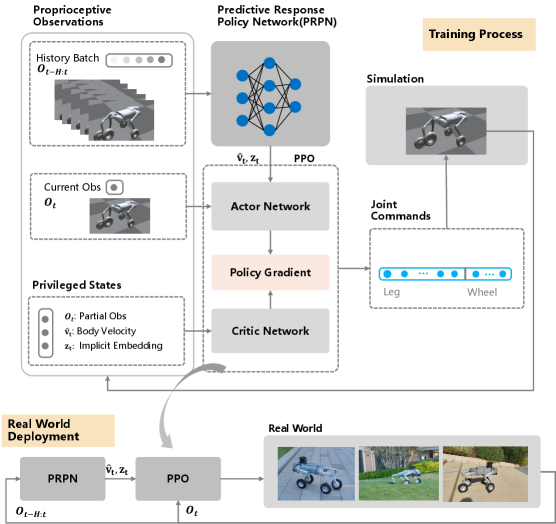
技术框架:ATRos框架包含两个主要模块:预测策略网络和Actor-Critic网络。预测策略网络接收来自机器人的本体感受信息,估计外部环境状态。Actor-Critic网络则根据环境状态,输出最优的关节命令,控制机器人的运动。整个框架通过强化学习进行训练,不断优化策略,提高运动性能。
关键创新:ATRos的关键创新在于使用强化学习来学习混合运动策略,避免了人工设计步态的复杂性。此外,通过预测策略网络估计环境状态,使机器人能够更好地适应未知地形。这种端到端的学习方法能够充分利用轮腿机器人的运动潜力,实现更高效、更灵活的运动。
关键设计:预测策略网络和Actor-Critic网络均采用深度神经网络结构。奖励函数的设计至关重要,需要综合考虑运动速度、能量消耗、稳定性等因素。训练过程中,使用合适的探索策略,鼓励机器人尝试不同的运动方式,从而找到最优策略。具体的网络结构和参数设置在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
ATRos在仿真和真实环境实验中均表现出良好的性能。在各种未见过的地形上,ATRos能够实现稳定、高效的混合运动。与传统的基于预定义步态的方法相比,ATRos在地形适应性和能量效率方面均有显著提升(具体数据未知)。实验结果表明,ATRos具有很强的泛化能力和鲁棒性。
🎯 应用场景
ATRos框架可应用于各种轮腿机器人,使其能够在复杂地形下执行任务,例如搜索救援、物流运输、巡检维护等。该研究成果有助于提升机器人的自主性和适应性,使其在更多实际场景中发挥作用,具有重要的应用价值和潜力。
📄 摘要(原文)
Hybrid locomotion of wheeled-legged robots has recently attracted increasing attention due to their advantages of combining the agility of legged locomotion and the efficiency of wheeled motion. But along with expanded performance, the whole-body control of wheeled-legged robots remains challenging for hybrid locomotion. In this paper, we present ATRos, a reinforcement learning (RL)-based hybrid locomotion framework to achieve hybrid walking-driving motions on the wheeled-legged robot. Without giving predefined gait patterns, our planner aims to intelligently coordinate simultaneous wheel and leg movements, thereby achieving improved terrain adaptability and improved energy efficiency. Based on RL techniques, our approach constructs a prediction policy network that could estimate external environmental states from proprioceptive sensory information, and the outputs are then fed into an actor critic network to produce optimal joint commands. The feasibility of the proposed framework is validated through both simulations and real-world experiments across diverse terrains, including flat ground, stairs, and grassy surfaces. The hybrid locomotion framework shows robust performance over various unseen terrains, highlighting its generalization capability.