Obstacle Avoidance using Dynamic Movement Primitives and Reinforcement Learning
作者: Dominik Urbaniak, Alejandro Agostini, Pol Ramon, Jan Rosell, Raúl Suárez, Michael Suppa
分类: cs.RO, cs.AI
发布日期: 2025-10-10
备注: 8 pages, 7 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于DMP和强化学习的障碍物避障方法,仅需单次演示即可快速生成近优轨迹。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人运动规划 障碍物避障 动态运动原语 强化学习 神经网络 轨迹优化 自主导航
📋 核心要点
- 现有基于学习的运动规划方法依赖大量训练数据或人工示教,成本高昂且效率较低。
- 该方法利用动态运动原语(DMP)编码单次示教轨迹,并结合强化学习迭代优化,生成多样化轨迹数据。
- 实验结果表明,该方法在计算效率、轨迹质量和对不同障碍物形状的适应性方面均优于传统方法。
📝 摘要(中文)
本文提出了一种基于学习的运动规划方法,能够快速生成近优轨迹。与传统方法需要大量训练数据或昂贵的人工示教不同,该方法仅需单次人工示教即可生成平滑、近优且无碰撞的3D笛卡尔轨迹。该示教被编码为动态运动原语(DMP),并使用基于策略的强化学习进行迭代重塑,从而为不同的障碍物配置创建多样化的轨迹数据集。该数据集用于训练一个神经网络,该网络以描述障碍物尺寸和位置的任务参数(从点云自动导出)作为输入,并输出生成轨迹的DMP参数。在仿真和真实机器人实验中验证了该方法的有效性,在计算和执行时间以及轨迹长度方面均优于RRT-Connect基线,同时支持针对不同障碍物几何形状和末端执行器尺寸的多模态轨迹生成。代码和视频可在GitHub上获取。
🔬 方法详解
问题定义:论文旨在解决机器人运动规划中的障碍物避障问题。现有方法,如RRT-Connect,计算成本高,难以实时生成最优轨迹。而基于学习的方法通常需要大量的训练数据或人工示教,这在实际应用中是昂贵且耗时的。
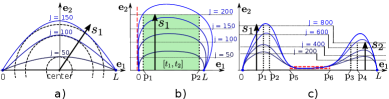
核心思路:论文的核心思路是结合动态运动原语(DMP)和强化学习,利用DMP对轨迹进行参数化表示,并通过强化学习优化DMP的参数,从而生成避开障碍物的最优轨迹。DMP能够保证轨迹的平滑性,而强化学习能够有效地探索不同的轨迹,并找到最优的避障方案。
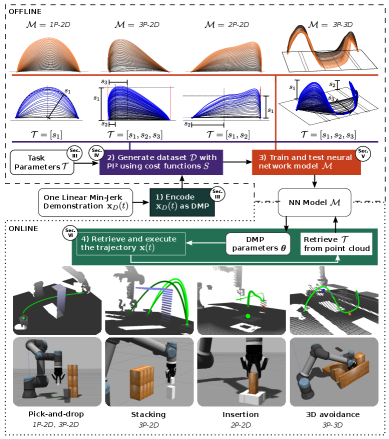
技术框架:整体框架包含以下几个主要模块:1) DMP编码:将单次人工示教轨迹编码为DMP。2) 强化学习优化:使用强化学习算法(PI2)迭代优化DMP的参数,生成多样化的轨迹数据集。3) 神经网络训练:使用生成的轨迹数据集训练一个神经网络,该网络以障碍物信息作为输入,输出DMP参数。4) 轨迹生成:使用训练好的神经网络,根据障碍物信息生成避障轨迹。
关键创新:该方法最重要的创新点在于,它只需要单次人工示教即可生成高质量的避障轨迹,避免了传统方法对大量训练数据的依赖。此外,通过结合DMP和强化学习,能够有效地探索不同的轨迹,并找到最优的避障方案。神经网络的引入使得该方法能够快速适应不同的障碍物配置。
关键设计:DMP使用高斯核函数进行基函数表示,强化学习算法采用PI2,神经网络采用多层感知机结构。损失函数包括轨迹长度、与障碍物的距离以及与目标点的距离等。障碍物信息从点云中提取,包括障碍物的位置、尺寸等参数。
🖼️ 关键图片
📊 实验亮点
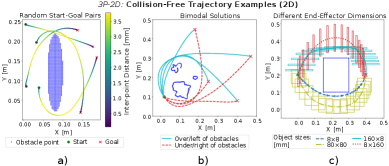
实验结果表明,该方法在仿真和真实机器人实验中均优于RRT-Connect基线。在计算和执行时间方面,该方法显著优于RRT-Connect。此外,该方法生成的轨迹长度也更短,表明其能够生成更优的轨迹。该方法还支持针对不同障碍物几何形状和末端执行器尺寸的多模态轨迹生成,具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于各种需要机器人进行自主导航和避障的场景,例如:工业自动化、物流仓储、家庭服务机器人、无人驾驶等。通过快速生成安全、高效的避障轨迹,可以提高机器人的工作效率和安全性,降低人工干预的需求,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Learning-based motion planning can quickly generate near-optimal trajectories. However, it often requires either large training datasets or costly collection of human demonstrations. This work proposes an alternative approach that quickly generates smooth, near-optimal collision-free 3D Cartesian trajectories from a single artificial demonstration. The demonstration is encoded as a Dynamic Movement Primitive (DMP) and iteratively reshaped using policy-based reinforcement learning to create a diverse trajectory dataset for varying obstacle configurations. This dataset is used to train a neural network that takes as inputs the task parameters describing the obstacle dimensions and location, derived automatically from a point cloud, and outputs the DMP parameters that generate the trajectory. The approach is validated in simulation and real-robot experiments, outperforming a RRT-Connect baseline in terms of computation and execution time, as well as trajectory length, while supporting multi-modal trajectory generation for different obstacle geometries and end-effector dimensions. Videos and the implementation code are available at https://github.com/DominikUrbaniak/obst-avoid-dmp-pi2.