iMoWM: Taming Interactive Multi-Modal World Model for Robotic Manipulation
作者: Chuanrui Zhang, Zhengxian Wu, Guanxing Lu, Yansong Tang, Ziwei Wang
分类: cs.RO
发布日期: 2025-10-10
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出iMoWM,利用交互式多模态世界模型提升机器人操作性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 世界模型 多模态学习 深度学习 强化学习
📋 核心要点
- 现有2D视频世界模型缺乏几何和空间推理能力,难以有效模拟3D物理世界,限制了机器人操作的性能。
- iMoWM通过自回归生成彩色图像、深度图和机器人手臂掩码,并引入MMTokenizer降低多模态数据计算成本。
- 实验表明,iMoWM提高了预测视觉质量,并有效支持基于模型的强化学习和模仿学习,提升了机器人操作性能。
📝 摘要(中文)
本文提出了一种名为iMoWM的交互式世界模型,旨在提升机器人操作性能。现有基于2D视频的世界模型缺乏几何和空间推理能力,难以捕捉3D世界的物理结构。iMoWM通过自回归的方式生成彩色图像、深度图和机器人手臂掩码,并以动作为条件。为了克服三维信息带来的高计算成本,论文提出了MMTokenizer,将多模态输入统一为紧凑的token表示。iMoWM利用大规模预训练的VideoGPT模型,在保持高效率的同时,融入更丰富的物理信息。凭借其多模态表示,iMoWM不仅提高了未来预测的视觉质量,而且可以作为基于模型的强化学习(MBRL)的有效模拟器,并促进真实世界的模仿学习。大量实验表明,iMoWM在这些任务中表现出色,展示了多模态世界模型在机器人操作中的优势。
🔬 方法详解
问题定义:现有基于视频的世界模型在机器人操作中面临挑战,主要原因是它们难以捕捉3D世界的几何和空间信息。这些模型通常只处理2D图像,缺乏对深度信息的理解,导致在复杂操作任务中预测精度不足,难以有效指导机器人行为。因此,如何构建一个能够理解和预测多模态信息的3D世界模型,成为提升机器人操作性能的关键问题。
核心思路:iMoWM的核心思路是利用多模态信息(彩色图像、深度图、机器人手臂掩码)来增强世界模型的表达能力,并采用token化的方法来降低计算复杂度。通过自回归的方式预测未来状态,模型能够学习到环境的动态变化和机器人行为的影响。这种设计使得模型能够更好地理解3D场景,并做出更准确的预测。
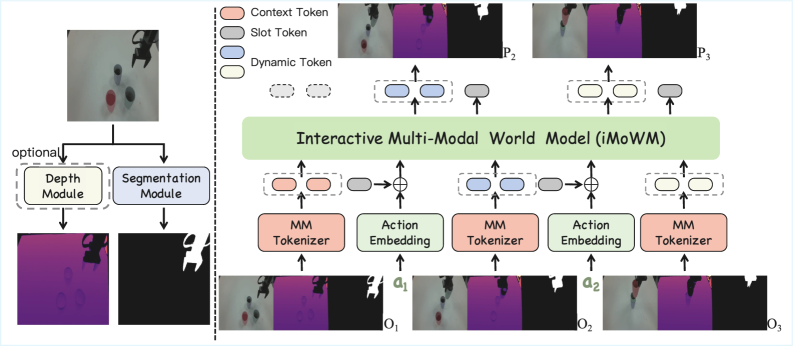
技术框架:iMoWM的整体框架包括以下几个主要模块:1) 多模态输入编码器:将彩色图像、深度图和机器人手臂掩码编码为特征向量。2) MMTokenizer:将多模态特征向量统一为紧凑的token表示,降低计算成本。3) 自回归预测器:基于token化的状态表示和动作指令,预测未来的多模态状态。4) 解码器:将预测的token表示解码为彩色图像、深度图和机器人手臂掩码。整个流程以自回归的方式进行,即利用当前状态和动作预测下一状态,并将预测结果反馈到模型中,以进行后续的预测。
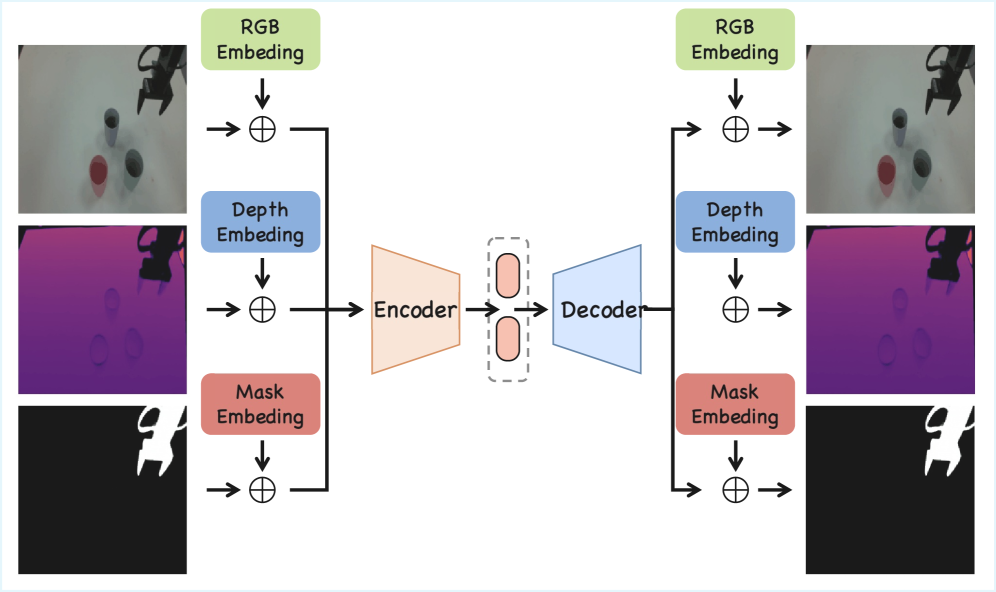
关键创新:iMoWM的关键创新在于MMTokenizer的设计,它能够有效地将多模态信息压缩为紧凑的token表示,从而降低计算复杂度,并使得模型能够利用大规模预训练的VideoGPT模型。此外,iMoWM的多模态表示方式也使得模型能够更好地理解3D场景,并做出更准确的预测。
关键设计:MMTokenizer的具体实现细节包括:首先,使用独立的编码器将彩色图像、深度图和机器人手臂掩码编码为特征向量。然后,使用一个共享的Transformer网络将这些特征向量融合,并将其量化为离散的token表示。自回归预测器采用Transformer架构,并使用交叉熵损失函数进行训练。在训练过程中,模型同时预测彩色图像、深度图和机器人手臂掩码,并使用加权损失函数来平衡不同模态之间的贡献。
