Model-Based Lookahead Reinforcement Learning for in-hand manipulation
作者: Alexandre Lopes, Catarina Barata, Plinio Moreno
分类: cs.RO
发布日期: 2025-10-10 (更新: 2025-12-11)
💡 一句话要点
提出基于模型的Lookahead强化学习方法,提升灵巧手部操作性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 灵巧手部操作 强化学习 模型预测控制 混合学习 机器人控制
📋 核心要点
- 灵巧手部操作面临复杂动力学和控制挑战,现有方法难以兼顾效率与精度。
- 提出一种混合强化学习框架,结合免模型和基于模型的优势,利用动态模型引导策略学习。
- 实验表明,该方法在多种手部和物体操作任务中,提升了性能,并具备一定的泛化能力。
📝 摘要(中文)
灵巧手部操作是一项极具挑战性的机器人任务,它结合了复杂的动力学系统以及利用执行器控制和操纵物体的能力。本文将先前开发的混合强化学习(RL)框架应用于手部操作任务,验证了其能够提高任务性能。该模型结合了免模型和基于模型的强化学习概念,通过动态模型和价值函数引导训练好的策略进行轨迹评估,类似于模型预测控制。本文通过将该模型与被引导的策略进行比较来评估其性能。为了充分探索这一点,使用完全驱动和欠驱动的模拟机械手进行各种测试,以操纵不同的物体来完成给定的任务。该模型还在泛化测试中进行了测试,通过改变物体属性(如密度和大小)以及引导在特定物体上训练的策略在不同的物体上执行相同的任务。结果表明,给定一个具有高平均奖励的策略和一个准确的动态模型,该混合框架可以提高大多数测试用例中手部操作任务的性能,即使在物体属性发生变化时也是如此。然而,这种改进是以增加计算成本为代价的,因为轨迹评估的复杂性。
🔬 方法详解
问题定义:灵巧手部操作需要精确控制机械手与物体的交互,现有方法如纯免模型强化学习,样本效率低,训练时间长;而纯基于模型的方法,模型精度受限,难以处理复杂动力学。因此,如何在保证学习效率的同时,提高控制精度和泛化能力,是本文要解决的问题。
核心思路:本文的核心思路是将免模型强化学习训练得到的策略,与基于模型的预测控制相结合。免模型RL负责提供一个初步的策略,而基于模型的预测控制则利用动态模型对该策略进行优化,从而提高控制精度和鲁棒性。这种混合方法旨在结合两者的优点,克服各自的缺点。
技术框架:该框架包含两个主要部分:1)免模型强化学习策略训练:使用某种RL算法(具体算法未知)训练一个初始策略,该策略能够初步完成手部操作任务。2)基于模型的轨迹优化:利用动态模型,对初始策略生成的轨迹进行评估和优化。具体来说,在每个时间步,利用动态模型预测未来一段时间内的状态,并计算相应的奖励。然后,通过调整控制输入,使得预测的轨迹能够获得更高的奖励。
关键创新:该方法的核心创新在于将免模型RL和基于模型的预测控制相结合,形成一个混合的强化学习框架。与传统的免模型RL相比,该方法利用动态模型进行轨迹优化,提高了控制精度和鲁棒性。与传统的基于模型的预测控制相比,该方法利用免模型RL提供一个良好的初始策略,降低了对模型精度的要求。
关键设计:论文中未明确给出关键参数设置、损失函数和网络结构等技术细节。动态模型的具体形式未知,但需要能够较为准确地预测手部和物体的运动。轨迹优化的具体算法未知,但需要能够高效地搜索最优的控制输入序列。奖励函数的设计至关重要,需要能够引导策略学习到期望的行为。
🖼️ 关键图片

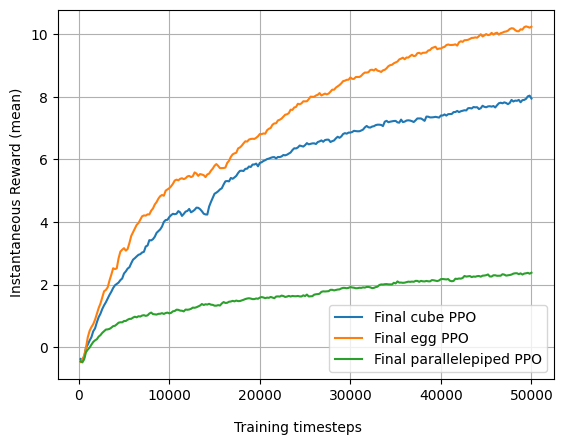

📊 实验亮点
实验结果表明,该混合框架在大多数测试用例中,能够提高手部操作任务的性能,即使在物体属性发生变化时也是如此。具体性能提升幅度未知,但论文强调,该方法在给定一个具有高平均奖励的策略和一个准确的动态模型的前提下,能够有效提升性能。然而,这种性能提升是以增加计算成本为代价的。
🎯 应用场景
该研究成果可应用于各种需要灵巧手部操作的机器人任务,例如:工业自动化中的零件装配、医疗手术中的微创操作、以及家庭服务机器人中的物品整理等。通过提高手部操作的精度和鲁棒性,可以显著提升机器人的工作效率和适应性,使其能够更好地服务于人类。
📄 摘要(原文)
In-Hand Manipulation, as many other dexterous tasks, remains a difficult challenge in robotics by combining complex dynamic systems with the capability to control and manoeuvre various objects using its actuators. This work presents the application of a previously developed hybrid Reinforcement Learning (RL) Framework to In-Hand Manipulation task, verifying that it is capable of improving the performance of the task. The model combines concepts of both Model-Free and Model-Based Reinforcement Learning, by guiding a trained policy with the help of a dynamic model and value-function through trajectory evaluation, as done in Model Predictive Control. This work evaluates the performance of the model by comparing it with the policy that will be guided. To fully explore this, various tests are performed using both fully-actuated and under-actuated simulated robotic hands to manipulate different objects for a given task. The performance of the model will also be tested for generalization tests, by changing the properties of the objects in which both the policy and dynamic model were trained, such as density and size, and additionally by guiding a trained policy in a certain object to perform the same task in a different one. The results of this work show that, given a policy with high average reward and an accurate dynamic model, the hybrid framework improves the performance of in-hand manipulation tasks for most test cases, even when the object properties are changed. However, this improvement comes at the expense of increasing the computational cost, due to the complexity of trajectory evaluation.