DexMan: Learning Bimanual Dexterous Manipulation from Human and Generated Videos
作者: Jhen Hsieh, Kuan-Hsun Tu, Kuo-Han Hung, Tsung-Wei Ke
分类: cs.RO, cs.CV, cs.LG
发布日期: 2025-10-09
备注: Video results are available at: https://embodiedai-ntu.github.io/dexman/index.html
💡 一句话要点
DexMan:从人类和生成视频中学习双手动灵巧操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 灵巧操作 机器人学习 强化学习 视觉伺服 姿态估计
📋 核心要点
- 现有方法在机器人灵巧操作学习中依赖于精确的标注和复杂的硬件设置,限制了数据获取和泛化能力。
- DexMan通过直接从人类操作视频中学习,结合接触奖励,实现了在仿真环境中对人形机器人的灵巧操作控制。
- 实验表明,DexMan在物体姿态估计和操作成功率上均超越了现有方法,并能利用合成数据扩展训练集。
📝 摘要(中文)
DexMan是一个自动化框架,可以将人类视觉演示转换为人形机器人在仿真环境中的双手动灵巧操作技能。它直接处理人类操纵刚性物体的第三人称视频,无需相机校准、深度传感器、扫描的3D物体资产或真实的手部和物体运动标注。与之前仅考虑简化浮动手的方法不同,DexMan直接控制人形机器人,并利用基于接触的新型奖励来改进从嘈杂的手部-物体姿势(从真实视频中估计)中进行策略学习。DexMan在TACO基准测试中实现了最先进的物体姿势估计性能,ADD-S和VSD分别绝对提升了0.08和0.12。同时,其强化学习策略在OakInk-v2上的成功率超过了以前的方法19%。此外,DexMan可以从真实和合成视频中生成技能,无需手动数据收集和昂贵的运动捕捉,从而能够创建大规模、多样化的数据集,用于训练通用灵巧操作。
🔬 方法详解
问题定义:现有机器人灵巧操作学习方法通常需要精确的相机标定、深度传感器、物体3D模型以及手部和物体运动的ground truth标注。这些需求限制了数据获取的规模和多样性,使得训练出的策略难以泛化到真实世界。此外,一些方法简化了手部模型,忽略了与环境的接触,导致策略在复杂操作中表现不佳。
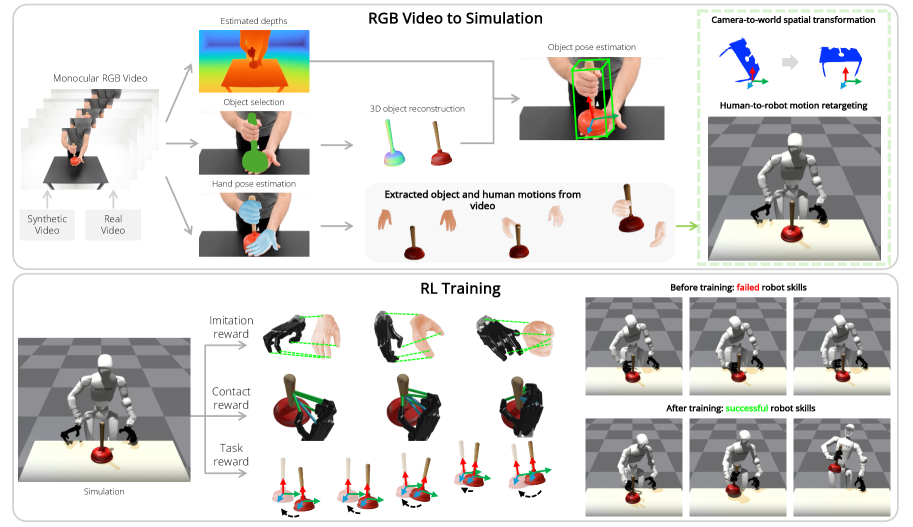
核心思路:DexMan的核心思路是从人类操作视频中直接学习,避免对精确标注和复杂硬件的依赖。通过估计视频中的手部和物体姿态,并结合基于接触的奖励函数,训练人形机器人在仿真环境中执行类似的操作。这种方法利用了人类演示的丰富信息,并允许使用合成数据进行扩展,从而提高策略的泛化能力。
技术框架:DexMan的整体框架包括以下几个主要模块:1) 视频数据处理:从人类操作视频中估计手部和物体的姿态。2) 奖励函数设计:设计基于接触的奖励函数,鼓励机器人与物体进行有效的交互。3) 强化学习策略训练:使用强化学习算法,在仿真环境中训练人形机器人的操作策略。4) 合成数据生成:利用合成视频数据,扩展训练集,提高策略的泛化能力。
关键创新:DexMan的关键创新在于:1) 直接从视频学习:无需精确标注和复杂硬件,降低了数据获取的成本。2) 基于接触的奖励函数:鼓励机器人与物体进行有效的交互,提高了操作的成功率。3) 合成数据增强:利用合成视频数据,扩展训练集,提高了策略的泛化能力。
关键设计:DexMan使用了一种基于视觉的姿态估计方法,从视频中估计手部和物体的姿态。奖励函数的设计考虑了机器人与物体的接触力、相对位置和姿态等因素。强化学习算法使用了PPO(Proximal Policy Optimization)算法,并对奖励函数进行了调整,以提高训练的稳定性和效率。合成数据的生成使用了Blender等3D建模软件,并对光照、纹理和背景进行了随机化,以提高合成数据的真实感。
🖼️ 关键图片


📊 实验亮点
DexMan在TACO基准测试中,物体姿态估计的ADD-S指标提升了0.08,VSD指标提升了0.12,达到了state-of-the-art水平。在OakInk-v2操作任务中,DexMan的强化学习策略成功率比之前的方法提高了19%。这些结果表明,DexMan在物体姿态估计和灵巧操作方面具有显著的优势。
🎯 应用场景
DexMan具有广泛的应用前景,例如在智能制造领域,可以用于训练机器人执行精细的装配和操作任务。在家庭服务领域,可以用于训练机器人执行日常的家务劳动,如物品整理和清洁。此外,该技术还可以应用于医疗康复领域,帮助患者进行手部功能的恢复训练。DexMan通过降低数据获取成本和提高策略泛化能力,为机器人灵巧操作的普及奠定了基础。
📄 摘要(原文)
We present DexMan, an automated framework that converts human visual demonstrations into bimanual dexterous manipulation skills for humanoid robots in simulation. Operating directly on third-person videos of humans manipulating rigid objects, DexMan eliminates the need for camera calibration, depth sensors, scanned 3D object assets, or ground-truth hand and object motion annotations. Unlike prior approaches that consider only simplified floating hands, it directly controls a humanoid robot and leverages novel contact-based rewards to improve policy learning from noisy hand-object poses estimated from in-the-wild videos. DexMan achieves state-of-the-art performance in object pose estimation on the TACO benchmark, with absolute gains of 0.08 and 0.12 in ADD-S and VSD. Meanwhile, its reinforcement learning policy surpasses previous methods by 19% in success rate on OakInk-v2. Furthermore, DexMan can generate skills from both real and synthetic videos, without the need for manual data collection and costly motion capture, and enabling the creation of large-scale, diverse datasets for training generalist dexterous manipulation.