When a Robot is More Capable than a Human: Learning from Constrained Demonstrators
作者: Xinhu Li, Ayush Jain, Zhaojing Yang, Yigit Korkmaz, Erdem Bıyık
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-10
💡 一句话要点
从受限示教者学习:机器人超越人类示教策略的学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 机器人学习 受限示教 奖励函数学习 时间插值 强化学习 机器人控制
📋 核心要点
- 现有模仿学习方法受限于专家示教质量,专家由于控制方式或硬件限制,无法展示最优策略。
- 该论文提出一种新方法,允许机器人超越专家示教,通过探索更优轨迹来学习更好的策略。
- 实验表明,该方法在样本效率和任务完成时间上优于传统模仿学习,并在真实机器人上验证了有效性。
📝 摘要(中文)
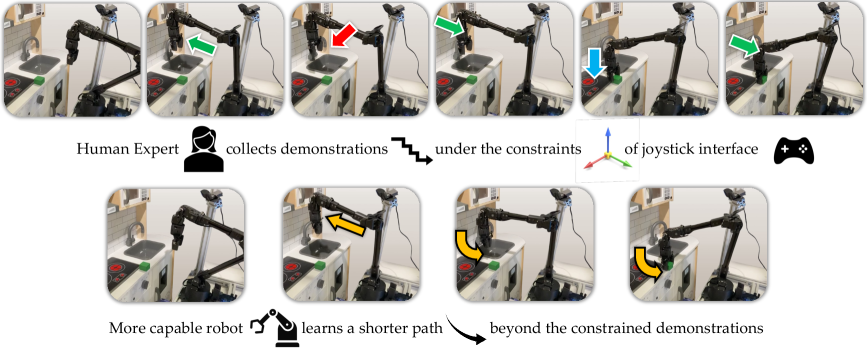
模仿学习使得专家可以通过动觉示教、操纵杆控制和sim-to-real迁移等方式教导机器人执行复杂任务。然而,这些交互方式常常限制了专家展示最优行为的能力,因为间接控制、设置限制和硬件安全等因素。例如,操纵杆可能只能在2D平面内移动机械臂,即使机器人可以在更高维空间中操作。因此,受限专家收集的演示会导致学习策略的次优性能。这引出一个关键问题:机器人能否学习到比受限专家演示的更好的策略?我们通过允许智能体超越直接模仿专家行为,探索更短、更有效的轨迹来解决这个问题。我们使用演示来推断衡量任务进度的状态奖励信号,并使用时间插值自标记未知状态的奖励。我们的方法在样本效率和任务完成时间方面都优于常见的模仿学习方法。在真实的WidowX机械臂上,它在12秒内完成任务,比行为克隆快10倍,相关视频可在https://sites.google.com/view/constrainedexpert 上观看。
🔬 方法详解
问题定义:论文旨在解决模仿学习中,由于专家示教受到约束(例如使用操纵杆控制机械臂),导致机器人学习到的策略次优的问题。现有方法的痛点在于,机器人过度依赖专家提供的次优轨迹,无法自主探索更优的解决方案。
核心思路:论文的核心思路是让机器人不仅仅模仿专家的动作,而是通过学习一个奖励函数来评估状态的好坏,并鼓励机器人探索更短、更有效的轨迹。这样,即使专家的示教是次优的,机器人也能通过自主探索找到更优的策略。
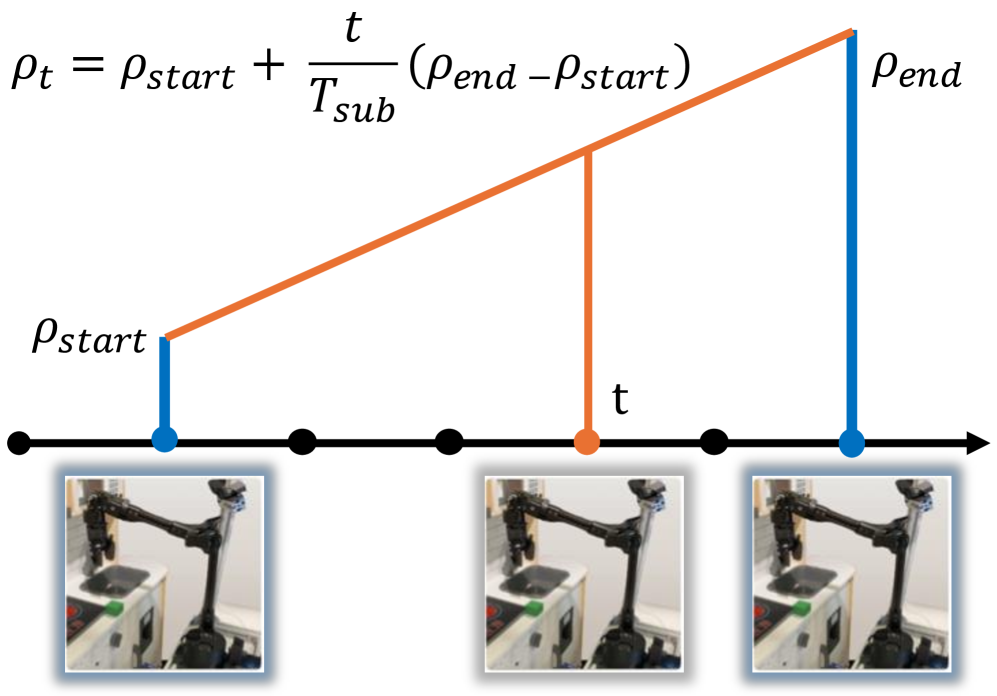
技术框架:整体框架包含以下几个主要步骤:1) 从受限专家的示教数据中学习一个状态奖励函数,该函数用于衡量任务的进展程度。2) 对于未知的状态,使用时间插值的方法来估计其奖励值,从而扩展奖励函数的覆盖范围。3) 使用学习到的奖励函数来训练机器人的策略,鼓励机器人探索更优的轨迹。
关键创新:最重要的技术创新点在于,它打破了传统模仿学习中对专家示教的过度依赖,允许机器人通过自主探索来超越专家。通过学习奖励函数和使用时间插值,机器人可以有效地评估状态的好坏,并找到更优的策略。
关键设计:论文的关键设计包括:1) 使用状态信息来学习奖励函数,而不是直接模仿专家的动作。2) 使用时间插值来估计未知状态的奖励值,从而提高奖励函数的泛化能力。3) 具体的奖励函数形式和训练算法(例如强化学习算法)的选择,以及超参数的调整。
🖼️ 关键图片

📊 实验亮点