🖼️ 关键图片

📊 实验亮点
实验结果表明,iMoWM在预测视觉质量方面优于现有方法,能够生成更清晰、更真实的彩色图像和深度图。在基于模型的强化学习任务中,iMoWM能够显著提高机器人的学习效率和最终性能。例如,在抓取任务中,iMoWM能够使机器人更快地学会抓取物体,并达到更高的成功率。此外,iMoWM在模仿学习任务中也表现出色,能够使机器人更好地模仿人类的操作行为。
🎯 应用场景
iMoWM在机器人操作领域具有广泛的应用前景,可用于开发更智能、更自主的机器人系统。例如,可以应用于工业自动化、家庭服务、医疗辅助等领域。通过模拟真实世界的交互,iMoWM能够帮助机器人更好地理解环境,并做出更合理的决策,从而提高工作效率和安全性。此外,iMoWM还可以用于机器人技能学习和任务规划,加速机器人技术的普及和应用。
📄 摘要(原文)
Learned world models hold significant potential for robotic manipulation, as they can serve as simulator for real-world interactions. While extensive progress has been made in 2D video-based world models, these approaches often lack geometric and spatial reasoning, which is essential for capturing the physical structure of the 3D world. To address this limitation, we introduce iMoWM, a novel interactive world model designed to generate color images, depth maps, and robot arm masks in an autoregressive manner conditioned on actions. To overcome the high computational cost associated with three-dimensional information, we propose MMTokenizer, which unifies multi-modal inputs into a compact token representation. This design enables iMoWM to leverage large-scale pretrained VideoGPT models while maintaining high efficiency and incorporating richer physical information. With its multi-modal representation, iMoWM not only improves the visual quality of future predictions but also serves as an effective simulator for model-based reinforcement learning (MBRL) and facilitates real-world imitation learning. Extensive experiments demonstrate the superiority of iMoWM across these tasks, showcasing the advantages of multi-modal world modeling for robotic manipulation. Homepage: https://xingyoujun.github.io/imowm/