R2RGEN: Real-to-Real 3D Data Generation for Spatially Generalized Manipulation
作者: Xiuwei Xu, Angyuan Ma, Hankun Li, Bingyao Yu, Zheng Zhu, Jie Zhou, Jiwen Lu
分类: cs.RO, cs.CV
发布日期: 2025-10-09
备注: Project page: https://r2rgen.github.io/
💡 一句话要点
提出R2RGen,用于生成真实3D数据,提升机器人空间泛化操作能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 空间泛化 数据生成 点云处理 模仿学习
📋 核心要点
- 现有方法在机器人操作的空间泛化方面面临挑战,主要问题是模拟到真实的差距和受限的场景设置。
- R2RGen通过直接增强真实世界的点云数据,避免了模拟器和渲染,从而高效地生成空间多样性的训练数据。
- 实验结果表明,R2RGen显著提高了数据效率,并具备在移动操作中扩展和应用的潜力。
📝 摘要(中文)
为了实现机器人操作的泛化能力,空间泛化是最基本的要求,它要求策略在不同的物体空间分布、环境和机器人自身配置下都能稳健地工作。为了实现这一点,需要收集大量的人工示教数据,以覆盖不同的空间配置,从而通过模仿学习训练一个通用的视觉运动策略。先前的工作探索了一个有希望的方向,即利用数据生成从最少的源示教数据中获取丰富的空间多样性数据。然而,大多数方法面临着显著的模拟到真实世界的差距,并且通常仅限于受约束的设置,例如固定基座场景和预定义的相机视角。在本文中,我们提出了一个真实到真实的3D数据生成框架(R2RGen),该框架直接增强点云观测-动作对以生成真实世界数据。R2RGen无需模拟器和渲染,因此高效且即插即用。具体来说,给定单个源示教数据,我们引入了一种注释机制,用于对场景和轨迹进行细粒度解析。提出了一种分组增强策略,以处理复杂的多对象组合和不同的任务约束。我们进一步提出了相机感知处理,以使生成数据的分布与真实世界3D传感器对齐。经验表明,R2RGen在广泛的实验中显着提高了数据效率,并展示了在移动操作中进行扩展和应用的强大潜力。
🔬 方法详解
问题定义:现有机器人操作方法在空间泛化能力上存在不足,主要体现在对不同空间分布的物体、环境和机器人自身配置的适应性较差。现有方法依赖大量人工标注数据或存在模拟到真实世界的差距,限制了其在真实场景中的应用。
核心思路:R2RGen的核心思路是通过直接在真实数据上进行增强,避免了模拟器带来的误差。通过对单个示教数据进行细粒度解析和分组增强,生成具有空间多样性的训练数据,从而提高策略的空间泛化能力。
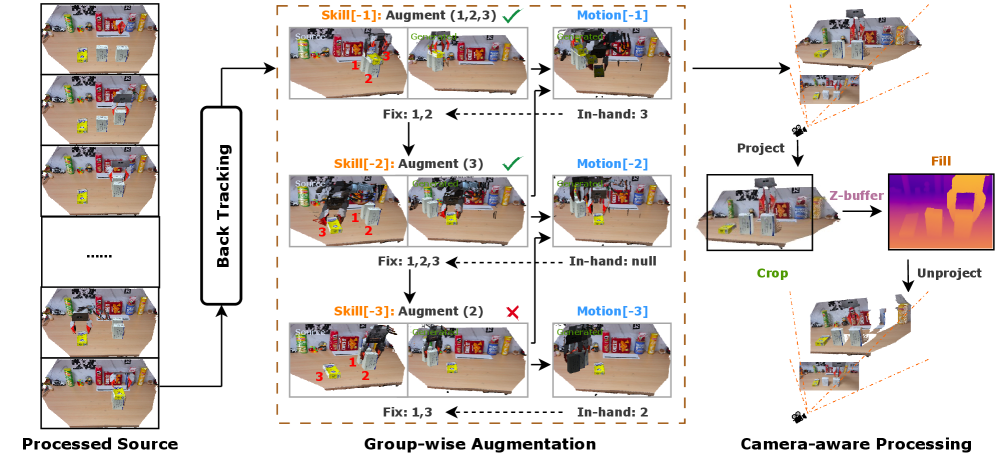
技术框架:R2RGen框架主要包含以下几个阶段:1) 场景和轨迹的细粒度解析,通过注释机制对源示教数据进行解析;2) 分组增强策略,处理复杂的多对象组合和任务约束;3) 相机感知处理,对生成的数据进行处理,使其分布与真实世界3D传感器对齐。整个流程无需模拟器和渲染。
关键创新:R2RGen的关键创新在于其真实到真实的数据生成方式,避免了模拟到真实的转换,从而减少了误差。此外,分组增强策略和相机感知处理也是重要的创新点,它们使得生成的数据更具多样性和真实性。
关键设计:细粒度解析的注释机制的具体实现细节未知。分组增强策略的具体分组方式和增强方法未知。相机感知处理的具体算法和参数设置未知。损失函数和网络结构等信息在摘要中未提及,因此未知。
🖼️ 关键图片


📊 实验亮点
摘要中提到R2RGen在实验中显著提高了数据效率,但没有提供具体的性能数据和对比基线。实验结果表明R2RGen具有在移动操作中进行扩展和应用的强大潜力,但具体的提升幅度未知。
🎯 应用场景
R2RGen在机器人操作领域具有广泛的应用前景,尤其是在需要空间泛化能力的场景中,例如移动机器人操作、家庭服务机器人、工业自动化等。该方法可以减少对大量人工标注数据的依赖,降低训练成本,并提高机器人在复杂环境中的适应性。未来,R2RGen有望推动机器人操作技术的进一步发展。
📄 摘要(原文)
Towards the aim of generalized robotic manipulation, spatial generalization is the most fundamental capability that requires the policy to work robustly under different spatial distribution of objects, environment and agent itself. To achieve this, substantial human demonstrations need to be collected to cover different spatial configurations for training a generalized visuomotor policy via imitation learning. Prior works explore a promising direction that leverages data generation to acquire abundant spatially diverse data from minimal source demonstrations. However, most approaches face significant sim-to-real gap and are often limited to constrained settings, such as fixed-base scenarios and predefined camera viewpoints. In this paper, we propose a real-to-real 3D data generation framework (R2RGen) that directly augments the pointcloud observation-action pairs to generate real-world data. R2RGen is simulator- and rendering-free, thus being efficient and plug-and-play. Specifically, given a single source demonstration, we introduce an annotation mechanism for fine-grained parsing of scene and trajectory. A group-wise augmentation strategy is proposed to handle complex multi-object compositions and diverse task constraints. We further present camera-aware processing to align the distribution of generated data with real-world 3D sensor. Empirically, R2RGen substantially enhances data efficiency on extensive experiments and demonstrates strong potential for scaling and application on mobile manipulation.