该论文在真实的WidowX机械臂上进行了实验,结果表明,所提出的方法可以在12秒内完成任务,比行为克隆快10倍。这表明该方法在样本效率和任务完成时间方面都优于传统的模仿学习方法。实验结果充分验证了该方法的有效性和优越性。
🎯 应用场景
该研究成果可应用于各种机器人任务中,尤其是在专家示教受到限制的场景下,例如远程操作、医疗机器人、以及在复杂环境中进行操作的机器人。通过该方法,机器人可以学习到比人类专家更好的策略,从而提高任务的完成效率和质量。未来,该方法可以进一步扩展到多智能体协作、人机协作等领域。
📄 摘要(原文)
Learning from demonstrations enables experts to teach robots complex tasks using interfaces such as kinesthetic teaching, joystick control, and sim-to-real transfer. However, these interfaces often constrain the expert's ability to demonstrate optimal behavior due to indirect control, setup restrictions, and hardware safety. For example, a joystick can move a robotic arm only in a 2D plane, even though the robot operates in a higher-dimensional space. As a result, the demonstrations collected by constrained experts lead to suboptimal performance of the learned policies. This raises a key question: Can a robot learn a better policy than the one demonstrated by a constrained expert? We address this by allowing the agent to go beyond direct imitation of expert actions and explore shorter and more efficient trajectories. We use the demonstrations to infer a state-only reward signal that measures task progress, and self-label reward for unknown states using temporal interpolation. Our approach outperforms common imitation learning in both sample efficiency and task completion time. On a real WidowX robotic arm, it completes the task in 12 seconds, 10x faster than behavioral cloning, as shown in real-robot videos on https://sites.google.com/view/constrainedexpert .